皮衣老黄,带着最强AI芯片GB300闪亮登场“AI超级碗”GTC,燃爆全场!

性能方面,和去年发布的GB200相比,推理性能是其1.5倍。

据悉,GB300将在今年的下半年出货。
除此之外,老黄还预览(2026年下半年发货)了英伟达下一代AI超级芯片,名字大变样——Vera Rubin。

其实它的命名规则和Grace Blackwell(GB)类似:Grace是CPU,Blackwell是GPU。
而Vera Rubin中的Vera是CPU,Rubin是GPU。根据老黄的说法:
几乎所有细节都是新的。
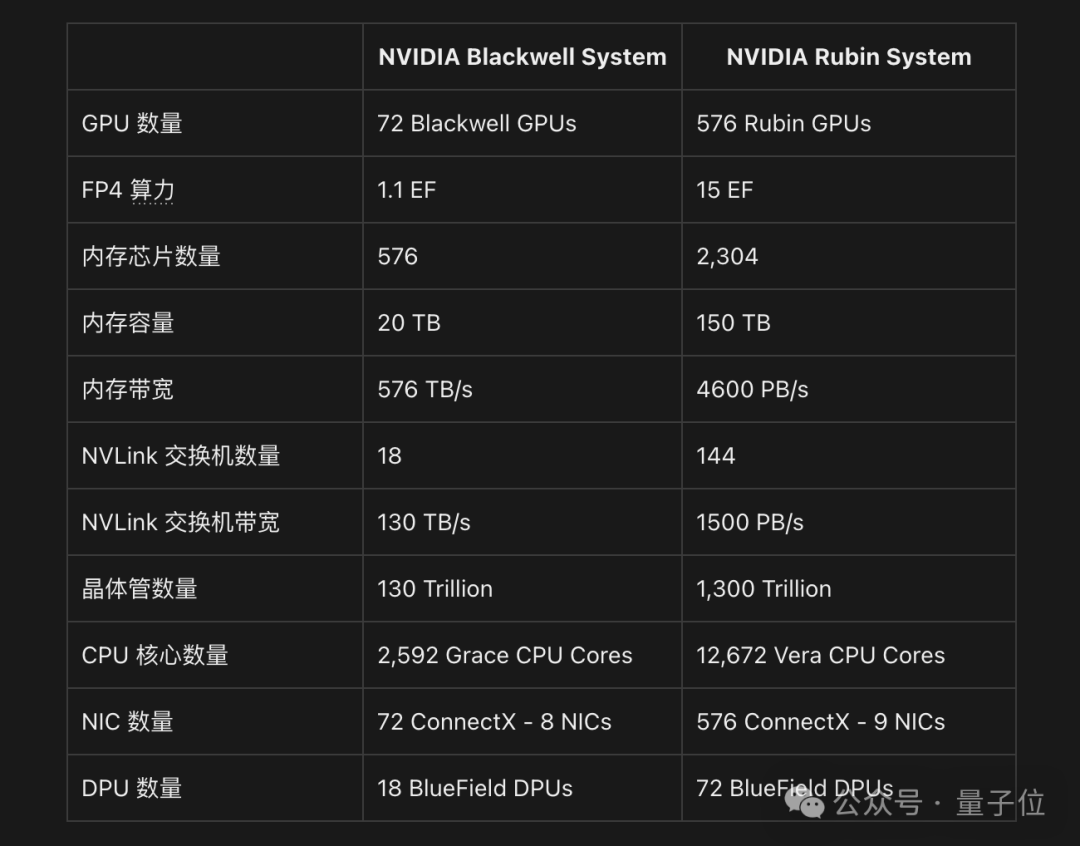
从预览的性能来看,Vera Rubin整体性能更是GB300的3.3倍。更具体一些:
Vera:CPU的内存是Grace的4.2倍,内存带宽是Grace的2.4倍。
Rubin:将配备288GB的HBM4。
在Vera Rubin之后的下一代GPU(2027年下半年),英伟达会将其命名为Rubin Ultra,性能直接拉到GB300的14倍。

