



文/凤凰新闻客户端荣誉主笔 唐驳虎
核心提示:
1、根据国际知名的Nextstrain团队制作的病毒演化树,与北京新发病毒基因序列最相近的,是3月17日台湾上报的样本。因此不少网民惊呼“台湾投毒”。
2、但该团队有很多不同算法和扩展的病毒库,如果调整算法,亲缘关系较近的就变成丹麦和捷克上报的病毒。
3、但总体看由于数据缺失较多,这一团队的基因组序列只能大致定位。但根据科学事实和社会逻辑,可以推断出北京输入性疫情的四个源头。
正如预期地那样,在北京疫情得到迅速控制的同时,对病毒溯源的好奇也为公众所关注。
那么,导致此次北京疫情的病毒从哪里来? 如何暴发? 这既是一个科学问题,也关系到下一步疫情的防控策略。
在新发地人员流动是个天量、市场里多处检出病毒环境样本的背景下,通过常规的流行病学调查已经没有可能。
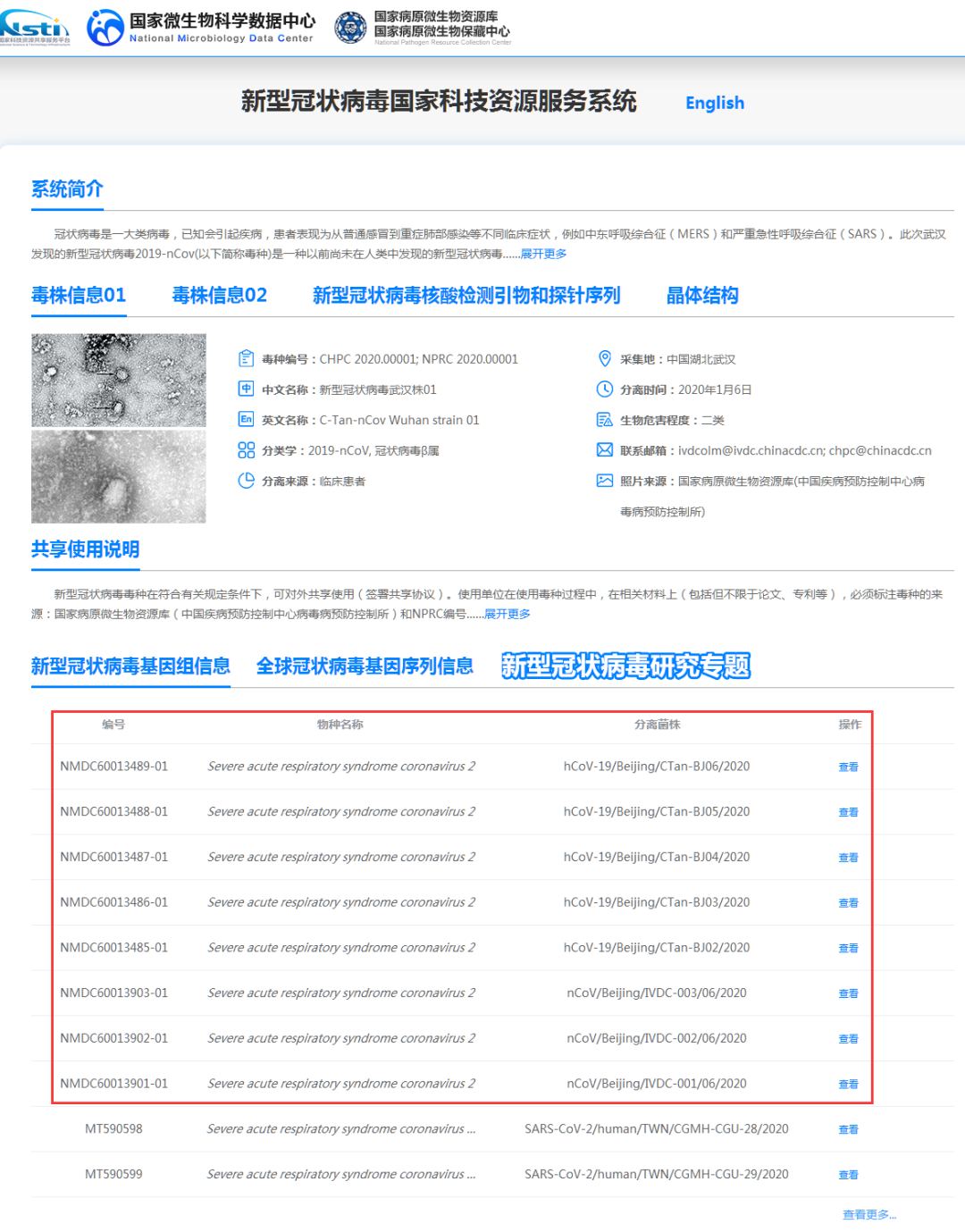
6月18日(周四)晚,中国疾控中心(CDC)通过“新冠病毒国家科技资源服务系统”,也就是中科院微生物所承办的国家微生物科学数据中心,正式发布了3组2020年6月北京新发地新冠疫情及病毒基因组序列数据。
这个新闻已经在第二天被广为报道了,但实际上,19日中国CDC又提交了5组序列。虽然由于新发地疫情是单点爆发,彼此之间差异不大,2~3组就够了。不过还是将信息汇总如下。
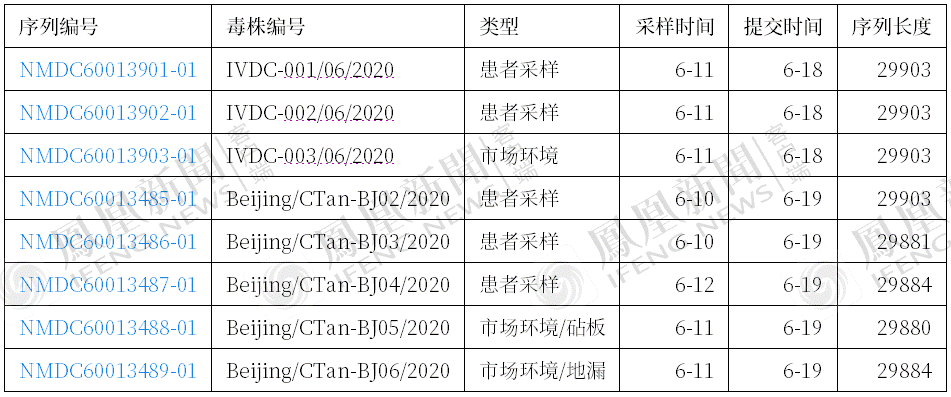
虽然编号不同,但从采样时间(6月10日、11日)上看,应该就是在01、02号患者,也就分别是“西城大爷”、食品研究院员工身上采到的。
因为01号患者“西城大爷”是10日下午因间断发热,独自骑车佩戴口罩,到宣武医院发热门诊就诊检查并隔离治疗。当天深夜,经过近6小时核酸PCR扩增检测,初检为阳性。
6月11日凌晨2时,北京市疾控中心接到西城区病例标本,立刻对标本进行复核,早晨7时许,市疾控中心复核送检样本确认,核酸阳性。
02号患者食品研究院员工,是在9日,本人感觉不适,出现咽痛、发热、咳嗽、流涕等症状,到社区所在的博爱医院发热门诊就诊,并做核酸检测。
由于首次采集样本量太少,10日通知重新采集。11日医院初检结果出来,为阳性。
他的同事、03号患者作为密接者,被转运到定点医院隔离排查,已经是12日凌晨的事情了。
02、03号患者直到12日中午,才复核确认为阳性。所以,6月10日、11日的采样样本,应属于01、02号患者。
同时,6月11日当天,就已经对新发地市场的环境进行了采样,这说明“西城大爷”的敏锐,为北京疾控争取了24、甚至48小时宝贵的时间。

