
经过《转录组测序到底在做什么(一)》的介绍,我们已经完成前期分析,拿到了clean data,下面请跟随小微,进入到转录组测序真正的核心分析内容。

核心分析
在获得clean data后,我们需要将得到的clean data回贴(mapping)到参考基因组或参考转录组上(有参转录组)。在这个步骤中,回贴的比例(mapping rate)就显得至关重要。如对于人的转录组,一般期望回贴到参考基因组上的比例能达到70%-90%。而回帖到参考转录组时,这个比例会略低,因为数据中未注释的转录本无法进行回贴。另外,覆盖度也十分重要。例如在回贴中发现转录本的5’端覆盖度较低而3’端覆盖度较高,则表示样本质量较差,发生了一定的降解。而对于没有参考基因组、参考转录组(无参转录组)或参考基因组及转录组不完整的样本,则需要对得到的数据进行从头拼接,组装出转录组序列。(图2)对于有参转录组在进行回贴分析后,还可对参考转录组中未注释的新的转录本进行鉴定与分析。也可以对转录本的变异进行分析,如对SNP位点的分析、InDel分析、不同类型的可变剪切的分析等。还可基于mapping的结果进行融合基因的分析。
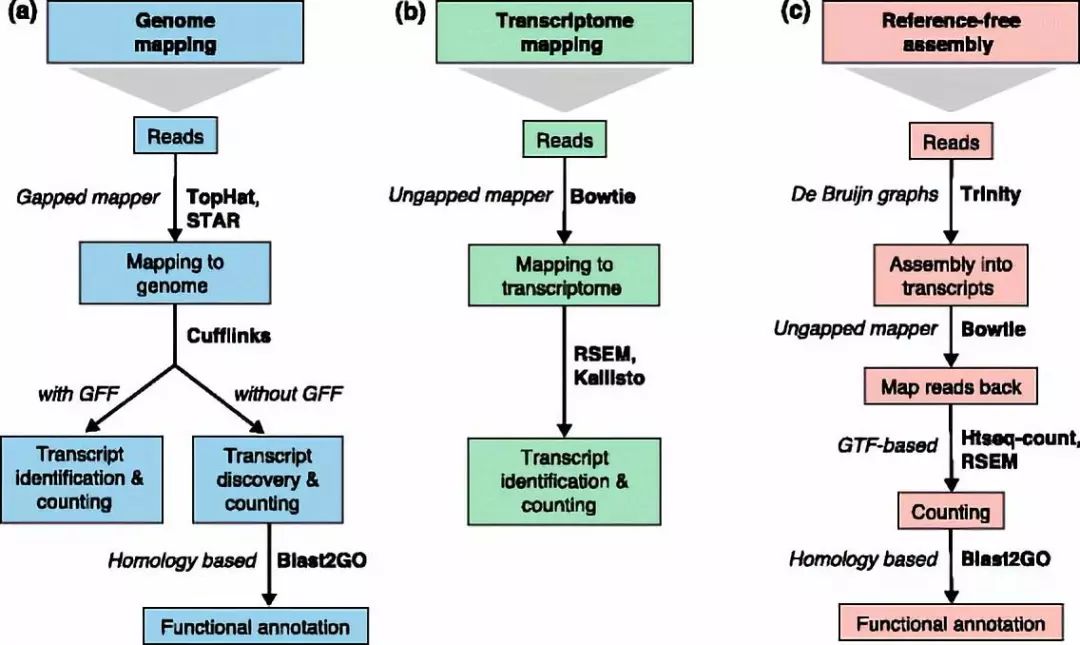
图二
完成回贴、组装、新转录本预测、变异分析、融合基因等的分析后,就进入到转录组最核心的部分,即转录本的表达定量和差异表达分析。转录本的表达定量,即对各转录本测到的reads数进行转录本长度、测序深度等因素的均一化后进行的表达量评估。在双端测序中常使用FPKM(fragments per kilobase of exon model per million mapped reads)这一指标来衡量,即每1百万个fragments中map到外显子的每1K个碱基上的reads个数,其中的fragment指在双端测序中由插入片段两端的一组reads所确定的一个片段(fragment)。而差异表达分析则是在转录本定量的基础上,为找出不同样本组中表达量发生显著差异的转录本,同时确定其表达量的变化的趋势及倍数所进行的分析。而通过样本间的相关性分析,可以判断生物学重复间的相似度,处理组与对照组之间的整体的基因表达差异大小。