一个直观的对比,如下图所示:

更多的具体性能对比,是这样的:
性能上的提升,也正应了老黄在现场说的那句话:
大规模推理是一种极限计算。
Inference at-scale is extreme computing.
不仅如此,就连Rubin之后的下一代GPU,老黄也给亮出来了——将以Feynman来命名。

而纵观整场GTC,我们可以轻松提炼老黄提及最多的几个关键词:tokens、推理和Agentic AI。
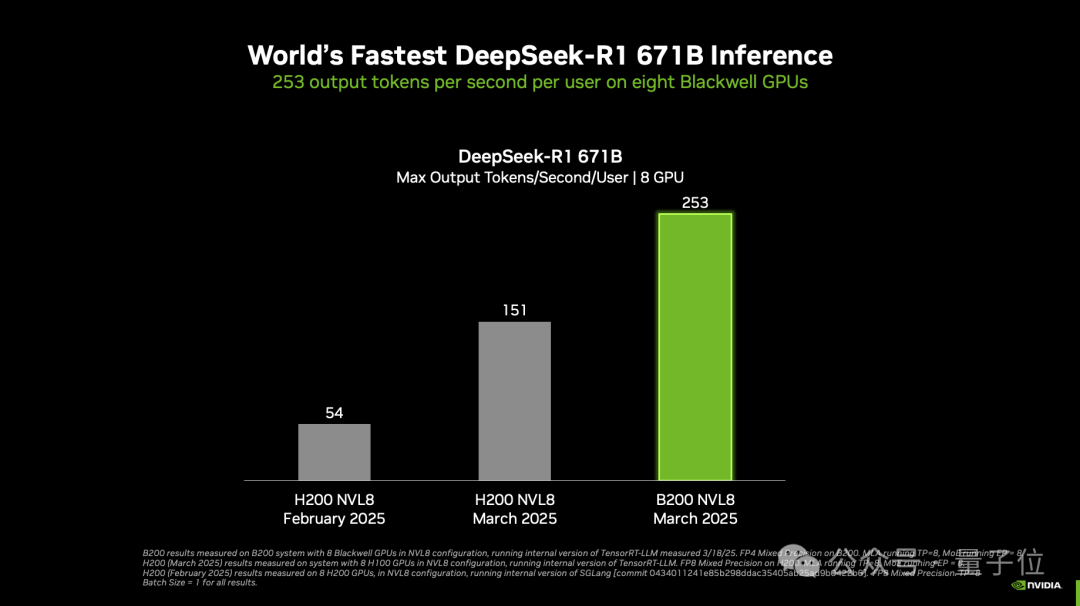
但除此之外,还有一个比较有意思的关键词——DeepSeek。
英伟达官方博客称:
实现了DeepSeek-R1推理性能世界纪录。
每个用户每秒可处理超过250个token;实现每秒超过30000个token的最大吞吐量。

但这项纪录采用的是B200,英伟达表示随着Blackwell Ultra等新GPU的出现,纪录还将继续被打破。
而老黄在现场体现传统LLM和推理LLM的区别时,也是拿着DeepSeek-R1来举例:

