就在刚刚,Claude 3.7 Sonnet 正式发布。
作为 Claude 有史以来最智能的模型,它采用混合推理方式,既能快速生成响应,也能进行深入的逐步推理。
一个模型,两种思考模式。
此外, Anthropic 还发布了一款智能编程工具——Claude Code。
官方表示,Claude 3.7 Sonnet 和 Claude Code 标志着 AI 迈向真正增强人类能力的重要一步,不仅能深入推理、独立执行任务,还能高效协作,让 AI 在现实世界中发挥更大价值。
太长不看,省流版如下:
Claude 3.7 Sonnet:全球首款双模式混合推理模型,标准模式快速响应,扩展思考模式进行深度自我反思,在数学、物理和编程等复杂任务上表现卓越,注重实用导向,不必要拒绝减少 45%,强化代码协作能力
Claude Code:直接在终端理解并操作代码库,能一次完成需 45 分钟以上的人工编程任务,专长于测试驱动开发、复杂调试和大规模代码重构,全面支持代码编辑、测试执行等核心开发流程

全球首款混合推理模型发布,你的 Claude 会思考了
新发布的 Claude 3.7 Sonnet 不仅引入了详细的逐步推理,而且也公开了「思考」过程。 感谢 DeepS e ek 的内卷,推动了行业透明度的提升。
就像人类用同一个大脑既能快速反应,又能深入思考一样,Anthropic 同样认为推理能力不应依赖于单独的模型。
最好是,一个模型搞定所有场景。
用户可以自由选择是让 Claude 3.7 Sonnet 快速作答,还是让其进行更长时间的深度思考。
在标准模式下,它是 Claude 3.5 Sonnet 的升级版;切换到扩展思考(Extended Thinking)模式(可简单理解为推理),它会在回答前进行自我反思,大幅提升在数学、物理、指令理解和编程等复杂任务上的表现。

从基准测试结果来看,Claude 3.7 Sonnet(扩展思维版)适用于强逻辑推理和数学任务,而 Grok 3 Beta 和 DeepSeek R1 则在特定任务(推理、数学竞赛)上表现更佳。
DeepSeek R1 在数学解题能力(97.3%)方面最强,同时在其他任务上也有不错的表现。
在推理模型的优化过程中,Anthropic 减少了对数学和计算机科学竞赛问题的侧重,更专注于满足企业对 LLM 的实际应用需求。

在评估 AI 解决真实软件问题能力的 SWE-bench Verified 基准测试中,Claude 3.7 Sonnet 达到了行业领先水平。同时,该模型在 TAU-bench 测试中也表现不错,拳打旧版本,脚踢 OpenAI o1。

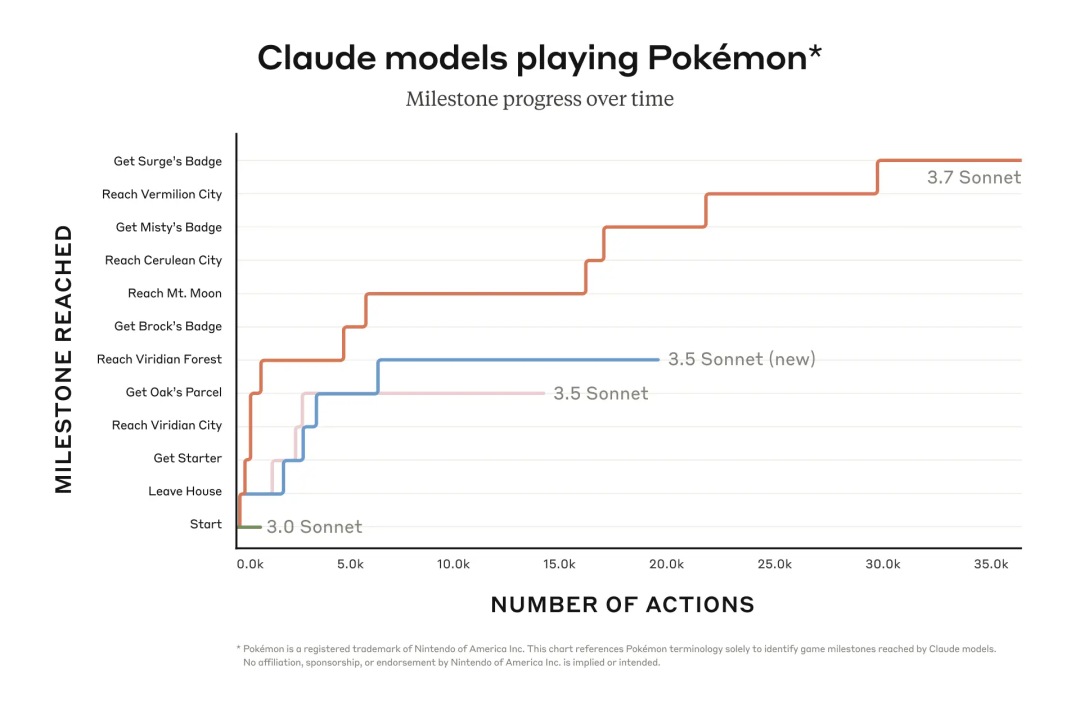
值得一提的是,Claude 3.7 Sonnet 在 Anthropic 内部的 Pokémon 游戏测试中超越了所有前代模型,展现了更强的决策与规划能力。
该模型现已适用于所有 Claude 订阅计划,包括免费版、专业版、团队版和企业版,同时也可通过 Anthropic API、Amazon Bedrock 和 Google Cloud 的Vertex AI 访问。
值得注意的是,除免费版外,所有平台均支持扩展思考模式(Extended Thinking Mode)。
当通过 API 使用 Claude 3.7 Sonnet 时,你还可以告诉 Claude 思考不超过 N 个 token。对于任何 N 值,其输出限制为 128K 个 token。
无论使用哪种模式,定价与前代模型保持一致。输入 100 万个 token 收费 3 美元,输出 100 万个 token(包括思考过程中使用的 token)收费 15 美元。

