
作者 | 狄东林 刘元兴 朱庆福 胡景雯
编辑 | 刘元兴,崔一鸣
来源 | 哈工大SCIR(ID:HIT_SCIR)
引言
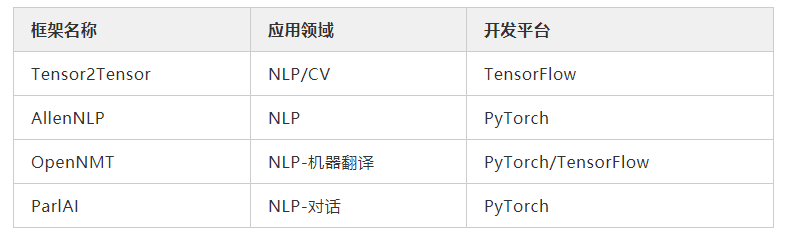
随着人工智能的发展,越来越多深度学习框架如雨后春笋般涌现,例如PyTorch、TensorFlow、Keras、MXNet、Theano 和 PaddlePaddle 等。这些基础框架提供了构建一个模型需要的基本通用工具包。但是对于 NLP 相关的任务,我们往往需要自己编写大量比较繁琐的代码,包括数据预处理和训练过程中的工具等。因此,大家通常基于 NLP 相关的深度学习框架编写自己的模型,如 OpenNMT、ParlAI 和 AllenNLP 等。借助这些框架,三两下就可以实现一个 NLP 相关基础任务的训练和预测。但是当我们需要对基础任务进行改动时,又被代码封装束缚,举步维艰。因此,本文主要针对于如何使用框架实现自定义模型,帮助大家快速了解框架的使用方法。
我们首先介绍广泛用于NLP/CV领域的TensorFlow框架——Tensor2Tensor,该框架提供了 NLP/CV 领域中常用的基本模型。然后介绍NLP 领域的 AllenNLP 框架,该框架基于 PyTorch 平台开发,为 NLP 模型提供了统一的开发架构。接着在介绍 NLP 领域中重要的两个子领域,神经机器翻译和对话系统常用的框架,OpenNMT 和 ParlAI 。通过这四个框架的介绍,希望能帮助大家了解不同开发平台,不同领域下的 NLP 框架的使用方式。

一、Tensor2Tensor

Tensor2Tensor[1] 是一个基于 TensorFlow 的较为综合性的库,既包括一些CV 和 NLP 的基本模型,如 LSTM,CNN等,也提供一些稍微高级一点的模型,如各式各样的 GAN 和 Transformer 。对 NLP 的各项任务支持得都比较全面,很方便容易上手。
由于该资源库仍处于不断开发过程中,截止目前为止,已经有 3897 次 commit,66 个 release 版本,178 contributors 。在 2018 年《Attention is all you need》这个全网热文中,该仓库是官方提供的 Transformer 模型版本,后面陆陆续续其余平台架构才逐渐补充完成。
Tensor2Tensor(Transformer)使用方法
注意:有可能随着版本迭代更新的过程中会有局部改动
安装环境
1. 安装 CUDA 9.0 (一定是9.0,不能是9.2)
2. 安装 TensorFlow (现在是1.12)
3. 安装 Tensor2Tensor (参考官网安装)
开始使用
1. 数据预处理
这一步骤是根据自己任务自己编写一些预处理的代码,比如字符串格式化,生成特征向量等操作。
2. 编写自定义 problem:
编写自定义的 problem 代码,一定需要在自定义类名前加装饰器(@registry.registry_problem)。
自定义 problem 的类名一定是驼峰式命名,py 文件名一定是下划线式命名,且与类名对应。
一定需要继承父类 problem,t2t 已经提供用于生成数据的 problem,需要自行将自己的问题人脑分类找到对应的父类,主要定义的父类 problem有:(运行 t2t-datagen 可以查看到 problem list )。
一定需要在__init__.py文件里导入自定义problem文件。
3. 使用 t2t-datagen 将自己预处理后的数据转为 t2t 的格式化数据集【注意路径】
运行 t2t-datagen --help 或 t2t-datagen --helpfull。例如:
cd scripts && t2t-datagen --t2t_usr_dir=./ --data_dir=../train_data --tmp_dir=../tmp_data --problem=my_problem
如果自定义 problem 代码的输出格式不正确,则此命令会报错
4. 使用 t2t-trainer 使用格式化的数据集进行训练
运行 t2t-trainer --help 或 t2t-trainer --helpfull 。例如:
1cd scripts && t2t-datagen --t2t_usr_dir=./ --data_dir=../train_data --tmp_dir=../tmp_data --problem=my_problem
5. 使用 t2t-decoder 对测试集进行预测【注意路径】
如果想使用某一个 checkpoint 时的结果时,需要将 checkpoint 文件中的第一行: model_checkpoint_path: “model.ckpt-xxxx” 的最后的序号修改即可。例如:
cd scripts && t2t-decoder --t2t_usr_dir=./ --problem=my_problem --data_dir=../train_data --model=transformer --hparams_set=transformer_base --output_dir=../output --decode_hparams=”beam_size=5,alpha=0.6” --decode_from_file=../decode_in/test_in.txt --decode_to_file=../decode_out/test_out.txt
6. 使用 t2t-exporter 导出训练模型
7. 分析结果
附: (整体代码)