嗯,微妙,着实有点微妙。
那么除了一系列新GPU之外,还有什么?我们继续往下看。
推出两款个人AI超级计算机
首先,第一款个人AI超级计算机,叫做DGX Spark。
它就是老黄在今年1月份CES中发布的那个全球最小的个人AI超级计算机Project Digits,这次取了个正式的名字。
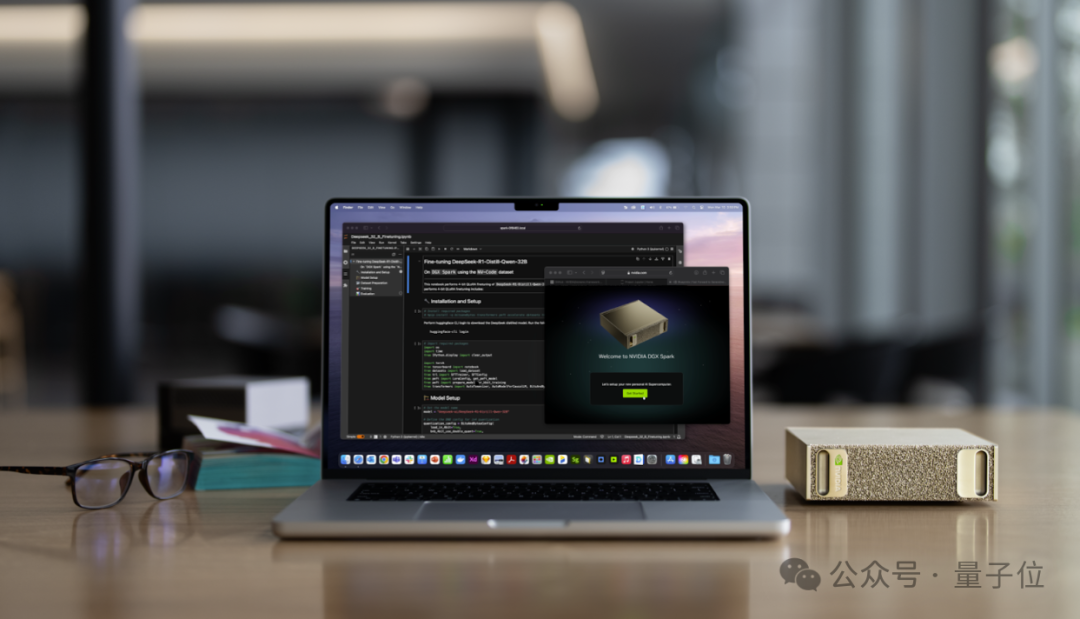
DGX Spark售价3000美元(约21685元),大小和Mac Mini相当。
它采用的是英伟达GB10芯片,能够提供每秒1000万亿次的AI运算,用于微调和推理最新AI模型。
其中,GB10采用了NVLink-C2C互连技术,提供CPU+ gpu的相干内存模型,带宽是第五代PCIe的5倍。
值得一提的是,英伟达官网已经开发预定了哦~
至于第二款个人AI超级电脑,则是DGX Station。

DGX Station所采用的,正是今天推出的GB300,也是首个采用这款芯片的AI电脑。
其性能如下:
拥有784GB的相干内存空间
拥有英伟达的ConnectX-8超级网卡,支持高达800Gb/s的网络速度
拥有Nvidia的CUDA-X AI平台,可访问NIM微服务和AI Enterprise
用老黄的话来说就是:
这就是PC应该有的样子。
This is what a PC should look like.
至于上市赶时间,则是将于今年晚些时候从华硕、BOXX、戴尔、惠普、Lambda和美超微等厂商处推出。
 △
△
搭载GB300的DGX Station主板
而根据英伟达官方的介绍,这两款个人AI超级计算机,是面向研究人员、数据科学家、AI开发者和学生设计的。

除此之外,老黄在这届GTC上还涉足了以太网,推出全球首个面向AI的以太网网络平台——Spectrum-X。
它由英伟达的Spectrum-4以太网交换机和BlueField-3 SuperNIC共同发力,能为AI、机器学习和自然语言处理等提供高性能支持。
相比传统以太网,Spectrum-X可将AI网络性能提升1.6倍,提高AI云的电力效率。

以及还包括基于硅光学的Spectrum-X Photonics和Quantum-X Photonics网络交换平台,用于使用硅光学的超大规模数据中心。
新的网络交换平台将端口数据传输速度提升至1.6Tb/s,总传输速度达到400Tb/s,使数百万个GPU能够无缝协同工作。