当然,病毒序列只有专业人士才能看得懂。同时,只有互相比较,才能得出分析结论。
但是生物信息技术的飞速发展,给我们提供了非常便利的工具,可以让每个受过高中教育的人,都能自己了解、分析出病毒溯源。

GISAID与Nextstrain
之前在2月份就介绍过,国际公开共享的基因数据库,最重要的有这么几组。
GenBank是美国国家生物技术信息中心(National Center for Biotechnology Information ,NCBI)建立的基因序列数据库,面向所有生物信息。
GISAID的全称是Global Initiative of Sharing All Influenza Data(全球共享所有流感数据倡议),由德国联邦食品和农业部及其下属的德国联邦动物研究所运营。
这是2009年全球流感期间创建的数据库,由世卫组织等倡议,目的即如其名,最开始的时候专注于流感,后来则逐渐扩大为呼吸道传染病,及其他病毒信息。
由于病毒特性,在这次疫情中,德国的GISAID国际流感数据库是各国学者上传最集中的数据库,可谓是全球标准。
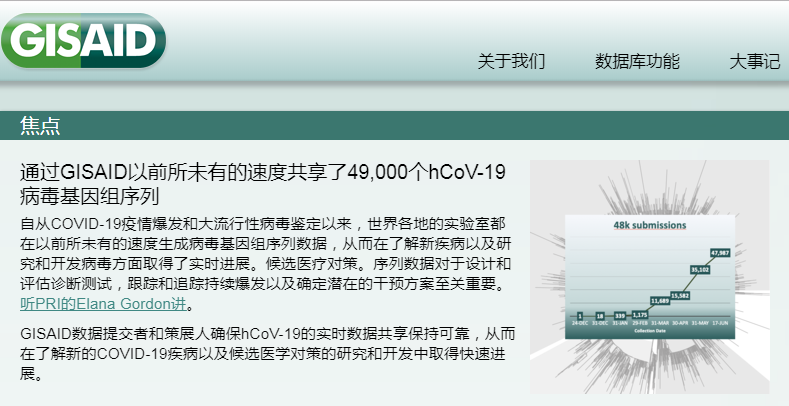
在2月底,GISAID还只是有21个国家共享了128组病毒测序数据。而随着全球大暴发,现在GISAID上的新冠测序已经超过4.9万组了,如实反映了全球大暴发的规模。
但是,专业的病毒序列,普通人肯定是完完全全彻彻底底看不懂的。
因此,美国西雅图弗雷德·哈钦森癌症研究中心的Trevor Bedford等病毒进化专家团队,组织了一个名为Nextstrain的项目。
Nextstrain项目力图通过生物信息学,也就是分析基因序列变化。把不同的病毒放在一起,看哪个病毒突变的更多,变化更多的一般是进化更新后的病毒,突变少的更接近原始的病毒,
这个分析尤其是关注变化的特定位点,打个比方,比如某个样本在第20000点位出现了一个变化G-T。
那么之后采集到的新样本,如果同样在第20000点位有G-T的变化,则可以认定,都是之前这个病毒的子代。
因为根据概率学,其他新冠病毒同样在此处出现独立变化的概率只有三万分之一。

Nextstrain计算的起点,是2019年12月24日武汉采集,2020年1月11日上传的第一份样本序列(左下角),以及早期序列
而且实际计算中,变化远不止一处。比如某个病毒在第15000、20000、25000点位都有特定变异。
那么可以肯定,第5000及15000、20000、25000,还有第10000及15000、20000、25000出现变异而且后3个位点变异相同的病毒,必然都是前序病毒的子代。
生物信息学在病毒变异上的强大分析能力,催生了“基因组流行病学”,可以通过病毒全基因组序列的演变,去追踪病毒的传播、演化。
这是一份非常强大的工具,就如同刑侦上基因测序与特定位点的应用一样。
Nextstrain不仅通过算法,自动分析病毒传播演变,还通过网站,提供了可视化的病毒演化树。
因此,不仅为广大普通公众、一般生物研究者提供了便利,也为GISAID所认可、合作。
在GISAID官网上,显著的入口便是Nextstrain呈现的可视化界面链接,而其本行——面向注册专业人员上传下载病毒序列数据的入口反而放在了不起眼的地方。