# coding=utf-8from tensor2tensor.utils import registryfrom tensor2tensor.data_generators import problem, text_problems@registry.register_problemclass AttentionGruFeature(text_problems.Text2ClassProblem):ROOT_DATA_PATH = '../data_manager/'PROBLEM_NAME = 'attention_gru_feature'
@property
def is_generate_per_split(self):
return True
@property
def dataset_splits(self):
return [{
"split": problem.DatasetSplit.TRAIN,
"shards": 5,
}, {
"split": problem.DatasetSplit.EVAL,
"shards": 1,
}]
@property
def approx_vocab_size(self):
return 2 ** 10 # 8k vocab suffices for this small dataset.
@property
def num_classes(self):
return 2
@property
def vocab_filename(self):
return self.PROBLEM_NAME + ".vocab.%d" % self.approx_vocab_size
def generate_samples(self, data_dir, tmp_dir, dataset_split):
del data_dir
del tmp_dir
del dataset_split
# with open('{}self_antecedent_generate_sentences.pkl'.format(self.ROOT_DATA_PATH), 'rb') as f:
# # get all the sentences for antecedent identification
# _sentences = pickle.load(f)
#
# for _sent in _sentences:
# # # sum pooling, FloatTensor, Size: 400
# # _sent.input_vec_sum
# # # sum pooling with feature, FloatTensor, Size: 468
# # _sent.input_vec_sum_feature
# # # GRU, FloatTensor, Size: 6100
# # _sent.input_vec_hidden
# # # GRU with feature, FloatTensor, Size: 6168
# # _sent.input_vec_hidden_feature
# # # AttentionGRU, FloatTensor, Size: 1600
# # _sent.input_vec_attention
# # # AttentionGRU with feature, FloatTensor, Size: 1668
# # _sent.input_vec_attention_feature
# # # tag(1 for positive case, and 0 for negative case), Int, Size: 1
# # _sent.antecedent_label
# # # tag(1 for positive case, and 0 for negative case), Int, Size: 1
# # _sent.trigger_label
# # # trigger word for the error analysis, Str
# # _sent.trigger
# # # trigger word auxiliary type for the experiment, Str
# # _sent.aux_type
# # # the original sentence for the error analysis, Str
# # _sent.sen
#
# yield {
# "inputs": _sent.input_vec_attention_feature,
# "label": _sent.antecedent_label
# }
with open('../prep_ante_data/antecedent_label.txt') as antecedent_label, open(
'../prep_ante_data/input_vec_attention_gru_feature.txt') as input_vec:
for labal in antecedent_label:
yield {
"inputs": input_vec.readline().strip()[1:-2],
"label": int(labal.strip())
}
antecedent_label.close()
input_vec.close()
