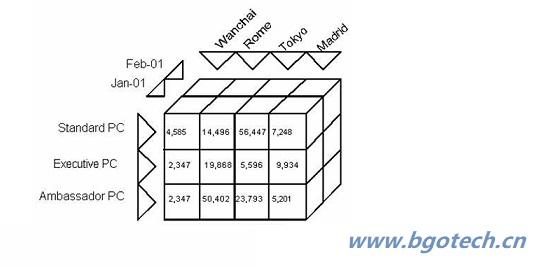
Cyrex Cube是邦格科技自主研发的多维数据库,与传统的基于星型或雪花型结构的传统OLAP架构相比,Cyrex Cube分析模型更加面向业务,同时也具备更强的多维数据分析能力。

Cyrex Cube的逻辑与聚合分离、双向可扩展分布式、简单化处理以及常驻内存模型等特点使其可以在无缓存情况下实现百亿级数据实时聚合运算的秒级响应。
1、逻辑运算和聚合运算的分离
先以关系型数据库为例,模拟两种数据分析情况。第一,数据库中的表结构非常复杂,各个表之间的关联关系也很复杂,但是每个表中的数据量非常少,
这时候,在这种情况下进行数据分析,可以进行非常复杂的逻辑查询,但由于数据量很少,并不会导致效率的降低,所以不太关心性能问题。
第二,关系型数据库中的表结构非常简单,逻辑也不复杂,但是表中的数据量非常大,这时候可以针对几种常用的简单查询做一些通用的优化,解决性能问题后,同样也可以支持上层应用的数据分析需求。
但在某些情况下,如表结构逻辑非常复杂同时数据量很大的情况下,使用传统的OLAP结构,查询效率将会大大降低,对于某些查询则可能是无法实现的(如多个上亿级别事实表的关联查询)。
我们把上述中针对复杂表结构的查询称为逻辑运算,把针对海量数据的查询称为聚合运算。
Cyrex Cube的设计理念就是将逻辑运算和聚合运算彻底解耦,使二者完全互不相干,让Cyrex Cube能够支持海量数据下的复杂逻辑分析能力。
2、简单化处理
基于越简单越稳定可靠的通用原理,Cyrex Cube底层技术采用了更加简单的结构与算法。
众所周知,在传统或分布式关系型数据库中,查询记录的最快方式是基于主键,但是即使是主键,也会有哈希值的计算过程,针对粗粒度级汇总的计算,会产生大量的哈希计算过程,效率会大打折扣。
而Cyrex Cube采用类似直接寻址的方式进行聚合运算,在一片连续的内存中给出首尾地址,程序指针将遍历此范围内的所有值,并返回聚合结果,此种效率是传统OLAP无法比拟的。
3、基于C语言开发
Cyrex Cube底层有关数据存储与运算的逻辑基于C语言开发,C语言相较于Java、Python、Go、C#等高级语言更加贴近底层,效率更高,所以在单台服务器不配备缓存的情况下Cyrex Cube可以支持上亿级数据量的秒级运算响应。
4、可横向及纵向扩展的高可用分布式
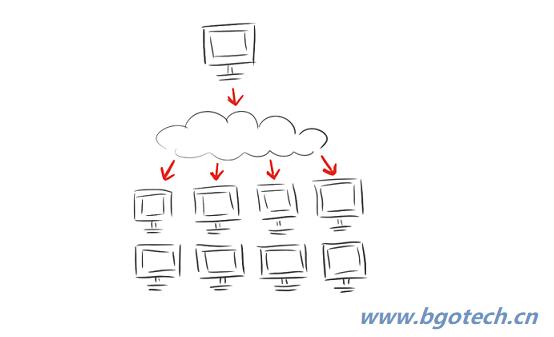
双向可扩展分布式。Cyrex Cube采用主(Master)从(Work)架构,当数据量不超过百亿时,只需采用该横向扩展即可。采用纵向扩展结构,则可支持千亿甚至万亿级别数据量的实时秒级响应。
而且,上述情况都是在无缓存支持的情况下完成的。
5、内存计算
Cyrex Cube采用常驻内存数据结构,存储效率极为高效,1G内存便可支持五千万至一亿数据量级的存储。
点赞 + 转发,然后关注并私信小编,可获得Cyrex Cube的更多信息。