
先解释概念
Embodied AI = Embodied Intelligence = 具象AI = 具身智能:有身体并支持物理交互的智能体,如家用服务机器人、无人车等。—— “身体力行”
Internet AI = Disembodied AI = 非具身智能:没有物理身体,只能被动接受人类采集、制作好的数据 。—— “纸上谈兵”或者说 “运筹帷幄”
机器人,是人工智能的最终解决方案。
具身智能机器人:首先,要能够听懂人类语言,然后,分解任务,规划子任务,移动中识别物体,与环境交互,最终完成相应任务。
具体点说,像人一样能与环境交互感知,自主规划、决策、行动、执行能力的机器人/仿真人(指虚拟环境中)是AI的终极形态,我们暂且称之为“具身智能机器人”。它的实现包含了人工智能领域内诸多的技术,例如计算机视觉、自然语言处理、机器人学等。要想全面理解认识人工智能是很困难的。
(一)人工智能分支多 目前走向融合
全面认识人工智能之所以困难,是有客观原因的。
1、人工智能是一个非常广泛的领域。当前人工智能涵盖很多大的学科,我把它们归纳为六个:
(1)计算机视觉(暂且把模式识别,图像处理等问题归入其中)、
(2)自然语言理解与交流(暂且把语音识别、合成归入其中,包括对话)、
(3)认知与推理(包含各种物理和社会常识)、
(4)机器人学(机械、控制、设计、运动规划、任务规划等)、
(5)博弈与伦理(多代理人agents的交互、对抗与合作,机器人与社会融合等议题)。
(6)机器学习(各种统计的建模、分析工具和计算的方法),
领域各有大模型,迭代很快,gpt 5甚至能摸到NLP天花板!CV刚刚开始,但目前它们正在交叉发展,走向统一的过程中。
算法层的进步如日中天!
但具有物理实体、能够与真实世界进行多模态交互,像人类一样感知和理解环境,并通过自主学习物理体没有出现!
具身指的不仅仅是具有物理身体,而且是具有与人一样的身体体验的能力。如图中的猫一样,主动猫是具身的智能,它可以在环境中自由行动,从而学习行走的能力。被动猫只能被动的观察世界,最终失去了行走能力。
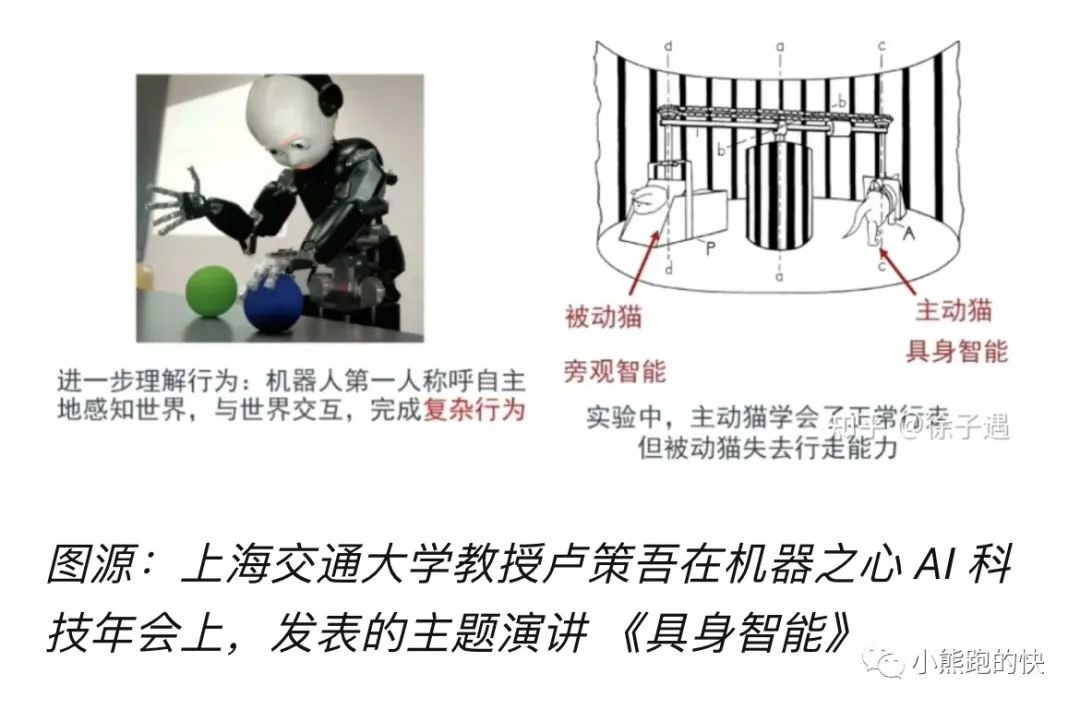
前者有点像我们现在给机器喂很多数据,属于第三人称的智能,比如我们给机器很多盒子,并且标注这就是盒子,然后机器就会觉得这种 pattern 是盒子。但其实,人类是怎么知道这是盒子的?是通过体验才知道的。