还开源了一系列软件
除了硬件,英伟达这次在软件开源方面也有几个新动作。
其中最重磅的,当属发布NVIDIA Dyamo,一个用于加速AI模型推理的分布式推理服务库。
老黄将其称为“AI工厂的操作系统”,核心目标在于提高推理性能的同时降低Test-Time算力消耗。
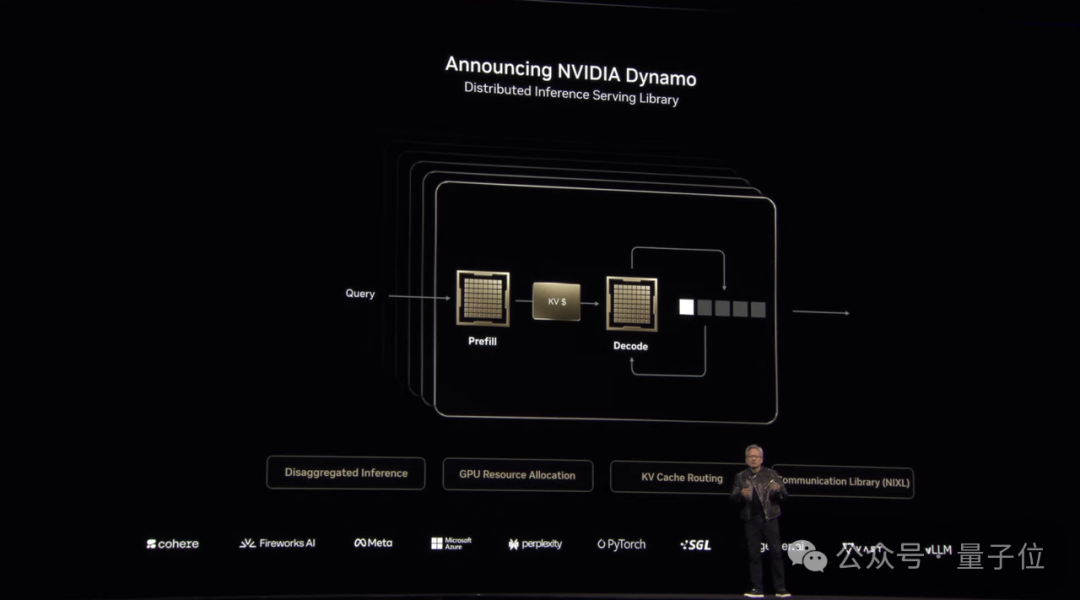
按照英伟达的说法,在NVIDIA Blackwell上使用Dynamo优化推理,能让DeepSeek-R1的吞吐量提升30倍。