# PROBLEM_NAME='attention_gru_feature'
# DATA_DIR='../train_data_atte_feature'
# OUTPUT_DIR='../output_atte_feature'
# t2t-datagen --t2t_usr_dir=. --data_dir=$DATA_DIR --tmp_dir=../tmp_data --problem=$PROBLEM_NAME
# t2t-trainer --t2t_usr_dir=. --data_dir=$DATA_DIR --problem=$PROBLEM_NAME --model=transformer --hparams_set=transformer_base --output_dir=$OUTPUT_DIR
Tensor2Tensor使用总结
T2T 是Google 非官方提供的仓库,是社区广大爱好者共同努力建设的简单入门型框架,底层封装TF,能满足大部分CV 和 NLP的任务,很多主流成熟的模型也已经都有实现。直接继承或实现一些框架内预设的接口,就可以完成很多任务。入门起来非常友好,并且文档更新也较为及时。认真阅读文档(或阅读报错信息)就可以了解并使用该框架,方便许多非大幅创新模型的复现。
二、AllenNLP

AllenNLP 是一个基于 PyTorch 的NLP 研究库,可为开发者提供语言任务中的各种业内最佳训练模型。官网提供了一个很好的入门教程[2],能够让初学者在 30 分钟内就了解 AllenNLP 的使用方法。
AllenNLP 使用方法
由于 AllenNLP 已经帮我们实现很多麻烦琐碎的预处理和训练框架,我们实际需要编写的只有:
1. DatasetReader
DatasetReader 的示例代码如下所示。
from typing import Dict, Iteratorfrom allennlp.data import Instancefrom allennlp.data.fields import TextFieldfrom allennlp.data.dataset_readers import DatasetReaderfrom allennlp.data.token_indexers import TokenIndexer, SingleIdTokenIndexerfrom allennlp.data.tokenizers import WordTokenizer, Tokenizer@DatasetReader.register('custom')class CustomReader(DatasetReader):
def __init__(self, tokenizer: Tokenizer = None, token_indexers: Dict[str, TokenIndexer] = None) -> None:
super().__init__(lazy=False)
self.tokenizer = tokenizer or WordTokenizer()
self.word_indexers = token_indexers or {"word": SingleIdTokenIndexer('word')}
def text_to_instance(self, _input: str) -> Instance:
fields = {}
tokenized_input = self.tokenizer.tokenize(_input)
fields['input'] = TextField(tokenized_input, self.word_indexers)
return Instance(fields)
def _read(self, file_path: str) -> Iterator[Instance]:
with open(file_path) as f:
for line in f:
yield self.text_to_instance(line)
首先需要自定义_read函数,写好读取数据集的方式,通过yield方式返回构建一个instance需要的文本。然后通过text_to_instance函数将文本转化为instance。在text_to_instance函数中,需要对输入的文本进行切分,然后构建fileld。
self.tokenizer是用来切分文本成 Token 的。有 Word 级别的也有 Char级别的。self.word_indexers是用来索引 Token 并转换为 Tensor。同样 TokenIndexer 也有很多种,在实现自己的模型之前可以看看官方文档有没有比较符合自己需要的类型。如果你需要构建多个 Vocabulary ,比如源语言的vocab 和目标语言的vocab, 就需要在这里多定义一个self.word_indexers。不同indexers在vocab中,是通过SingleIdTokenIndexer 函数初始化的 namespace 来区分的,也就是 15 行代码中最后一个的'word'。
2. Model
与 PyTorch 实现 model 的方式一样,但需要注意的是:
@Model.register('')注册之后可以使用 JsonNet 进行模型选择(如果你有多个模型,可以直接修改 Json 值来切换,不需要手动修改代码)。
由于 AllenNLP 封装了 Trainer ,所以我们需要在 model 内实现或者选择已有的评价指标,这样在训练过程中就会自动计算评价指标。具体方法是,在__init__方法中定义评价函数,可以从在官方文档[3]上看看有没有,如果没有的话就需要自己写。
self.acc = CategoricalAccuracy()