第一类就像我们给AI模型喂很多数据,这些数据是人类整理,打过标签的。我们将其定义为Internet AI,与Embodied AI相对应。
谷歌公司 Everyday Robot 的SayCan已经将机器人和对话模型结合到一起[6],能够让机器人在大型语言模型的帮助下,完成一个包含 16 个步骤的长任务。UC 伯克利的 LM Nav 用三个大模型(视觉导航模型 ViNG、大型语言模型 GPT-3、视觉语言模型 CLIP)教会了机器人在不看地图的情况下按照语言指令到达目的地。
(二)具象AI和非具象 AI代际变迁
Internet AI(Disembodied AI)和Embodied AI的辨析
旁观型标签学习方式 v.s. 实践性概念学习方法
Internet AI从互联网收集到的图像、视频或文本数据集中学习,这些数据集往往制作精良,其与真实世界脱节、难以泛化和迁移。1)数据到标签的映射。2)无法在真实世界进行体验学习。3)无法在真实世界做出影响。
Embodied AI通过与环境的互动,虽然以第一视角得到的数据不够稳定,但这种类似于人类的自我中心感知中学习,从而从视觉、语言和推理到一个人工具象(Artificial Embodiment),可以帮助解决更多真实问题。
过去50年,非具身智能就占据了绝对的优势。不需要物理交互、不考虑具体形态、专注抽象算法的开发这一系列有利条件使得非具身智能得以迅速地发展。今天在算力和数据的支持下,深度学习这一强有力的工具大大推进了人工智能研究,非具身智能已经如图灵所愿、近乎完美地解决了下棋、预测蛋白质结构等抽象的独立任务。互联网上充沛的图片和语义标注也使得一系列视觉问题取得了突出的成果。
然而这样的智能显然是有局限的。非具身智能没有自己的眼睛,因此只能被动地接受人类已经采集好的数据。非具身智能没有自己的四肢等执行器官,无法执行任何物理任务,也缺乏相关的任务经验。即使是可以辨识万物的视觉大模型也不知道如何倒一杯水,而缺乏身体力行的过程,使得非具身智能体永远也无法理解事物在物理交互中真实的意义。
具身智能具有支持感觉和运动的物理身体,可以进行主动式感知,也可以执行物理任务,没有非具身智能的诸多局限性。更重要的是,具身智能强调“感知—行动回路”(perception-action loop)的重要性,即感受世界、对世界进行建模、进而采取行动、进行验证并调整模型的过程。这一过程正是“纸上得来终觉浅,绝知此事要躬行”,与我们人类的学习和认知过程一致。
麻省 学者Rodney Brooks 认为智能是在与环境的交互作用中表现出来的,因此是行为产生了智能。其基本观点是让机器人到环境中去,进行物理交互,从而积累和发展初级的智能。他因此将研究的重心放在了具身智能,研究如何让机器人移动和适应环境,于 1986年诞生了第一个基于感知行为模式的轮式机器人。
该机器人不需要中枢控制,实现了避让、前进和平衡等功能。Rodney Brooks 也成为了人工智能和机器人学中行为主义的代表性人物。今天对如何发展真正的智能仍然是一个开放的问题,而具身智能作为符合人类认知规律的一种发展途径也受到了广泛的讨论。
(三)具象AI技术条件成熟
时机成熟:各路大模型 成熟
计算机视觉给具身智能提供了处理视觉信号的能力;
计算机图形学开发的物理仿真环境给具身智能提供了真实物理世界的替代,大大加快了学习的速度并降低了成本;
自然语言给具身智能带来了与人类交流、从自然文本中学习的可能;
认知科学进一步帮助具身智能体理解人类、构建认知和价值。
具象AI实施方案——PIE 方案
具身智能有哪些模块是一定跑不掉的?我们认为有 3 个模块 —— 具身感知(Perception)、具身想象(Imagination)和具身执行(Execution)。

1、全概念感知
首先,我们具身智能的感知应该是什么样的?跟之前计算机视觉的感知有什么不一样?我们觉得它应该是一个全感知。全感知的意思就是,我们能够知道我们所操作的这个世界模型(world model)的各种各样的知识,跟操作相关的知识,包括外形、结构、语义,以及 48 个真实世界关节体类别等等。

