1月27日,被称为“东方神秘力量”的DeepSeek,在资本市场掀起了滔天巨浪。
由于DeepSeek通过结构化稀疏注意力、混合专家系统、动态计算路由等技术,显著降低了模型训练和推理的算力消耗,由此引发了市场关于算力需求下降的担忧。
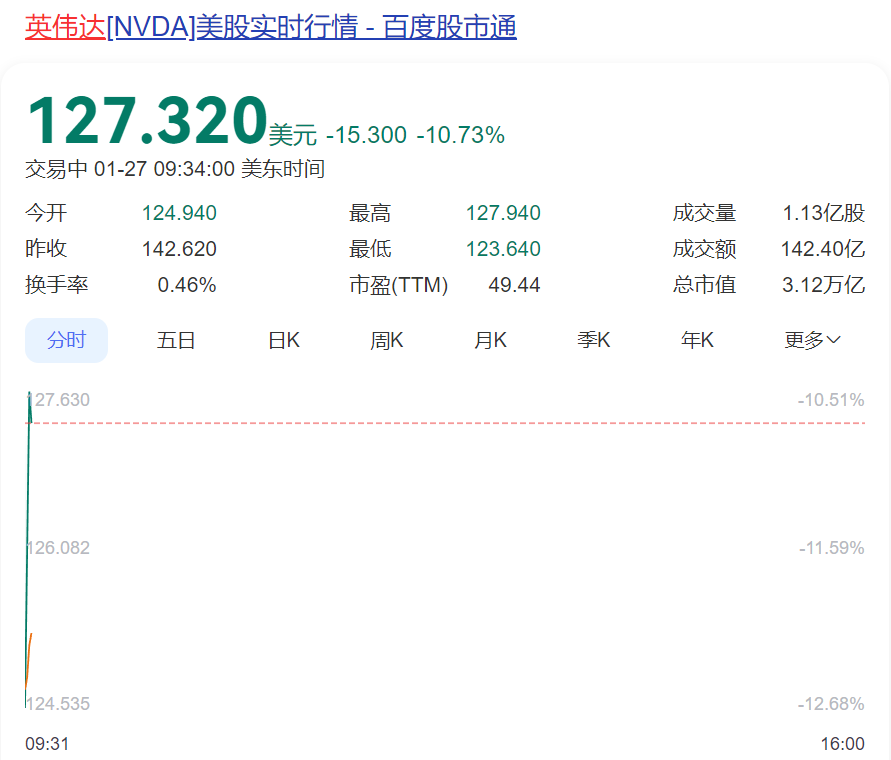
受此影响,美股科技巨头股价开盘集体大跌,英伟达跌超10%,市值蒸发超3500亿美元(约合人民币2.5万亿元)。台积电跌超8%、博通跌超11%、光刻机巨头阿斯麦(AMSL)跌超7%,微软、甲骨文、Meta等也纷纷下跌。
美股三大指数齐跌,纳指跌超3%。

不过DeepSeek自己对此却有不同看法,其表示英伟达股价暴跌与它无关。

AMD火速站台
DeepSeek威胁到英伟达?
消息面上,1月27日,DeepSeek应用登顶苹果美国地区应用商店免费APP下载排行榜,在美区下载榜上超越了ChatGPT。同日,苹果中国区应用商店免费榜显示,DeepSeek成为中国区第一。
此外,1月27日,据外媒报道,Meta成立了四个专门研究小组来研究量化巨头幻方量化旗下的国产大模型DeepSeek的工作原理,并基于此来改进旗下大模型Llama。 其中两个小组正在试图了解幻方量化如何降低训练和运行DeepSeek的成本;第三个研究小组则正在研究幻方量化可能使用了哪些数据来训练其模型;第四个小组正在考虑基于DeepSeek模型属性重构Meta模型的新技术。
据广州日报,“DeepSeek爆火的原因主要可以归结为两点:性能和成本。”萨摩耶云科技集团首席经济学家郑磊告诉记者。DeepSeek解释称,R1在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。这种卓越的性能不仅吸引了科技界的广泛关注,也让投资界看到了其巨大的商业潜力。
最受各界关注的是,DeepSeek R1真正与众不同之处在于它的成本——或者说成本很低。DeepSeek的R1的预训练费用只有557.6万美元,仅是OpenAI GPT-4o模型训练成本的不到十分之一。同时,DeepSeek公布了API的定价,每百万输入tokens 1元(缓存命中)/4元(缓存未命中),每百万输出tokens 16元。这个收费大约是OpenAI o1运行成本的三十分之一。
OpenAI的成功来自“大力出奇迹”路线,以规模作为大模型的制胜法宝。但这也让AI大模型的发展陷入了一个怪圈:为追求更高的性能,模型体积不断膨胀,参数数量呈现指数级增长。这种“军备竞赛”型开发模式,带来了惊人的能源消耗和训练成本,难以为继。受大模型训练的高昂成本拖累,OpenAI在2024年的亏损额可能达到50亿美元,业内专家预计到2026年其亏损将进一步攀升至140亿美元。
DeepSeek的低成本意味着,大模型对算力投入的需求可能会从训练侧向推理侧倾斜,即未来对推理算力的需求将成为主要驱动力。而英伟达等硬件商的传统优势更多集中在训练侧,这可能会对其市场地位和战略布局产生影响。
DeepSeek-V3在仅使用2048块H800 GPU的情况下,完成了6710亿参数模型的训练,成本仅为557.6万美元,远低于其他顶级模型的训练成本(如GPT-4的10亿美元)。因此,一些人认为,DeepSeek可能会颠覆英伟达在AI硬件领域的主导地位。
而就在1月25日,英伟达的“老对手”AMD还火速为DeepSeek“站台”,宣布全新的DeepSeek-V3模型已集成至AMD InstinctGPU上。美国私人投资基金Noah's Arc Capital Management认为,DeepSeek-V3模型的突破显著降低了AI培训成本,使AMD GPU成为比英伟达更具有成本效益的替代品,增强了AMD的市场地位。
值得注意的是,DeepSeek创始人梁文锋生于1985年,是浙江大学信息与通信工程专业的硕士,在他带领下的DeepSeek对人才极其看重,不看经验,只看能力。据多位与DeepSeek有过接触的行业人士表述,DeepSeek的优势之处就在于人才密度极高,且多来自于中国本土市场。DeepSeek团队规模并不大,不到140人,工程师和研发人员几乎都来自清北等国内顶尖高校,鲜有“海归”,而且工作时间都不长,不少还是在读博士。
“美国股市最大的威胁”
DeepSeek冲击“算力竞赛”?
海外媒体Vital Knowledge,德国世界报知名市场评论员Holger Zschaepitz,都不约而同地把DeepSeek称之为“美国股市最大的威胁”。
微软CEO纳德拉近日在达沃斯一档访谈节目中表示,中国的Deepseek发展非常迅速,在推理时间上表现出色,计算效率极高。
美股大V“THE SHORT BEAR”在社交媒体上表示,DeepSeek创造了一个AI巨头们的痛苦时刻,而投资者必须对此敲响警钟,“根据红杉,美国AI公司每年必须产生约6000亿美元收入来支付其AI硬件费用。但现在看来,这种冒险行为变得越来越无利可图。”

