
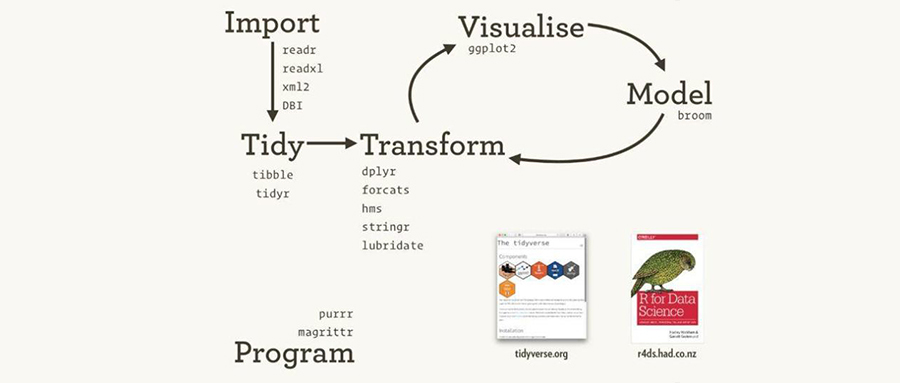
大家在获得了百迈客的分析报告后,需要筛选自己关注的相关结果。tidyverse包能够快速的帮助大家进行筛选。
tidyverse包中包含多种R包,如:ggplot、dplyr、readr、tidyr等。这些包使得日常的数据处理和绘图更加方便。
下面将介绍一些生信处理中实用的操作。
1、tidyverse包的安装
tips:可以设置一些镜像源,提高包的安装速度和成功率
options("repos" = c(CRAN="http://mirrors.cloud.tencent.com/CRAN/"))
options(BioC_mirror="http://mirrors.cloud.tencent.com/bioconductor")
install.packages("tidyverse")
2、快速筛选上下调基因
当获得了百迈客的差异分析结果,但是结果不理想时,需要自己调整差异筛选条件,
dplyr包能够方便操作。
dplyr包中常用的几个函数:
select:筛选相关的列
filter:筛选符合条件的行
mutate:在原有的数据上加一列
summarise:进行统计
group_by:对数据进行分组
rowwise:按行进行操作
利用filter可以在差异分析结果中快速筛选出显著差异的上下调基因。
读入数据:
> head(data)
# A tibble: 4 x 4
gene FDR P.Value logFC
1 gene1 0.02 0.006 0.3
2 gene2 0.003 0.005 0.7
3 gene3 0.002 0.0005 -0.48
4 gene4 0.301 0.13 -0.81
筛选上下调基因:
##筛选上调
gene_up <- data %>% filter(FDR<0.05 & logFC>0)
> gene_up
# A tibble: 2 x 4
gene FDR P.Value logFC
1 gene1 0.02 0.006 0.3
2 gene2 0.003 0.005 0.7
##筛选下调
gene_down <- data %>% filter(FDR<0.05 & logFC<0)
> gene_down
# A tibble: 1 x 4
gene FDR P.Value logFC
1 gene3 0.002 0.0005 -0.48
tips:%>%是管道符,作用和linux中的 | 一样。Rstudio中实用ctrl+shift+m能够快速输入。
筛选上下调基因并加上对应标签,使用mutate和case_when函数:
> data %>% mutate(class=case_when(
+ FDR<0.05&logFC>0~"up",
+ FDR<0.05&logFC<0~"down"
+ ))
# A tibble: 4 x 5
gene FDR P.Value logFC class
1 gene1 0.02 0.006 0.3 up
2 gene2 0.003 0.005 0.7 up
3 gene3 0.002 0.0005 -0.48 down
4 gene4 0.301 0.13 -0.81 NA
03
同名基因取均值或最大值
当拿到百迈客的基因表达谱之后,有时需要对同名基因进行处理。使用dplyr包中的group_by函数和acorss可以快速进行。
###数据
> gene_exp
# A tibble: 6 x 5
gene A B C D
1 gene 1 1 2 3 4
2 gene 1 4 3 2 1
3 gene 2 2 3 4 5
4 gene 2 0 4 3 2
5 gene 2 3 2 4 2
6 gene 3 3 4 2 1
以均值作为表达值
> gene_exp %>% group_by(gene) %>% summarise(across(where(is.numeric),mean))
`summarise()` ungrouping output (override with `.groups` argument)
# A tibble: 3 x 5
gene A B C D
1 gene 1 2.5 2.5 2.5 2.5
2 gene 2 1.67 3 3.67 3
3 gene 3 3 4 2 1
以最大值作为表达值
> gene_exp %>% group_by(gene) %>% summarise(across(A:D,max))
`summarise()` ungrouping output (override with `.groups` argument)
# A tibble: 3 x 5
gene A B C D
1 gene 1 4 3 3 4
2 gene 2 3 4 4 5
3 gene 3 3 4 2 1
这边使用了across的两种方式筛选需要处理的列:
1. 使用数据类型,对所有满足要求的列进行处理,如:where(is.numeric),就是对所有的数字类型的列进行处理
2. 使用列名进行选择,对选择的列进行处理,如:A:D,就是对A到D列进行处理
04
按行对数据进行处理
计算每行的均值
> gene_exp %>% rowwise(gene) %>% mutate(avg=mean(c_across(is.numeric)))
# A tibble: 6 x 6
# Rowwise: gene
gene A B C D avg
1 gene 1 1 2 3 4 2.5
2 gene 1 4 3 2 1 2.5
3 gene 2 2 3 4 5 3.5
4 gene 2 0 4 3 2 2.25
5 gene 2 3 2 4 2 2.75
6 gene 3 3 4 2 1 2.5
利用rowwsie,可以将数据按行进行处理,默认是按列进行处理
5、提取通路中涉及的基因
百迈客的通路富集结果中包含许多信息,有时想快速了解相关通路涉及基因时。利用tidyr包中的函数能够方便清理数据,使得数据更加规整。其中separate_rows函数能够将某列中数据按字符分割成多行,利用这个函数能够快速提取富集到通路的相关基因。
> data
# A tibble: 1 x 2
GO Gene_ID
1 Go1 Gene 1;Gene 2;Gene 3
> data %>% separate_rows(Gene_ID,sep=";")
# A tibble: 3 x 2
GO Gene_ID
1 Go1 Gene 1
2 Go1 Gene 2
3 Go1 Gene 3
好了,今天tidyverse包的简单使用就介绍到这。如果你觉得上面的操作不能满足你的分析需要,你可以访问我们的百迈客云平台,上面有诸多工具,总有一款适合你https://international.biocloud.net/zh/software/tools/list。
参考书籍:
1. Hadley Wickham: R for Data Science.