然后在forward方法中调用评价函数计算指标
self.acc(output, labels)
最后在 model 的get_metrics返回对应指标的 dict 结果就行了。
def get_metrics(self, reset: bool = False) -> Dict[str, float]:return {"acc": self.acc.get_metric(reset)}
3. Trainer
一般来说直接调用 AllenNLP 的 Trainer 方法就可以自动开始训练了。但是如果你有一些特殊的训练步骤,比如 GAN[4],你就不能单纯地使用 AllenNLP 的 Trainer,得把 Trainer 打开进行每步的迭代,可以参考[4]中 trainer 的写法。
AllenNLP使用总结
关于 AllenNLP 的学习代码,可以参考[5]。由于 AllenNLP 是基于 PyTorch 的,代码风格和 PyTorch 的风格基本一致,因此如果你会用 PyTorch,那上手 AllenNLP 基本没有什么障碍。代码注释方面也比较全,模块封装方面比较灵活。AllenNLP 的代码非常容易改动,就像用纯的 PyTorch 一样灵活。当然灵活也就意味着很多复杂的实现,AllenNLP 目前还没有,大部分可能都需要自己写。AllenNLP 依赖了很多 Python 库,近期也在更新。
三、OpenNMT
OpenNMT[6] 是一个开源的神经机器翻译(neural machine translation)项目,采用目前普遍使用的编码器-解码器(encoder-decoder)结构,因此,也可以用来完成文本摘要、回复生成等其他文本生成任务。目前,该项目已经开发出 PyTorch、TensorFlow 两个版本,用户可以按需选取。本文以 PyTorch 版本[7]为例进行介绍。
OpenNMT使用方法
1. 数据处理
作为一个典型的机器翻译框架,OpenNMT 的数据主要包含 source 和 target 两部分,对应于机器翻译中的源语言输入和目标语言翻译。OpenNMT 采用 TorchText 中的 Field 数据结构来表示每个部分。用户自定义过程中,如需添加 source 和 target 外的其他数据,可以参照 source field 或 target field 的构建方法,如构建一个自定义的 user_data 数据:
fields["user_data"] = torchtext.data.Field(init_token=BOS_WORD, eos_token=EOS_WORD,pad_token=PAD_WORD,include_lengths=True)
其中 init_token、eos_token 和 pad_token 分别为用户自定义的开始字符、结束字符和 padding 字符。Include_lengths 为真时,会同时返回处理后数据和数据的长度。
2. 模型
OpenNMT 实现了注意力机制的编码器-解码器模型。框架定义了编码器和解码器的接口,在该接口下,进一步实现了多种不同结构的编码器解码器,可供用户按需组合,如 CNN、 RNN 编码器等。如用户需自定义特定结构的模块,也可以遵循该接口进行设计,以保证得到的模块可以和 OpenNMT 的其他模块进行组合。其中,编码器解码器接口如下:
class EncoderBase(nn.Module):def forward(self, input, lengths=None, hidden=None):raise NotImplementedError
class RNNDecoderBase(nn.Module):
def forward(self, input, context, state, context_lengths=None):
raise NotImplementedError
3. 训练
OpenNMT 的训练由 Trainer.py 中 Trainer 类控制,该类的可定制化程度并不高,只实现了最基本的序列到序列的训练过程。对于多任务、对抗训练等复杂的训练过程,需要对该类进行较大的改动。
OpenNMT使用总结
OpenNMT 提供了基于 PyTorch 和 TensorFlow 这两大主流框架的不同实现,能够满足绝大多数用户的需求。对于基础框架的封装使得其丧失了一定的灵活性,但是对于编码器-解码器结构下文本生成的任务来说,可以省去数据格式、接口定义等细节处理,将精力更多集中在其自定义模块上,快速搭建出需要的模型。
四、ParlAI
ParlAI 是 Facebook 公司开发出的一个专注于对话领域在很多对话任务上分享,训练和评估对话模型的平台[8]。这个平台可以用于训练和测试对话模型,在很多数据集上进行多任务训练,并且集成了 Amazon Mechanical Turk,以便数据收集和人工评估。
ParlAI 中的基本概念:
world 定义了代理彼此交互的环境。世界必须实施一种 parley 方法。每次对 parley 的调用都会进行一次交互,通常每个代理包含一个动作。
agent 可以是一个人,一个简单的机器人,可以重复它听到的任何内容,完美调整的神经网络,读出的数据集,或者可能发送消息或与其环境交互的任何其他内容。代理有两个他们需要定义的主要方法:
def observe(self, observation): #用观察更新内部状态def act(self): #根据内部状态生成动作
observations 是我们称之为代理的 act 函数返回的对象,并且因为它们被输入到其他代理的 observe 函数而被命名。这是 ParlAI 中代理与环境之间传递消息的主要方式。观察通常采用包含不同类型信息的 python 词典的形式。