病毒的演化树,告诉了我们什么?
在Nextstrain,用近3000个病毒序列自动呈现了新冠病毒大流行的全景。
根据病毒的重大变异,人们把迄今为止的病毒,分组为19A、19B,20A、20B、20C几组大簇。前面的数字表示出现年份。
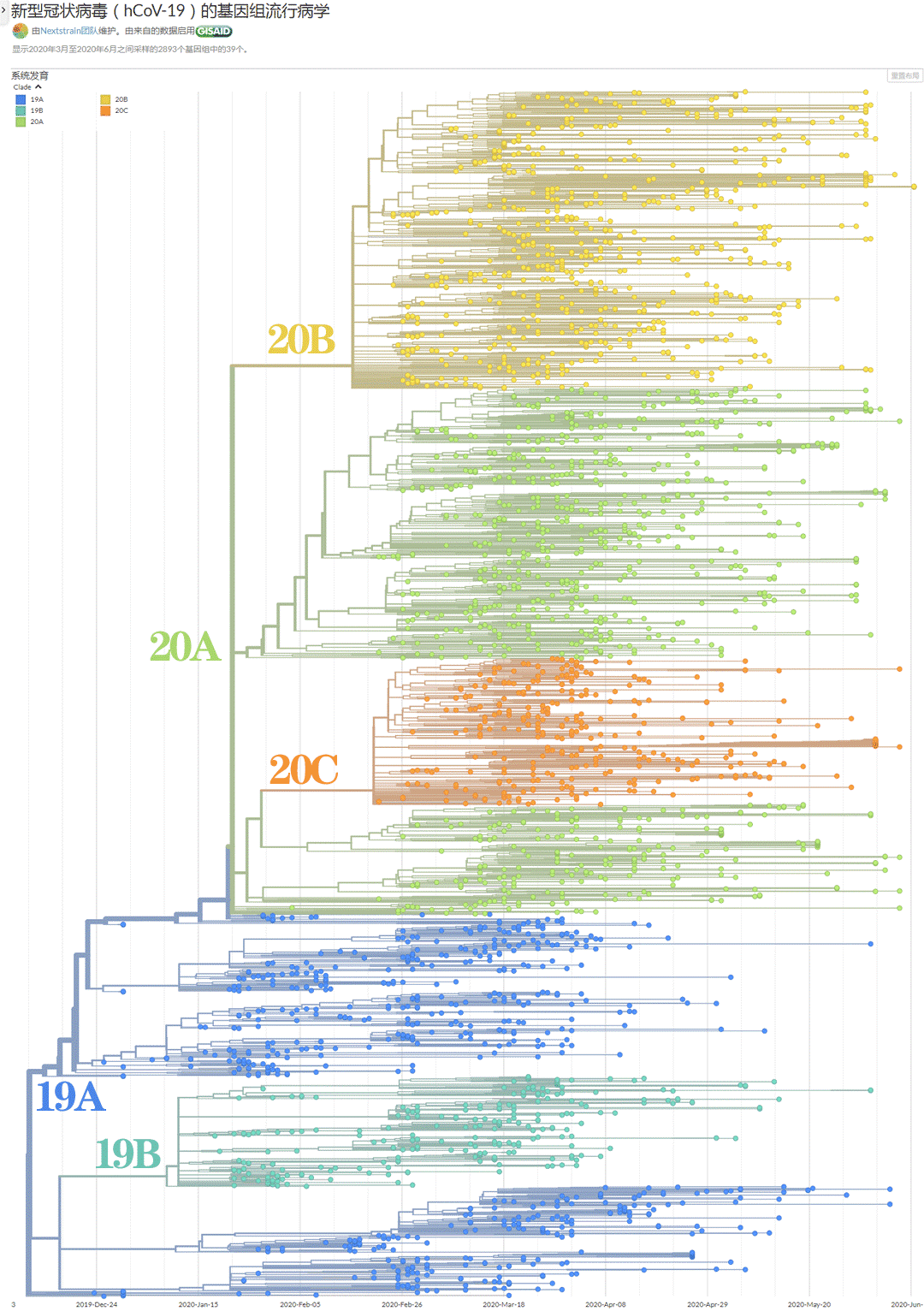
19系列,主要在亚太地区传播(图中蓝色),同时部分扩散到美国西海岸(红色)。
20系列在2月下旬开始被科学家们测报上传,主要在欧洲地区传播(土黄色),同时部分扩散到美国东海岸(红色)、拉美(橙色)。
还有相当部分20B、20C系列,通过国际航班,回流到了亚太(蓝色),比例还不小。
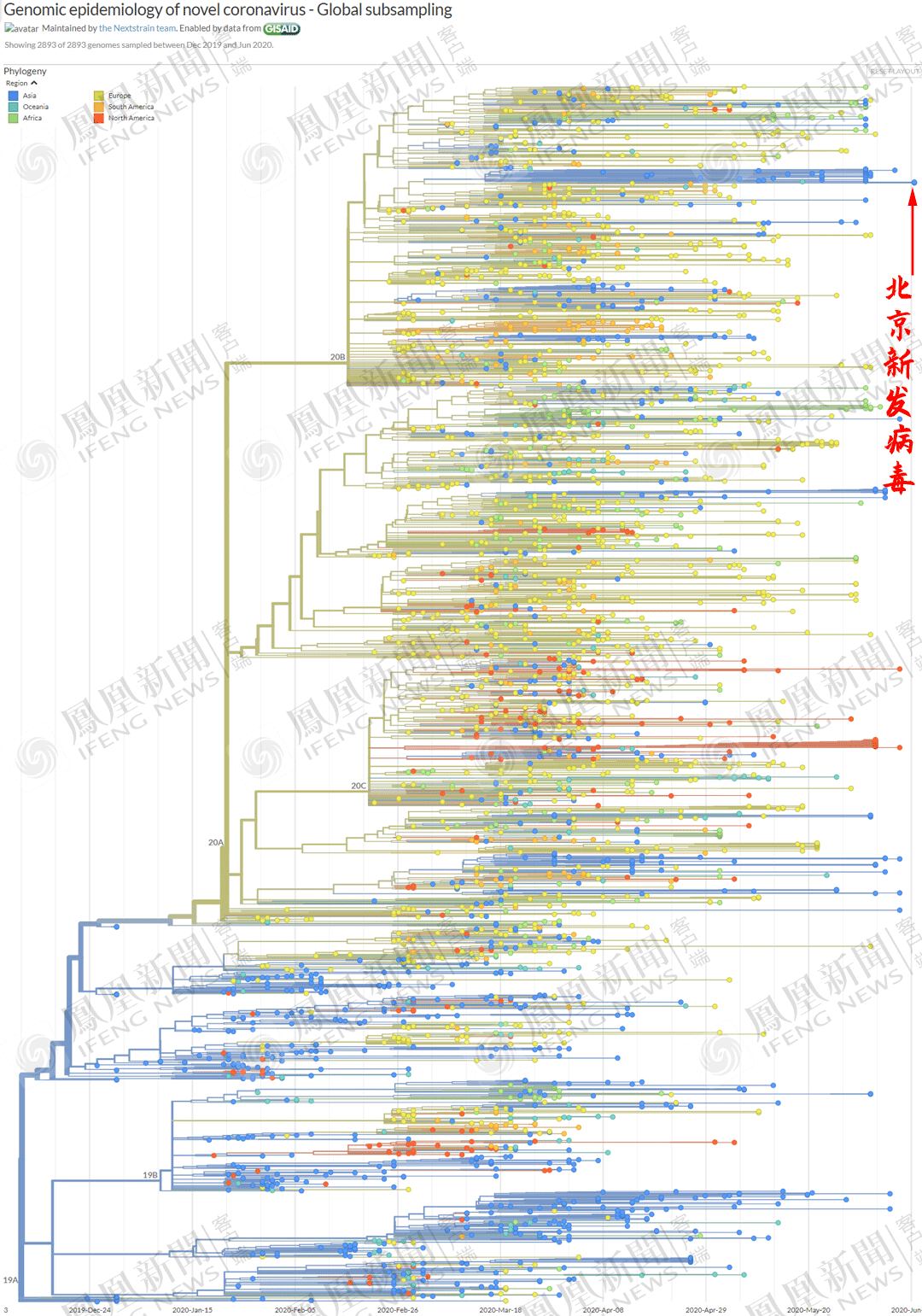
图注:根据各大洲设色的病毒演化传播图,蓝色亚太,青色大洋洲,绿色非洲,土黄色欧洲,橙黄色南美,红色北美。
在此前的转述性报道里,北京的新发病毒测序,被描述为“来自欧洲”,后来又被补上几句“但和欧洲目前主要流行的比又有些不同,它比欧洲流行的更加古老”。
这些概述用语过于含糊,令人捉摸不透。
但是现在中国CDC已经同时向世卫组织以及GISAID提交了北京新发病毒基因组序列,所以我们就能便利地了解病毒在病毒演化树中的位置。
虽然确信北京新发病毒属于20B大簇,但在这次公布的信息中,和之前预想的又有些不同。