图片来源:X
海外知名财经博客Zerohedge1月24日撰文称,DeepSeek的出现和其廉价的训练成本,正在对美国此前宣布的5000亿美元AI基建计划形成巨大的打击。
对此,1月25日,摩根大通分析师Joshua Meyers在标题为《通过DeepSeek的叙述思考——风险是真实的吗?》的研报中写道,虽然目前还不清楚DeepSeek在多大程度上利用了High-Flyer的约50k hopper GPU(与OpenAI据信正在训练GPT-5的集群规模类似),但似乎很有可能的是,他们正在大幅降低成本(例如,其V2模型的推理成本据称是GPT-4 Turbo的1/7)。DeepSeek颠覆性的主张是“更多的投资并不等于更多的创新”,这一主张开始在美国AI领域引起关注。
不过,在Joshua Meyers看来,这(DeepSeek的低成本)并不意味着(AI领域)扩张的终结,也不意味着不再需要更多的算力,更不意味着投入最多资金的一方不会获胜(24日扎克伯格还大幅提高了Meta人工智能的资本支出)。相反,这似乎将迫使中国的竞争对手提高效率:“DeepSeek-V2能够达到令人难以置信的训练效率,在所需算力只有Meta的Llama 3 70B 1/5的情况下,其性能比其他开源模型更好。此外,DeepSeek-V2训练所需的算力是GPT-4的1/20,而性能却相差不大。”如果DeepSeek能够降低推理成本,那么其他公司也将不得不效仿。
国外媒体也纷纷聚焦DeepSeek,并一致认为中国大模型的新进展为硅谷敲响了警钟。1月22日,美国媒体Business Insider报道称,DeepSeek-R1模型秉承开放精神,完全开源,为美国AI玩家带来了麻烦。开源的先进AI可能挑战那些试图通过出售技术赚取巨额利润的公司。

1月24日,美国媒体CNBC推出了长达40分钟的节目,邀请了Perplexity CEO Aravind Srinivas来分析为何DeepSeek会引发人们对美国在AI领域的全球领先地位是否正在缩小的担忧。
英国《金融时报》1月25日报道称,中国小型AI初创公司DeepSeek震惊硅谷。报道聚焦资源更丰富的美国AI公司能否捍卫自己的技术优势。

报道援引加州大学伯克利分校AI政策研究员Ritwik Gupta称,DeepSeek最近发布的模型表明“AI能力没有护城河”。Gupta补充说,中国的系统工程师人才库比美国大得多,他们懂得如何充分利用计算资源来更便宜地训练和运行模型。
对于“DeepSeek会威胁美国的AI霸权吗?”这一问题,DeepSeek自己给出的回答是:当前AI竞争已进入"马拉松式"的技术耐力赛。DeepSeek等中国企业的崛起,标志着全球AI发展正从单极主导转向多极化格局。但真正改变技术权力结构,仍需在基础理论突破、通用人工智能(AGI)等前沿领域取得实质性进展。未来5-10年,更可能形成"中美双核,差异发展"的态势,而非简单的霸权更替。这场竞赛的最终结果,将取决于持续创新能力的维持、产学研协同效率的提升,以及全球化协作与自主创新的动态平衡。

(声明:文章内容和数据仅供参考,不构成投资建议。投资者据此操作,风险自担。)