功能分析也是转录组测序分析流程中的重要的一部分。通过对新基因、差异表达基因等的功能与可能参与的代谢通路进行推测,帮助研究人员分析样本的处理组和对照组间出现表型差异的可能的生化与分子生物学原因。

通过以上的这些分析,我们可以清晰的了解到不同样本间的各转录本的表达量差异,变异(SNP、InDel、可变剪接、融合基因等),以及这些差异转录本的功能及所在的代谢通路。为分析不同样本组间的表型差异的原因提供了丰富的数据。
高级分析
由于转录本是基因表达调控中极为关键的一个环节,因此转录组不仅可以作为独立的分析内容,也可以与其他的组学相互联用进行更深层次的研究。如可与DNA甲基化数据联用,进一步分析DNA甲基化与基因表达间的关系,从基因表达调控的角度进行如疾病的发病原理等的应用。而与CHIP-seq数据的联用,则可以探索组蛋白修饰与基因表达的关系。与其他ncRNA的联合分析,如sRNA、lncRNA、circRNA等的功能探索,基因表达调控通路的研究等。而普通转录组自身也在向单细胞转录组、全长转录组等方向拓展和进化,在研究工作中势必起到越来越大的作用。

通过这一轮的回顾,大家应该对转录组测序有了一个更加全面的认识,那就不要浪费了这个强大的工具,赶紧应用到你的研究中来吧!
参考文献
1、Conesa A, Madrigal P, Tarazona S, et al. A survey of best practices for RNA-seq data analysis[J]. Genome biology, 2016, 17(1): 13.
2、Yalamanchili H K, Wan Y W, Liu Z. Data Analysis Pipeline for RNA‐seq Experiments: From Differential Expression to Cryptic Splicing[J]. Current protocols in bioinformatics, 2017,59(1): 11.15. 1-11.15. 21.
3、Lott S C, Wolfien M, Riege K, et al. Customized workflow development and data modularization concepts for RNA-Sequencing and metatranscriptome experiments[J]. Journal of biotechnology, 2017, 261: 85-96.
4、Miao Z, Han Z, Zhang T, et al. A systems approach to a spatio-temporal understanding of the drought stress response in maize[J]. Scientific reports, 2017, 7(1): 6590.
5、Roca C P, Gomes S I L, Amorim M J B, et al. Variation-preserving normalization unveils blind spots in gene expression profiling[J]. Scientific Reports, 2017, 7: 42460.
6、Lu Y, Ye Y, Bao W, et al. Genome-wide identification of genes essential for podocyte cytoskeletons based on single-cell RNA sequencing[J]. Kidney international, 2017, 92(5): 1119-1129.
7、Bush S J, McCulloch M E B, Summers K M, et al. Integration of quantitated expression estimates from polyA-selected and rRNA-depleted RNA-seq libraries[J]. BMC bioinformatics, 2017, 18(1): 301.
8、Paulson J N, Chen C Y, Lopes-Ramos C M, et al. Tissue-aware RNA-Seq processing and normalization for heterogeneous and sparse data[J]. BMC bioinformatics, 2017, 18(1): 437.
微分基因为国家大基因中心“基因检测平台”运营方,专注于高通量测序技术,公司凭借国际领先的高通量测序平台,依托独具优势的高通量基因测序和大数据挖掘技术,为各大高校、医院、科研单位以及第三方健康管理服务平台,提供专业的基因检测和数据分析解读服务。2017年,微分基因在国家大基因中心建成2133平方米的洁净分子生物实验室,公司科研团队汇聚了一批国内外优秀的基因组学实验和生物信息分析研究人员。

科技服务部依托公司先进的自动化建库仪、高通量测序仪等实验设备,提供多种测序服务;凭借强大的科研团队,为高校、科研院所等研究单位提供领先的生物信息分析服务。主营业务包括DNA测序、RNA测序、表观组学测序、单细胞测序、ICELL8单细胞表达谱测序、芯片服务、三代全长转录组测序等。
健康|医疗|基因|科普
微分基因科技服务