病毒来自台湾?
有了病毒序列,有了Nextstrain,也就能够定位北京新发病毒在病毒演化树中的精确位置。
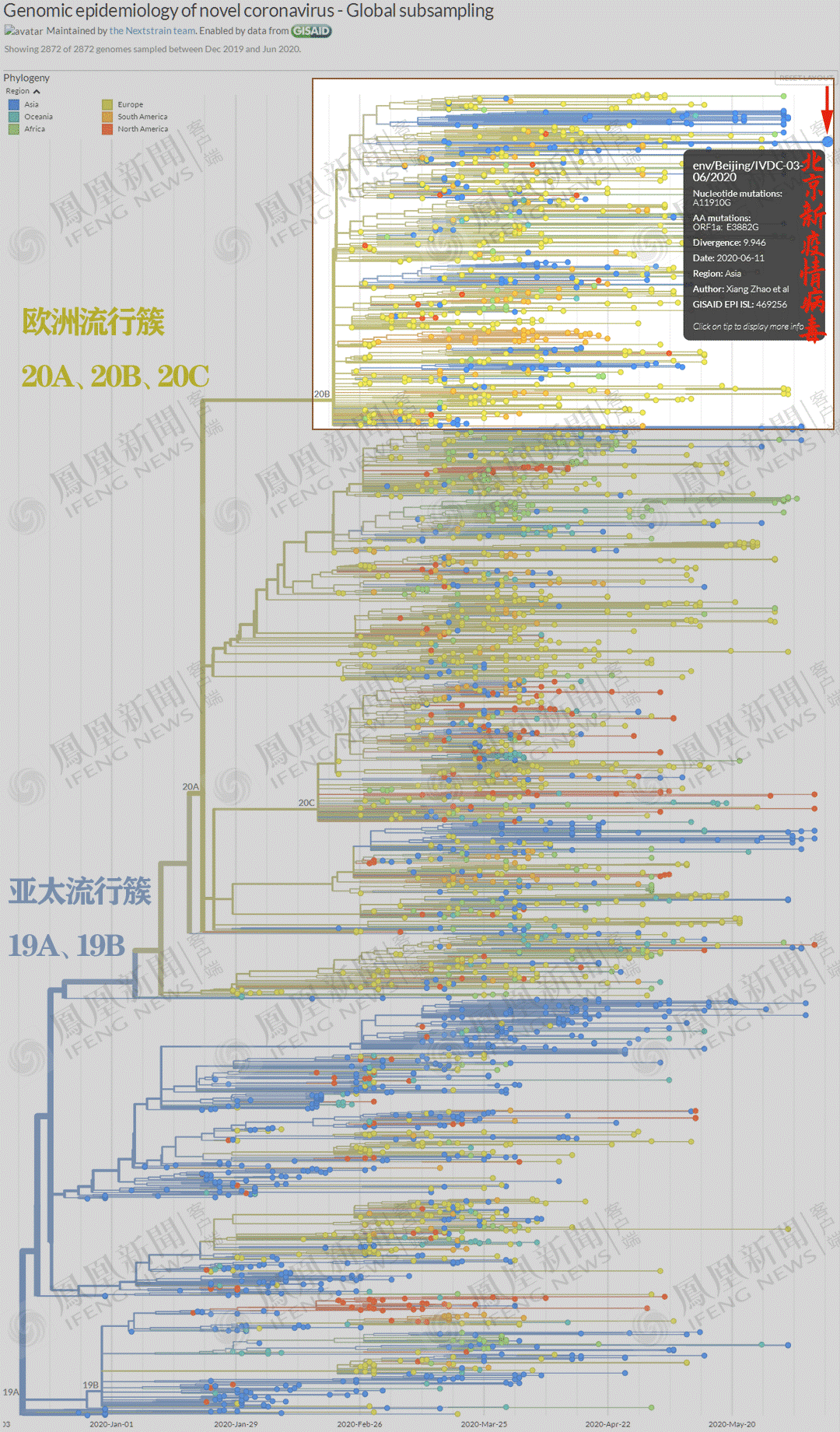
20B大簇定位,北京新发病毒在右上角。将白色区域放大,得到下图。
发现,上图白色区域放大后依然繁杂。