至于背后原因,主要在于Dynamo可以通过动态调整GPU资源应对请求波动,并优化数据卸载到成本更低的存储设备,从而降低推理成本并提高效率。
目前Dynamo已完全开源,支持PyTorch、SGLang、NVIDIA TensorRTyTM以及vLLM,在GitHub获取后即可将推理工作分配到多达1000个NVIDIA GPU芯片。
此外,英伟达还宣布开源新的AI推理模型——Llama Nemotron,该系列模型也曾出现在今年1月的CES上。
据介绍,Llama Nemotron基于开源Llama基础模型构建,采用英伟达最新技术和高质量数据集进行剪枝和训练,优化了计算效率和准确性。
为了直观展示其性能,老黄在大会上将它和Llama 3.3(70B)以及DeepSeek R1 Llama (70B)进行了对比,下图展示了它们在Agentic任务上的平均准确率(横轴)与每秒处理的tokens数量(纵轴):
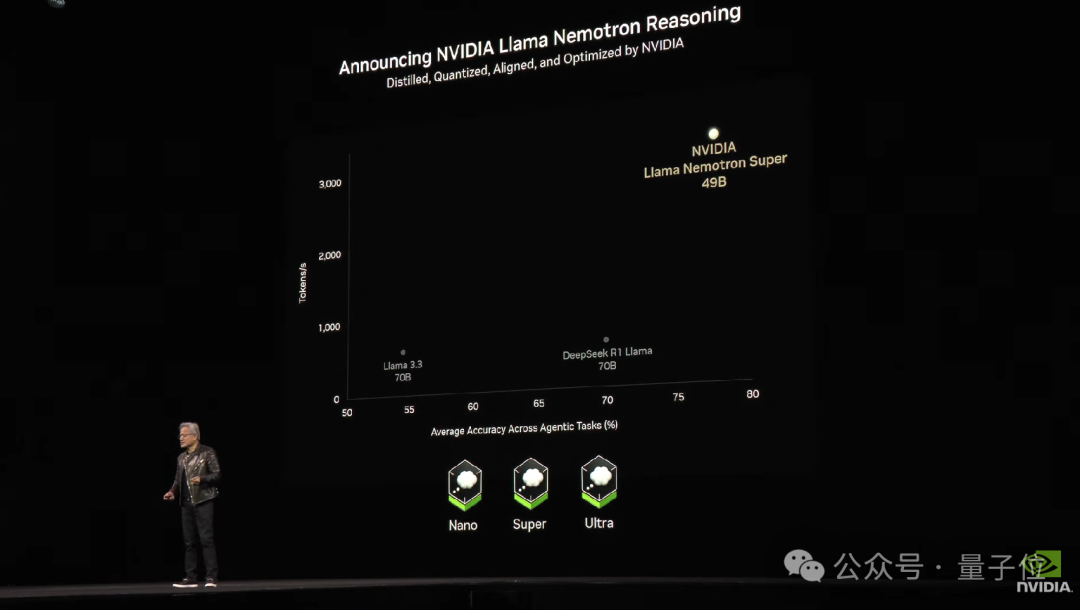
可以看出,新的推理模型以49B参数量性能远超另外两个模型,在Agentic任务中表现更为突出。
目前Nano和Super模型可在NIM微服务中获取,Ultra模型即将推出。
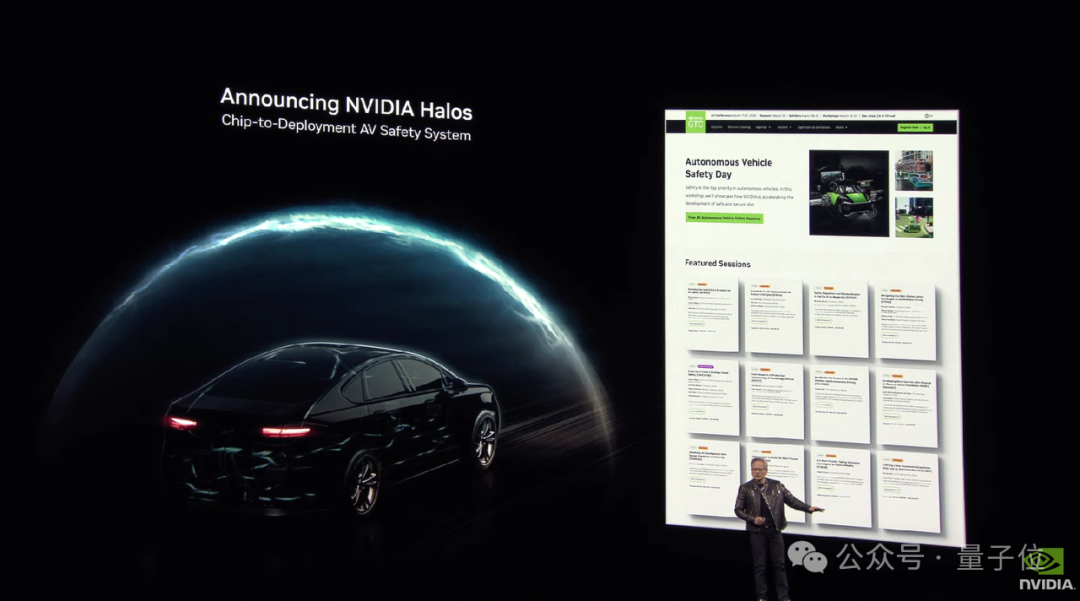
与此同时,英伟达在自动驾驶和具身智能方面也有新进展。
大会开始不久,老黄即宣布英伟达与通用汽车达成合作:
通用将在自动驾驶上使用英伟达的AI技术。

