

相信每个看过《钢铁侠》的影迷们都曾羡慕过这样一个场景:只用轻轻一挥手就可以凭空推拽操控虚拟物体。

这样的酷炫的操作到底是什么?
它就是通过数学算法来识别人类手势的—手势识别,在VR领域应用广泛。
想要了解手势识别技术,首先要了解以下两方面:
3
手势识别常用的算法
3
手势识别常用硬件方案
手势识别常用的算法
手势识别的原理并不复杂,它通过硬件捕获自然信号,就像相机捕获图片信息那样,然后通过软件算法计算得到手的位置、姿态、手势等,处理成计算机可以理解的信息。

模型驱动类算法
此类算法通常是预先用手部 pose(pose 指位姿参数或节点位置,后文将统称为 pose)生成一系列手的几何模型,并建立一个搜索空间(所有可能的手势几何模型的集合),然后在搜索空间内找到与输入深度图最匹配的模型。

模型驱动类算法通常需要设计一种方式把 pose 转换成对应的几何模型。
先把 pose 转换成对应的 mesh(下图左侧),在进一步转换成光滑曲面模型(下图右侧)。我们可以理解为 pose 是自变量,几何模型可由 pose 算出,且几何模型与 pose 一一对应。
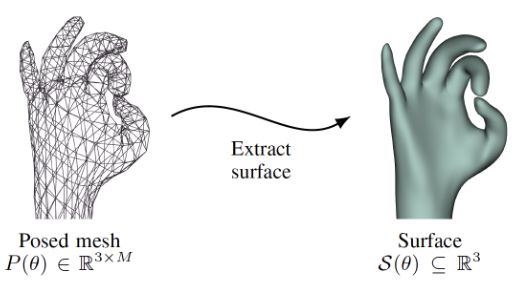
输入的手部深度图可转化为点云, 此点云就相当于在真实的手表面上采集到的一些 3D 点,如下图中的红点和蓝点:
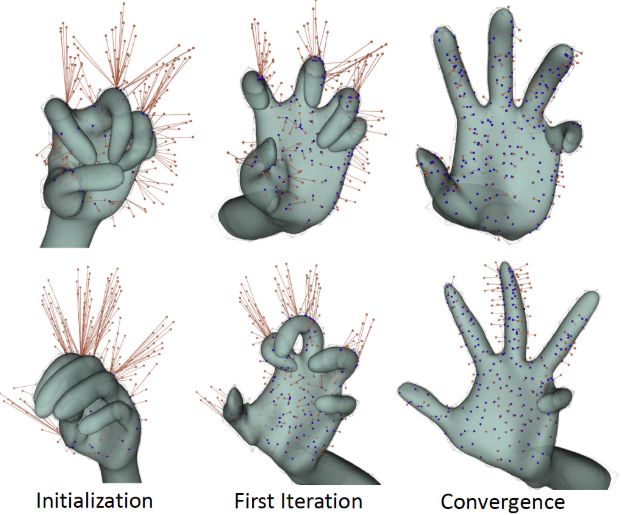
这样就可以描述深度图和pose的相似度。
上图从左到右展示了迭代初期到迭代结束时的 pose,这种迭代的数值解法通常对初始化要求较高,算法实现时,通常利用上一帧的pose来初始化当前帧的计算。
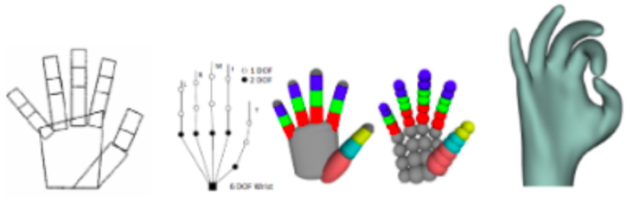
这种模型驱动类方法需要手工设计几何模型和损失函数。简单的几何模型计算量小,复杂的几何模型准确度高。通常设计模型时需要在准确度和性能之间做权衡。
数据驱动类算法
此类算法是指利用收集数据中训练样本与其对应的标签关系,让机器学习一个从样本到标签的映射。
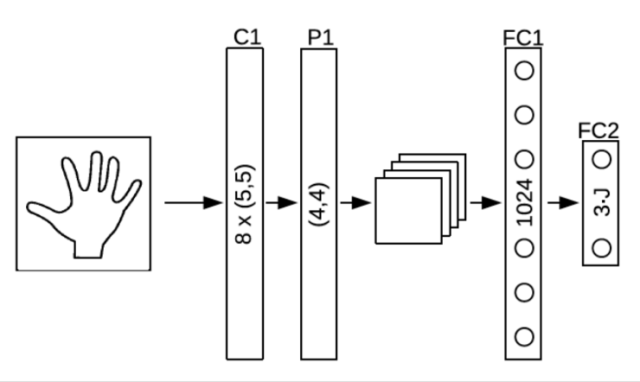
此类方法的优点是不需要设计复杂的模型,缺点是需要大数据。但现在大数据时代数据量已经不是问题,这种数据驱动的方式已经成为目前的主流研究方向。
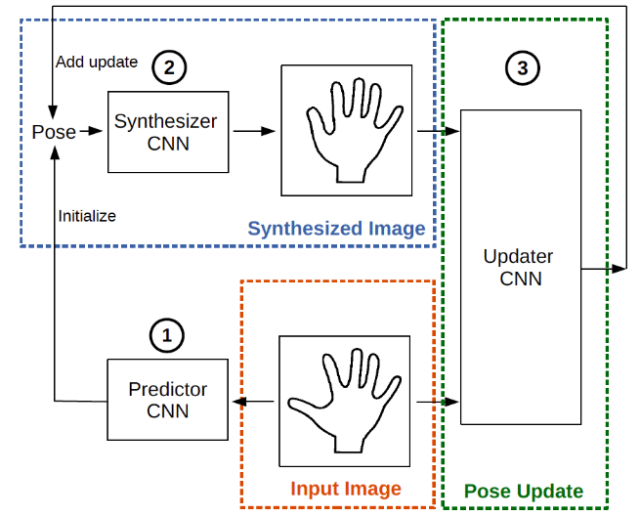
早期学术界研究手势关键点回归的经典方法有 Cascade regression, Latent Regression Forest 等。近些年研究主要集中在各类神经网络如:DeepPrior 系列、REN、pose guided、3D-CNN、HandPointNet、Feedback Loop 等。
手势识别常用硬件方案
目前手势识别主要有以下 3 种硬件方案:
No.1 摄像头方案
常见的又分彩色摄像头方案和深度摄像头方案。
彩色摄像头方案:
彩色摄像头方案只需要一个普通摄像头,捕捉拍摄一张彩色图片,通过 AI 算法得到图片中手的位置、姿态、手势等信息。优势是设备成本低、数据容易获取。