继续放大上图白色区域,得到下图。

放大上图白色(北京新发病毒本簇)与浅灰色(相邻簇),得到下图。

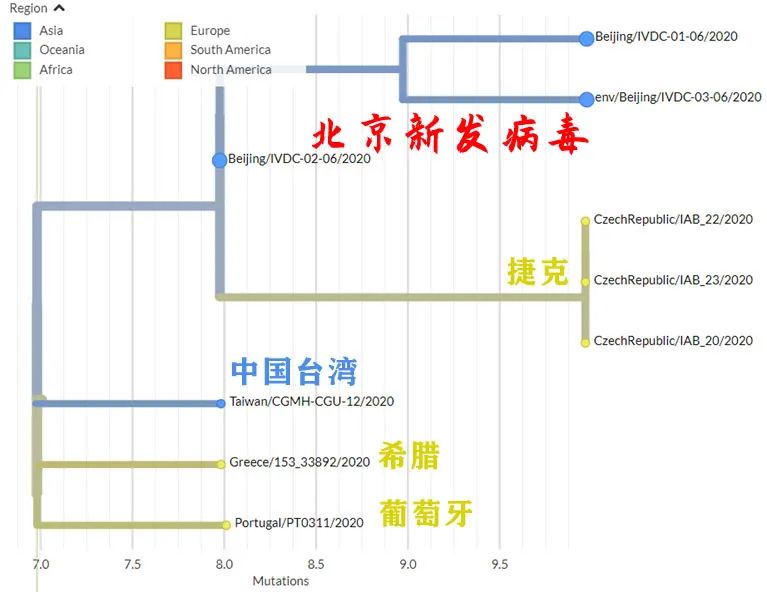
继续放大北京新发病毒本簇,得到下图。
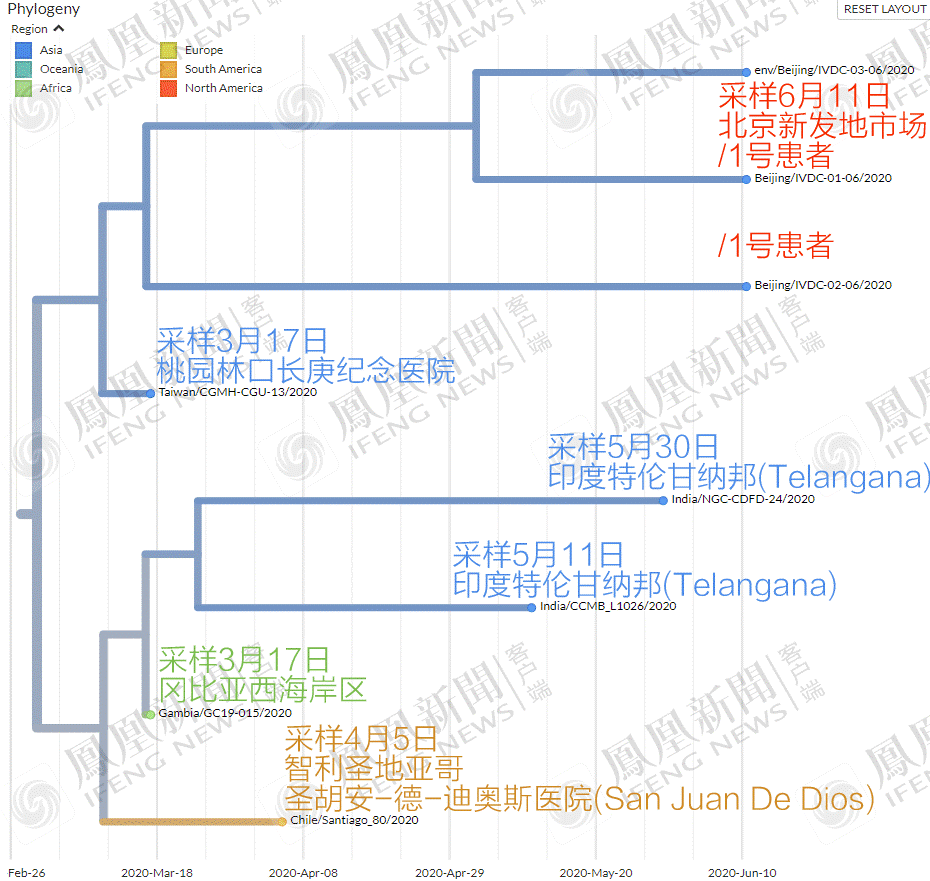
结果发现,与北京新发病毒最近的,居然是3月17日的台湾样本?
这个编号为“Taiwan/CGMH-CGU-13/2020”的病毒序列,由桃园林口著名的长庚纪念医院采集上报,不知道是不是桃园国际机场入境的采样。
(1976年,台塑集团董事长王永庆为纪念其父王长庚,在台北创办了长庚纪念医院。经过30多年的发展,长庚医院已拥有台北、林口、基隆、高雄等7个院区,8300多张病床,成为台湾最大的医学中心。
特别是位于桃园县龟山乡中山高速公路林口交流道口旁的林口长庚纪念医院,更是以4215张病床,成为台湾规模最大的医疗机构。)
于是乎,不少网民惊呼“台湾投毒”?