在这之后,英伟达正式发布了端到端自动驾驶汽车全栈综合安全系统NVIDIA Halos。
这个系统主要将NVIDIA的汽车硬件和软件解决方案与尖端AI研究相结合,以确保从云端到车辆的自动驾驶汽车(AVs)的安全开发。
介绍过程中,老黄多次提到了“安全性”这个词,并公开声称:
我们是世界上第一家对每一行代码进行安全评估的公司
落实到具体上,Halos系统主要在三个互补的层面提供支持:
技术层面:包括平台安全、算法安全和生态系统安全;
开发层面:涵盖设计阶段、部署阶段和验证阶段的安全防护措施;
计算层面:从AI训练到部署的全过程,利用三种强大的计算平台,分别是NVIDIA DGX用于AI训练,NVIDIA Omniverse和NVIDIA Cosmos在NVIDIA OVX上运行用于模拟,以及NVIDIA DRIVE AGX用于部署。
到了大会的最后阶段,老黄宣布英伟达与Google DeepMind和Disney Research正合作开发下一代开源仿真物理模型Newton。
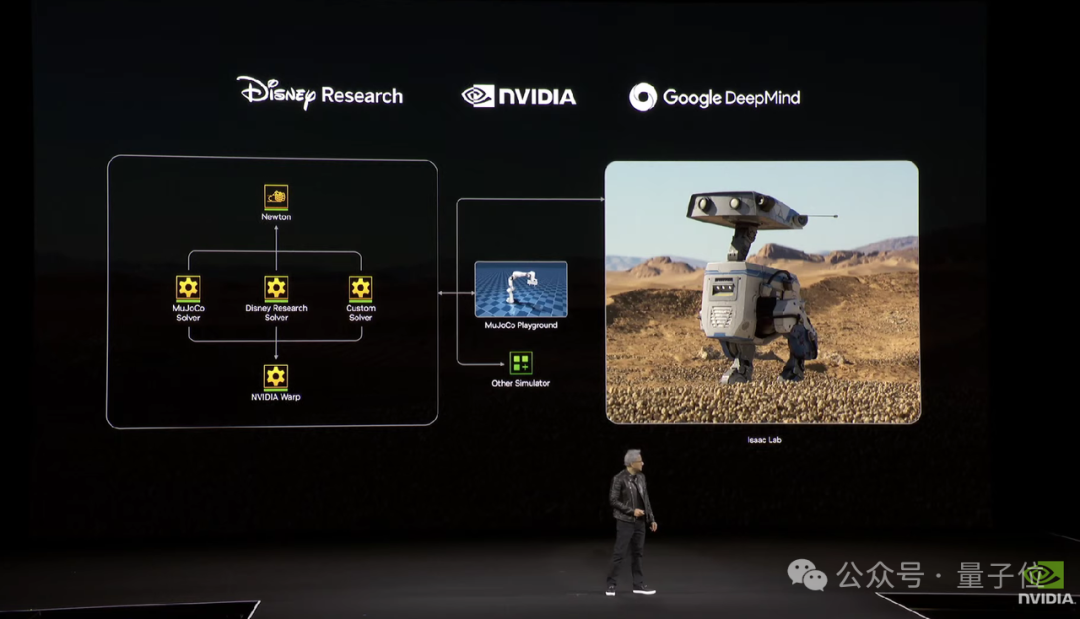
据英伟达介绍,Newton基于NVIDIA Warp构建,支持与MuJoCo Playground或NVIDIA Isaac Lab等学习框架兼容。
它主要用于机器人模拟训练,使用之后可以帮助研究人员安全、加速且低成本地训练/开发/测试/验证机器人控制算法和原型设计。

