随着大语言模型(LLM)在各行业的广泛应用,模型规模与计算复杂度持续增长,对硬件性能与能效提出了更高要求。
在边缘侧部署LLM可以带来低延时、本地隐私等优势,但受限于设备功耗和内存,推理过程常面临挑战。
NVIDIA Jetson 系列作为领先的边缘 AI 平台,凭借强大的算力(如 Orin 系列搭载的 Arm CPU、Ampere 架构 GPU 以及高达 64GB 的内存),为在终端设备上运行复杂的 AI 模型提供了坚实基础。
然而,要在 Jetson 上高效运行大语言模型(LLM),仍需依赖专业的优化技术,以突破资源限制,实现流畅稳定的推理性能。
在此背景下,TensorRT-LLM诞生了
为了解决大模型部署的效率难题, NVIDIA推出了TensorRT-LLM——专为LLM优化的官方高性能推理解决方案 。
TensorRT-LLM结合了FasterTransformer库卓越性能和TensorRT引擎的可扩展性,提供大量针对LLM的专有优化特性,并与NVIDIA Triton推理服务器深度集成,使先进的LLM在端到端推理中发挥出更优异的性能 。
作为 NVIDIA支持的开源库, TensorRT-LLM已经集成到NeMo框架中,经过充分调校和测试,可靠性有保障 。
从JetPack 6.1开始, TensorRT-LLM正式支持在Jetson Orin系列设备上部署, NVIDIA还提供了预编译好的Wheel包和容器,方便开发者开箱即用。
TensorRT-LLM可部署于T930、T930G、T906、T906G、T919、T902,部署之后会收获什么神奇的效果。



显著的推理速度优势
在LLM推理速度方面, TensorRT-LLM展现出远超其他方案的优势。
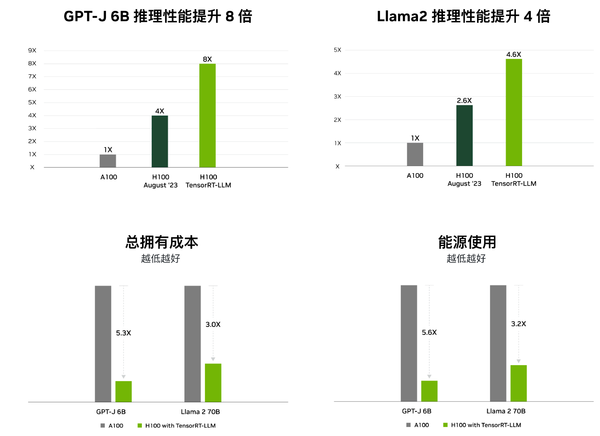
官方数据
01
吞吐量提升高达 8 倍
相比传统方法,推理速度显著加快
02
延迟降低至原来的 1/6
响应更迅速,用户体验更佳。
03
能效比提升近 6 倍
在保持高性能的同时,大幅降低能耗。
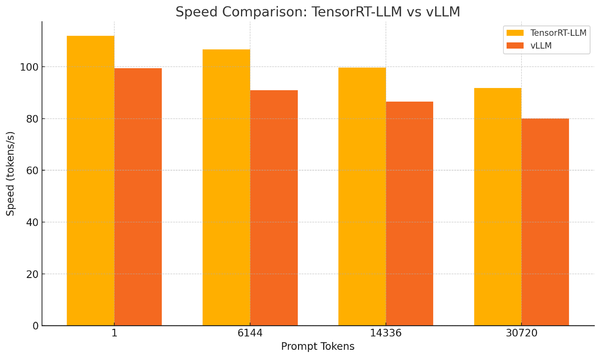
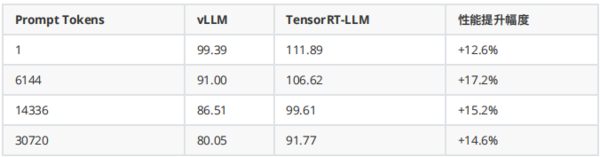
实际测试数据
NVIDIA 原生推出的 TensorRT-LLM 展现出卓越的性能表现。
相比主流推理框架 vLLM ,TensorRT-LLM 在不同长度的 Prompt 输入下,推理速度提升高达 17.2% ,显著提升了模型的推理速度。
多样化模型支持灵活部署
TensorRT-LLM 支持多种主流 LLM 架构,包括但不限于:
1.LLaMA系列模型
2.Mistral 、Falcon 、BERT 及其变体
3. Qwen系列模型
无论是通用语言理解、代码生成,还是多模态处理, TensorRT-LLM 都能提供高效的推理支持。
高级优化技术释放硬件潜能
TensorRT-LLM 集成了多项先进的优化技术,充分挖掘 Jetson 平台的硬件潜力:
量化支持
支持 FP8 、INT4 、INT8 等多种精度,减少模型大小,提升推理速度。
内存优化
通过分页 KV 缓存等技术,降低内存占用,提升模型加载效率。
推理优化
采用内核融合、动态批处理等方法,提高推理吞吐量。这些优化使得在资源受限的 Jetson 设备上,也能高效运行大型语言模型。
凭借卓越的推理性能和深度的专有优化 ,TensorRT-LLM让Jetson这样的边缘AI平台能够流畅运行大型语言模型。在实际部署中,这意味着企业和开发者可以在功耗、内存有限的环境下,为图为边缘计算机与其他终端设备赋予强大的生成式AI能力。
从智能机器人到实时翻译助手,各种应用都能借助TensorRT-LLM在Jetson上实现低延时、高吞吐的本地LLM推理。作为NVIDIA官方支持的方案, TensorRT-LLM充分发挥了Jetson硬件潜能,让边缘AI推理在性能与效率上实现飞跃 。
(如有侵权,请联系平台删除。)