另外的算法,另外的可能
但是,Nextstrain有不同的算法,收入的病毒库也一直在调整。在另一个算法下,结果就较为不同了。

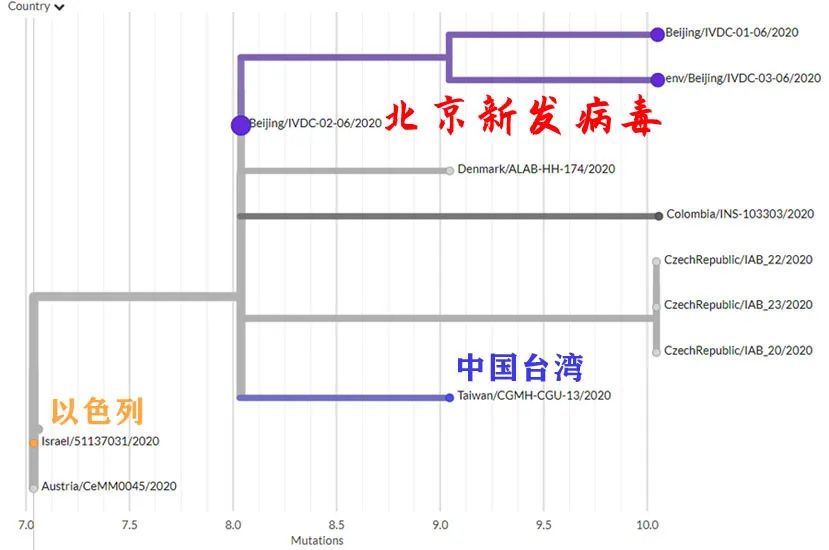
20B大簇。放大图中白色(北京新发病毒本簇)与浅灰色(相邻簇),得到下图。

放大上图白色(北京新发病毒本簇)与浅灰色(相邻簇),得到下图。
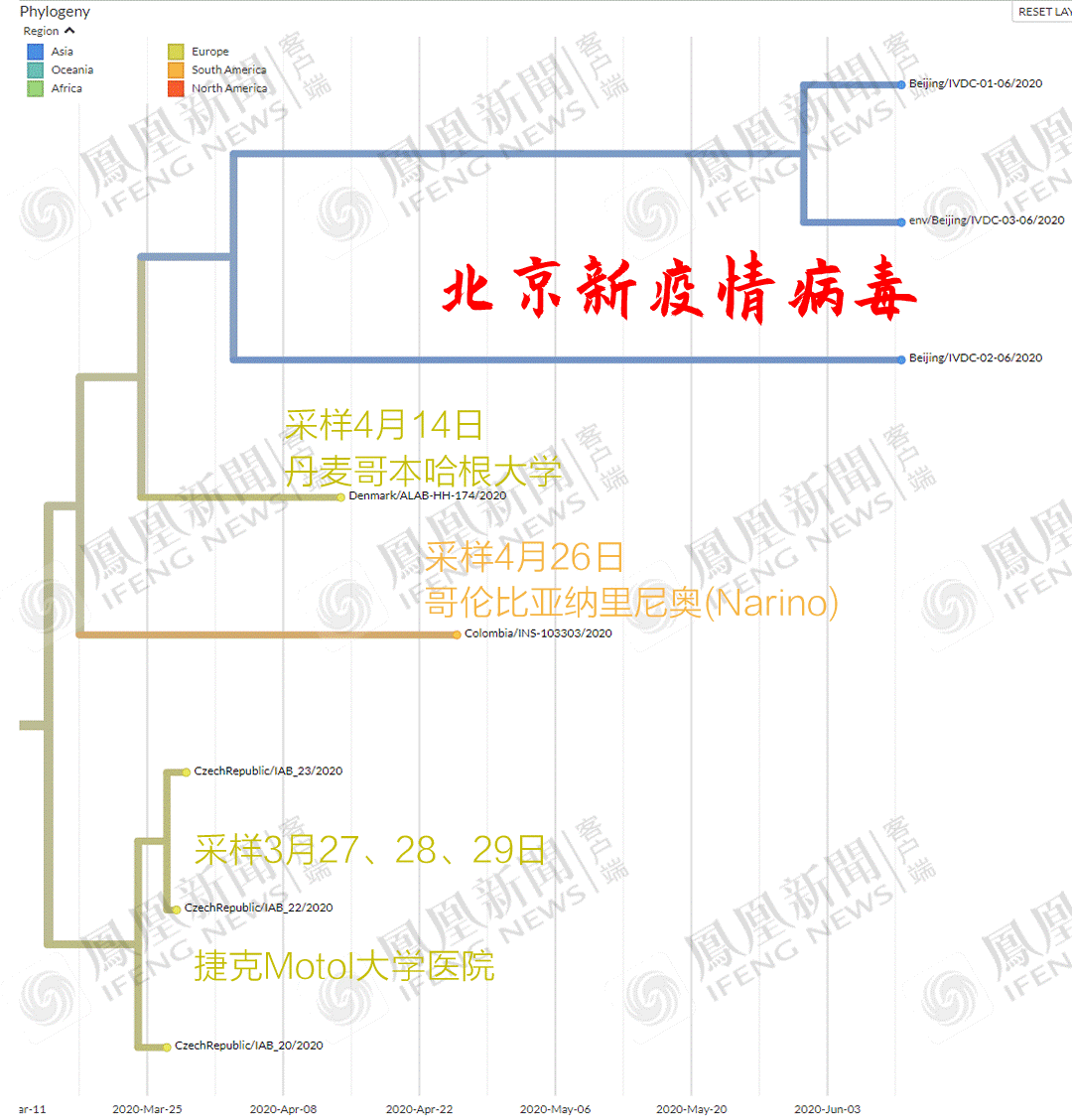
亲缘关系较近的就变成丹麦、捷克了,台湾3月检出的病毒在较远位置。