2、具身交互感知
具身交互感知是什么呢?我们作交互的时候,其实除了视觉,还有触觉,还有各种内容交互的感觉。这些感觉其实也会带来新的感知。就像我们刚才讲的提一个桶或者打开微波炉,我们其实没办法从视觉上知道大概需要多少牛的力,所以其实很多时候我们对这个模型的估计是通过交互来获得的。
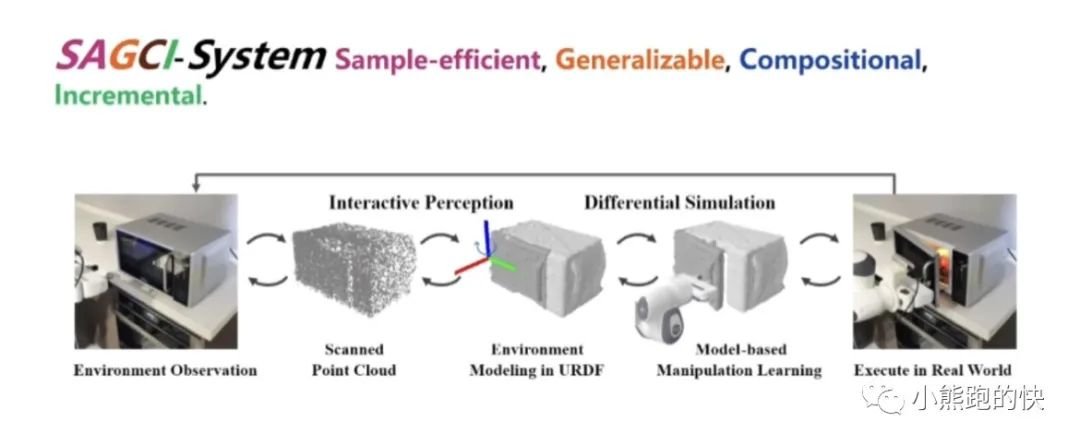
3、具身想象
感知的东西都有了之后,你肯定会在脑子里想我该怎么去做,这是一个具身想象的过程。我们做了一个名为 RFUniverse 的仿真引擎,这个仿真引擎支持 7 种物体(比如关节可移动的、柔性的、透明的、流体的……)、87 种原子操作的仿真。这些操作相当于我们把物体录入之后,我们在仿真引擎里想象它大概应该怎么做。跟以往不同的一点是,我们已经有了这些物体的知识。它也支持强化学习、VR。这个项目也已经开源。

4、具身执行
接下来是一个更难的事情:我们想象完了之后怎么去做?大家觉得想完之后去做是不是挺简单的?其实不是,因为你的想象和真实操作是有差距的。而且我们又希望这个操作能自适应于各种事件的变化,这个难度就很大。
我们希望建一个元操作库,这样我们就能调用各种元操作来解决这个问题。在《Mother of all Manipulations:Grasping》这项工作中,我们从 Grasping 做起。给定一个点云,这个点云对应的动作会去抓取,你怎么去产生那些 grasp pose?

(四)大厂进展
1、2023年3月谷歌和柏林工业大学的团队重磅推出了史上最大的视觉-语言模型——PaLM-E,参数量高达5620亿(GPT-3的参数量为1750亿)。具体来说, PaLM-E-562B 集成了参数量 540B 的 PaLM 和参数量 22B 的视觉 Transformer(ViT),作为一种多模态具身视觉语言模型(VLM),PaLM-E不仅可以理解图像,还能理解、生成语言,可以执行各种复杂的机器人指令而无需重新训练。谷歌研究人员计划探索PaLM-E在现实世界场景中的更多应用,例如家庭自动化或工业机器人。他们希望PaLM-E能够激发更多关于多模态推理和具身AI的研究。
2、2023年4月 微软团队在探索如何将 OpenAI研发的ChatGPT扩展到机器人领域[8],从而让我们用语言直观控制如机械臂、无人机、家庭辅助机器人等多个平台。研究人员展示了多个 ChatGPT 解决机器人难题的示例,以及在操作、空中和导航领域的复杂机器人部署。
3、2023年5月英伟达创始人兼首席执行官黄仁勋在ITF World 2023半导体大会上,认为“芯片制造是英伟达加速和AI计算的理想应用”;“人工智能下一个浪潮将是"具身智能",他也公布了Nvidia VIMA,这是一个多模态具身人工智能系统,能够在视觉文本提示的指导下执行复杂的任务。
Huang 描述了一种新型人工智能——“具身人工智能”,即能够理解、推理并与物理世界互动的智能系统。
他说,例子包括机器人技术、自动驾驶汽车,甚至是聊天机器人,它们更聪明,因为它们了解物理世界。Huang 介绍了 NVIDIA VIMA,一种多模态人工智能。VIMA 可以根据视觉文本提示执行任务,例如“重新排列对象以匹配此场景”。它可以学习概念并采取相应的行动,例如“这是一个小部件”、“那是一个东西”然后“把这个小部件放在那个东西里”。VIMA 在 NVIDIA AI 上运行,其数字双胞胎在3D 开发和模拟平台NVIDIA Omniverse中运行。Huang 说,了解物理学的人工智能可以学习模仿物理学并做出符合物理定律的预测。
部分数据来源上海交通大学教授卢策吾在机器之心 AI 科技年会上,发表了主题演讲 ——《具身智能》 。