teacher 是特殊类型的代理人。他们像所有代理一样实施 act 和 observe 功能,但他们也会跟踪他们通过报告功能返回的指标,例如他们提出的问题数量或者正确回答这些问题的次数。
ParlAI 的代码包含如下几个主要的文件夹[9]:
core 包含框架的主要代码;
agents 包含可以和不同任务交互的代理;
examples 包含不同循环的一些基本示例;
tasks 包含不同任务的代码;
mturk 包含设置 Mechanical Turk 的代码及 MTurk 任务样例。
ParlAI 使用方法
ParlAI 内部封装了很多对话任务(如 ConvAI2 )和评测(如 F1 值和 hits@1 等等)。使用 ParlAI 现有的数据,代码以及模型进行训练和评测,可以快速实现对话模型中的很多 baseline 模型。但由于代码封装性太强,不建议使用它从头搭建自己的模型。想在基础上搭建自己的模型可以详细参考官网中的教程[10]。
这里简单介绍直接利用内部的数据,代码以及模型进行训练和评测的一个简单例子(Train a Transformer on Twitter):
1. 打印一些数据集中的例子
python examples/display_data.py -t twitter*# display first examples from twitter dataset*
2. 训练模型
python examples/train_model.py -t twitter -mf /tmp/tr_twitter -m transformer/ranker -bs 10 -vtim 3600 -cands batch -ecands batch --data-parallel True# train transformer ranker
3. 评测之前训练出的模型
python examples/eval_model.py -t twitter -m legacy:seq2seq:0 -mf models:twitter/seq2seq/twitter_seq2seq_model# Evaluate seq2seq model trained on twitter from our model zoo
4. 输出模型的一些预测
python examples/display_model.py -t twitter -mf /tmp/tr_twitter -ecands batch# display predictions for model saved at specific file on twitter
ParlAI 使用总结
ParlAI 有自己的一套模式,例如 world、agent 和 teacher 等等。代码封装性特别好,代码量巨大,如果想查找一个中间结果,需要一层一层查看调用的函数,不容易进行修改。ParlAI 中间封装了很多现有的 baseline 模型,对于对话研究者,可以快速实现 baseline 模型。目前 ParlAI 还在更新,不同版本之间的代码可能结构略有不同,但是 ParlAI 的核心使用方法大致相同。
五、总结
本文介绍了四种常见框架构建自定义模型的方法。Tensor2Tensor 涵盖比较全面,但是只支持 TensorFlow。AllenNLP 最大的优点在于简化了数据预处理、训练和预测的过程。代码改起来也很灵活,但是一些工具目前官方还没有实现,需要自己写。如果是比较传统的编码器-解码器结构下文本生成任务,使用 OpenNMT 能节省很多时间。但是如果是结构比较新颖的模型,使用 OpenNMT 搭建模型依旧是一个不小的挑战。ParlAI 内部封装了很多对话任务,方便使用者快速复现相关的 baseline 模型。但由于代码封装性太强和其特殊的模式,使用 ParlAI 从头搭建自己的模型具有一定的挑战性。每个框架都有各自的优点和弊端,大家需结合自身情况和使用方式进行选择。但是不建议每个框架都试一遍,毕竟掌握每个框架还是需要一定时间成本的。
参考资料
[1] https://github.com/tensorflow/tensor2tensor
[2] https://allennlp.org/tutorials
[3]https://allenai.github.io/allennlp-docs/api/allennlp.training.metrics.html
[4] http://www.realworldnlpbook.com/blog/training-a-shakespeare-reciting-monkey-using-rl-and-seqgan.html
[5] https://github.com/mhagiwara/realworldnlp
[6] http://opennmt.net/
[7] https://github.com/OpenNMT/OpenNMT-py
[8]http://parl.ai.s3-website.us-east-2.amazonaws.com/docs/tutorial_quick.html
[9] https://www.infoq.cn/article/2017/05/ParlAI-Facebook-AI
[10]http://parl.ai.s3-website.us-east-2.amazonaws.com/docs/tutorial_basic.html
(*本文为 AI 科技大本营转载文章,转载请联系原作者)