Nextstrain与GISAID,都还只是管中窥豹
要知道,Nextstrain作为面向公众的可视化工具,受限于性能和可读性,只能在一个视图中处理约3000个基因组。
所以Nextstrain一直在精简、调整数据库里的重复的、不重要的序列,并及时收入新的重要数据(比如刚刚发布的北京新发病毒),让全部数据保持在2900个以下。
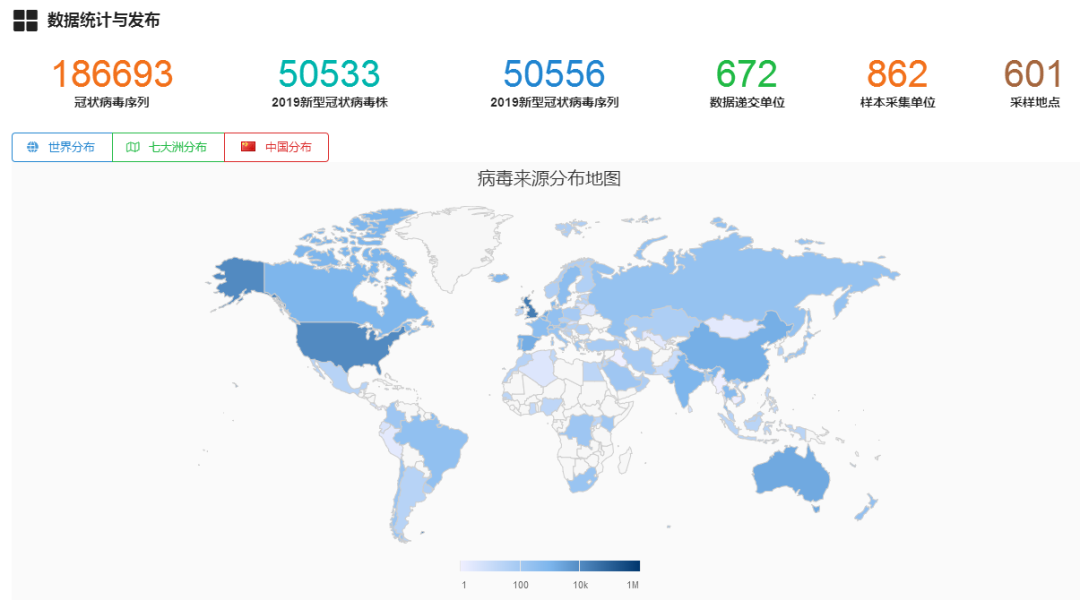
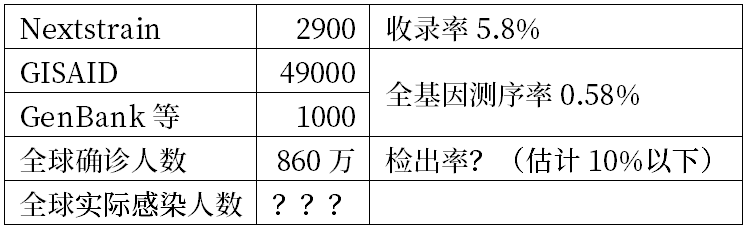
而GISAID目前已超过4.9万个病毒基因序列。另外据中国国家微生物科学数据中心汇总统计,在GenBank还有超过1000个序列数据,全球已公布的病毒基因组超过5万个。
所以,Nextstrain的收录率只有5.8%。而已经公布的5万个全基因组数据,相对目前全球超过860万核酸确诊人数,又是一个比例很小的数据。
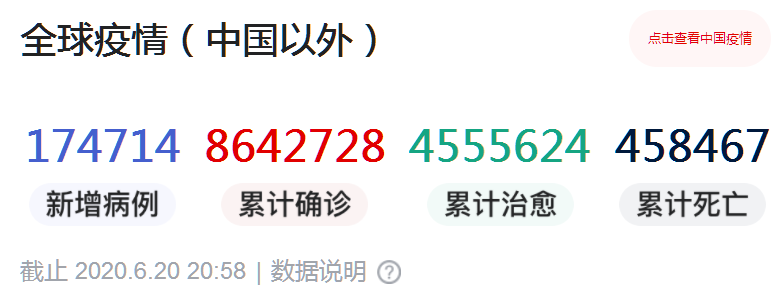