同时,英伟达还同步推出了 Isaac GR00T N1,号称全球首个开源的、完全可定制的人形机器人基础模型。
它采用双系统架构,灵感来自人类思考模式,包括快速思考的动作模型(System 1)和慢速思考的决策模型(System 2)。
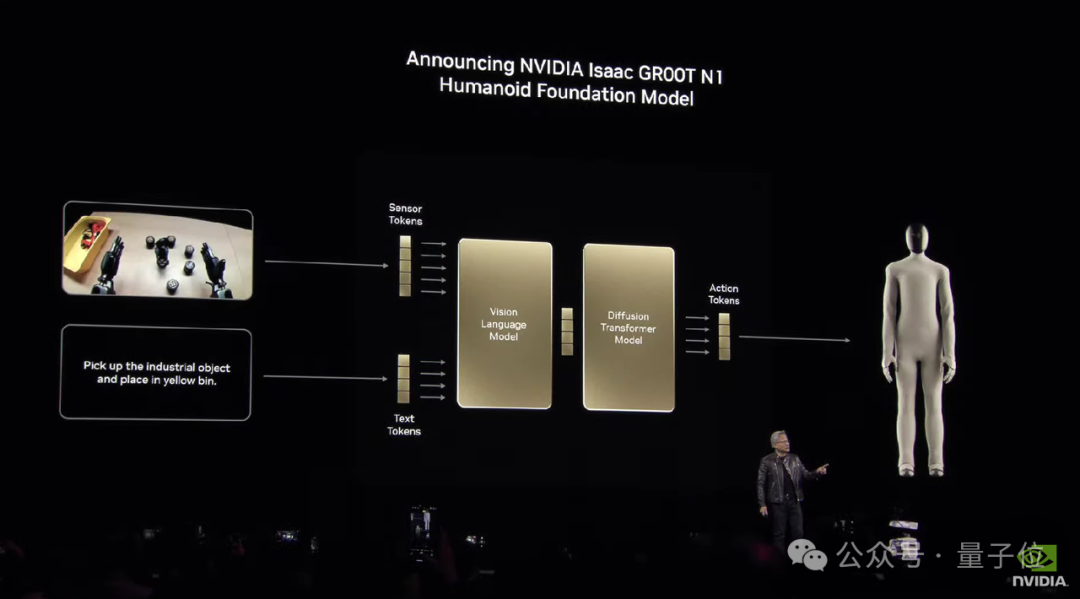
在大会演示中,GR00T N1能够轻松泛化常见的任务,如抓取、移动物体以及在双臂之间转移物品,或执行需要长时间推理的复杂任务。

最后的最后,老黄在谢幕之前还成功“召唤”出了配有GR00T N1模型的机器人——Blue(星球大战机器人)。

虽然过程中有些不听话的“叛逆行为”,但好在还是给了点老黄面子(doge)。

One More Thing
今年的GTC大会,除了老黄的主题演讲,还有一件事最值得期待:
那就是今年首次设立的“量子日”活动,届时老黄将与D-Wave Quantum和Rigetti Computing等十余家量子计算行业领军企业的高管同台,讨论量子计算的技术现状、潜力以及未来发展方向。
要知道今年年初时,老黄一句“量子计算还需20年才实用”,相关概念股曾应声腰斩。
所以大家这次都在观望,老黄是否又会“语出惊人”,相关探讨是否会对量子计算产业产生更大影响。
咱们继续坐等答案揭晓~