深度摄像头方案:
这个方案是通过深度摄像头来获取带有深度信息的图片。优势是更容易获取手部的 3D 信息,相对应的通过 AI 算法得到的手部 3D 关键点也更加准确和稳定。但缺点是需要额外的设备、硬件成本比较高。

No.2 毫米波雷达
毫米波雷达方案的代表有谷歌推出的一款特殊设计的雷达传感器—— Project Soli ,它可以追踪亚毫米精准度的高速运动,但目前尚处在实验室阶段。

从其公布的演示来看,目前可以识别个别指定的手势,并在小范围内识别微小精确的手势操作,很适合发挥人类精准的小肌肉运动技能(fine motor skills)。但缺点是有效范围太小,无法得到手的所有自由度。

No.3数据手套
数据手套是指在手上带一个内置传感器的特制手套,通过传感器检测手指的屈伸角度或位置,再根据 Inverse kinematics(逆运动学)来计算出手的位置。

一般用到的传感器有弯曲传感器、角度传感器、磁力传感器等。
此方案对手的局部动作检测很准,而且不受视觉方案中视野范围的限制。但缺点是手上必须戴手套不方便,且只能检测局部的手指动作,不能定位手部整体的位置角度。

随着语音识别和手势识别等交互方式的加入,让我们与机器有了更多互动的可能。语音交互在人工智能时代已经有了先发优势,正在被逐渐落地并且有望大规模应用。可以预见的是,手势交互将是未来人机交互必不可少的一部分。