目前的4种可能
所以,在测序数据缺失较多的情况下,病毒基因组序列只能大致定位,还不能确认北京的病毒到底来自什么地方。
但是专业的生物信息学家,利用GISAID数据库(20倍数据),一定能得出比我们利用Nextstrain自动算法更精确一些的结果,只是需要时间。
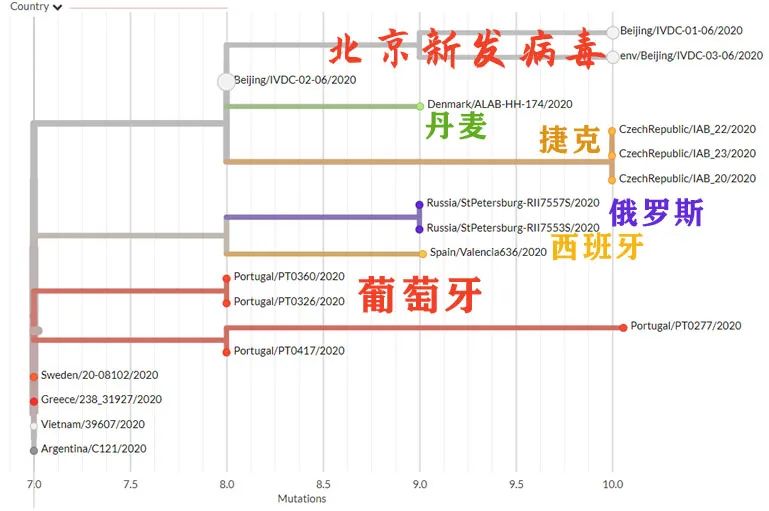
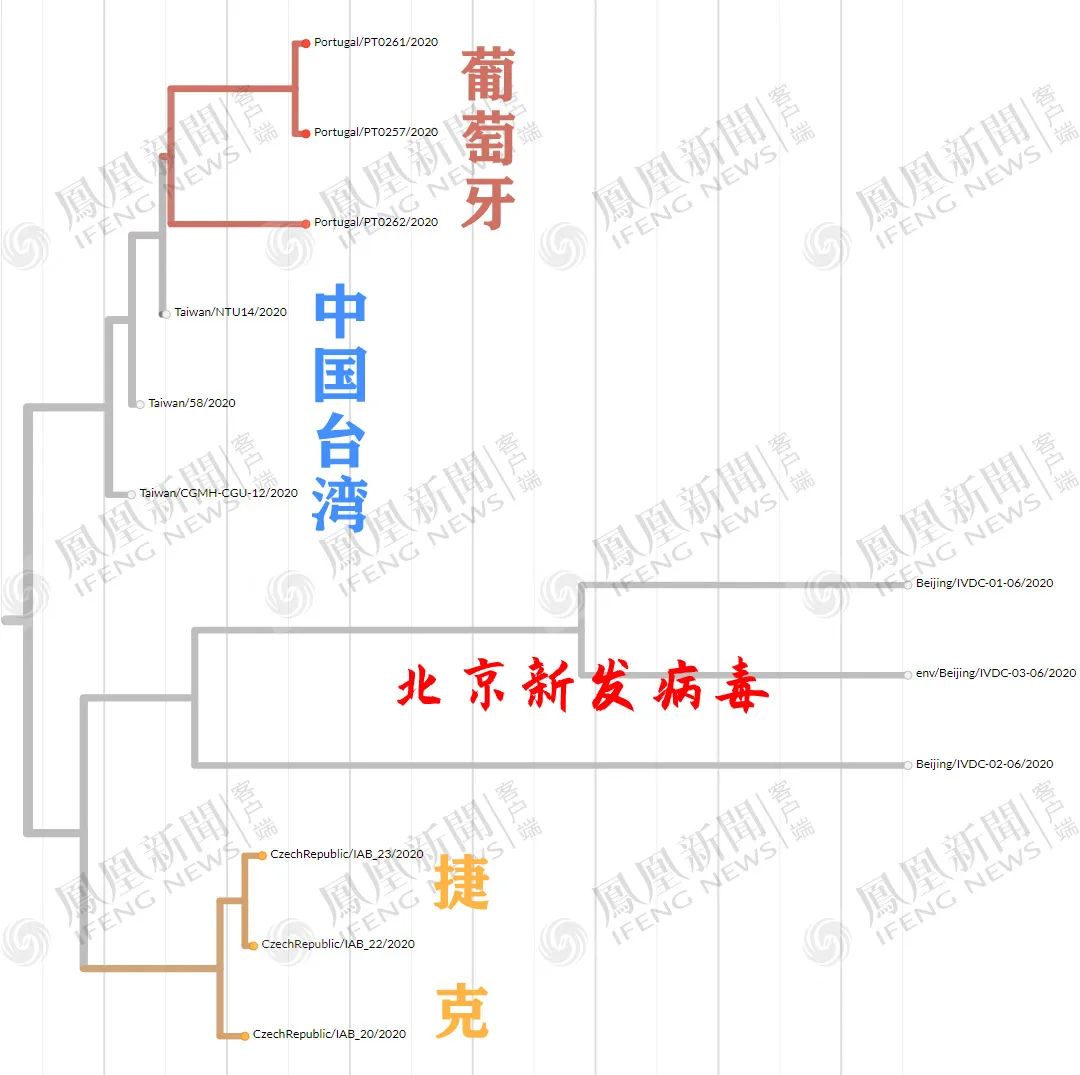
但是,目前无论是什么算法,北京新发病毒都与台湾所验出的病毒序列,以及亚太地区的20B回流流行簇相关性高,其次是丹麦、捷克、葡萄牙等欧洲国家。
根据病毒序列的科学事实,以及合乎常理的社会逻辑,已经可以总结出这次北京输入性疫情的可能源头,可能性从大到小依次排列:
1、东亚国家和地区之间的人员流动导致了此次北京疫情。
从病毒序列看,北京新发病毒属于20B欧洲簇的回流亚太分簇,尤其与台湾3月检出的病毒有亲缘关系,这个需要重视。
从社会逻辑看,东亚人才有去庞大新发地购买生鲜的习惯和需求。
驻京的西方人,都是在外国人聚居的朝阳区特色农贸市场采买,这里才有他们所需的特色食材、配料。吃的东西大部分都太不一样了。
而且东亚人到新发地购物活动,很不引人注意,难以令当事人在后来的流行病学调查中回忆起来。
2、智利冷冻三文鱼,3月底的某一批次受到感染工人污染,在运到中国及解冻加工之后,先后引发了北京新发地、天津五星级酒店后厨疫情。
但也就仅此一批,其他的都不含病毒,所以查不出来。
3、从欧洲返回/入境的人员引发疫情。有较小的可能性。
4、病毒经由3月俄罗斯、4月初绥芬河入境,后隐秘传播到北京。
这个可能性最小,因为根据基因测序结果,北京新发病毒与俄罗斯流行的病毒没有关联。

病毒不可能无中生有,能够感染病毒,肯定是接触了携带病毒的人或物,或者去过存在病毒的环境。
最后还是要提醒大家,在全球绝大部分国家政府放弃抵抗的背景下,世界疫情、中国防控肯定要一直持续到疫苗大规模生产。
在这一段“漫长时期”,保持好自身的防护措施,仍然是每个人的必备措施。