一直以来,Claude 的编程能力编程能力都挺拿得出手,也因此成为许多开发者的首选模型,现在,新发布的 Claude 3.7 Sonnet 进一步放大了这个优势。
Cursor、Cognition、Vercel、Replit和 Canva 等公司均确认该模型在处理复杂代码库、高级工具使用、代码修改规划和全栈更新处理等方面表现出色。
为了优化用户体验, GitHub 集成功能已向所有订阅计划开放,开发者可以直接将代码库连接到 Claude,实现更高效的协作。
无论是修复 Bug、开发新功能还是完善文档,Claude 3.7 Sonnet 都能为个人项目和企业级 GitHub 代码库提供更好的支持。

在安全性方面,通过与外部专家合作,相比前代模型, Claude 3.7 Sonnet 据说能更准确地区分恶意请求和正常请求,不必要的拒绝减少了 45%,能够提供更流畅的交互体验。

截取自 Claude 3.7 Sonnet 系统卡
代码写到一半想放弃?试试把复杂问题甩给 Claude Code
Anthropic 还推出了一款智能编程工具——Claude Code, 目前仅作为研究预览版限量开放。
代码写到一半想放弃?开发者可以直接在终端中将这些复杂问题交给 Claude Code 处理。
Claude Code 是一个主动协作的 AI 编程助手,能够搜索和阅读代码、编辑文件、编写并运行测试、提交和推送代码到 GitHub,以及使用命令行工具等。

据 Anthropic 官方介绍, 在早期测试中,Claude Code 能一次性完成通常需要 45 分钟以上的人工任务,特别是在测试驱动开发(TDD)、调试复杂问题和大规模重构方面表现突出。

Claude Code 能够直接理解开发者的代码库,并通过自然语言命令帮助用户更高效地编码。 它可以无缝集成到开发环境中,无需额外的服务器或复杂的配置,极大地简化了工作流程。
其核心功能包括编辑文件、修复 Bug、回答关于代码架构和逻辑的问题、执行测试、修复测试错误、进行代码格式检查,以及搜索 Git 历史记录、解决合并冲突、创建提交和拉取请求等。

Anthropic 表示,在接下来的几周内,他们计划持续优化 Claude Code,重点改进包括提升工具调用的稳定性、支持长时间运行的命令、改进应用内的渲染效果,以及增强 Claude 对自身能力的理解。
这次发布预览研究版本也是希望深入了解开发者如何使用 Claude 进行编程,从而为进一步优化未来的模型版本提供参考。
感兴趣的开发者在官方网站查看相关事项,指路 👇
https://docs.anthropic.com/en/docs/agents-and-tools/claude-code/overview
AI 发展速度太快,连起名都跟不上了?
X 网友倒是用上了,不过注意点有点偏差,一年前编写的越狱提示词还能用上。

询问 strawberry 里有多少个 r,Claude Sonnet 3.7 虽然答错了,但官方似乎特意给这个问题里埋了一个彩蛋。不得不说,官方是懂怎么玩梗的。

知名博主 @rowancheung 提前用上了 Claude 3.7 Sonnet,并盛赞该模型为世界上最好的编码 AI 模型,在接收到一个简单的指令后,就生成了一个类似 Minecraft 的游戏,并且可即刻运行。

耗费的推理 Token 越多,Claude 3.7 Sonnet 绘制的「彩虹独角兽」效果越好。

我们也简单上手体验了一下 Claude 3.7 Sonnet。

在模型选择栏切换点击「Extended」,即可进入扩展思考模式。

烧一根不均匀的绳要用一个小时,如何用它来判断半个小时?烧一根不均匀的绳,从头烧到尾总共需要一个小时。现在有若干条材质相同的绳子,问如何用烧绳的方法来计时一个小时十五分钟呢?
一道简单的推理题,差点把 Claude 3.7 Sonnet 的 CPU 干烧了。

相信你已经注意到, 与 DeepSeek R1 展示的思考过程相比,Claude 3.7 Sonnet 公开的思考过程相对客观、缺乏个性化表达。
然而,这是有意为之的设计。
Anthropic 没有对模型的思维过程进行标准角色训练,而是希望给予 Claude 最大自由度进行自主思考,但就像人类思维一样,这可能包含不完全正确或尚未成熟的想法。
并且,Anthropic 认为所谓「思考」过程不一定真实反映了 AI 的内部决策逻辑,因此, Anthropic 未来将基于用户反馈和研究决定是否继续公开 Claude 的思维链。
有趣的是,我们之前提到过,随着各家新模型的相继发布,各类版本号和命名规则也是让人眼花缭乱。
去年当 OpenAI CEO Sam Altman 被问及公司产品的命名策略时,他也坦言相当头疼。 Anthropic CEO Amodei 曾表示,虽然 Claude 的命名方式在早期看起来不错,但随着模型的快速迭代和更新,沿用的命名体系同样变得捉襟见肘。
他指出,目前没有任何 AI 公司真正「搞定命名」这一问题,大家都在努力寻找更简单、更清晰的命名方式。这或许是 AI 巨头们少有达成的共识。
Anthropic 首席产品官 Mike Krieger 今天也在 X 平台公布了 Claude 3.7 Sonnet 的幕后命名花絮。 内心的纠结过程大概是这样👇
