

编辑:2049、Panda
Roblox,这个备受青少年喜爱的在线游戏平台,正通过引入 AI 技术,进一步革新游戏的创作体验。据了解,曾获选「儿童票选奖最受欢迎游戏」的 Roblox 允许用户设计自己的游戏、物品及衣服,以及游玩自己和其他开发者创建的各种不同类型的游戏。而现在,用户可以借助 AI 来完成这些创作了。
近日,Roblox 发布了一个用于 3D 智能的基础模型 Cude。据介绍,Roblox 的目标是构建一个可以生成 Roblox 游戏各方面体验的 3D 智能基础模型,从生成 3D 物体和场景到人物角色,再到描述事物行为的编程脚本。

Roblox 创始人兼 CEO David Baszucki 的推文

Roblox 还在 Hugging Face 上线了一个 Web 应用,也已经有不少网友分享了他们各自的生成结果。这里我们也来尝试一番。
首先,让 Cude 生成一个三头六臂的男孩(a boy with 3 heads and 6 arms):

这和我们常见的哪吒形态可真是相去甚远。下面再来个更加日常一些的事物:一台老式打字机(An old-fashioned typewriter)。

这一次 Cube 的表现就好多了。多次尝试后,我们发现,Cube 的整体效果目前还只能说是一般 —— 在生成日常可见的事物表现会好一点,略微超出常识的东西都会让它给出与指令不符的结果,比如让它生成一只手叉腰站立的猫(A cat standing with hands on hips)。

下面我们就来具体看看 Roblox 的这项研究。

论文标题:Cube: A Roblox View of 3D Intelligence
论文地址:https://arxiv.org/pdf/2503.15475
项目地址:https://github.com/Roblox/cube
试用链接:https://huggingface.co/spaces/Roblox/cube3d-interactive
作为一家游戏公司,Roblox 开发这个 3D 智能基础模型的动机非常明显。
他们表示:「我们将此模型设想为各种协作助手的基础 —— 可以帮助开发者创造 Roblox 体验的各个方面,从创建单个 3D 对象(例如,制作带翅膀的摩托车)到完整的 3D 场景布局(例如,创建一个未来风格云朵城市),再到穿戴装备的人物角色(例如,生成一个能够进行墙壁跳跃的外星忍者)到描述对象行为、交互和游戏逻辑的脚本(例如,当玩家靠近门并携带金钥匙时,让门打开)。」
基于这些设想,他们首先确立了三个核心设计要求:
能从稀疏的多模态数据中联合学习;
可通过自回归模型处理无界的输入 / 输出大小;
能通过多模态输入 / 输出与人类和其他 AI 系统协作。
当然,理想虽然很丰满,甚至涉及到「元宇宙」等概念,但现实的路还是得一步步地走。这一次发布的 Cube 模型是 Roblox 向 3D 智能基础模型迈出的第一步。
具体来说,他们关注的核心是 3D 形状的 token 化——毕竟几何形状应该是这个基础模型的核心数据类型。
他们的研究表明,新提出的 token 化方案可以用来构建多种应用,包括文本到形状生成、形状到文本生成和文本到场景生成,如图 1 和 2 所示。

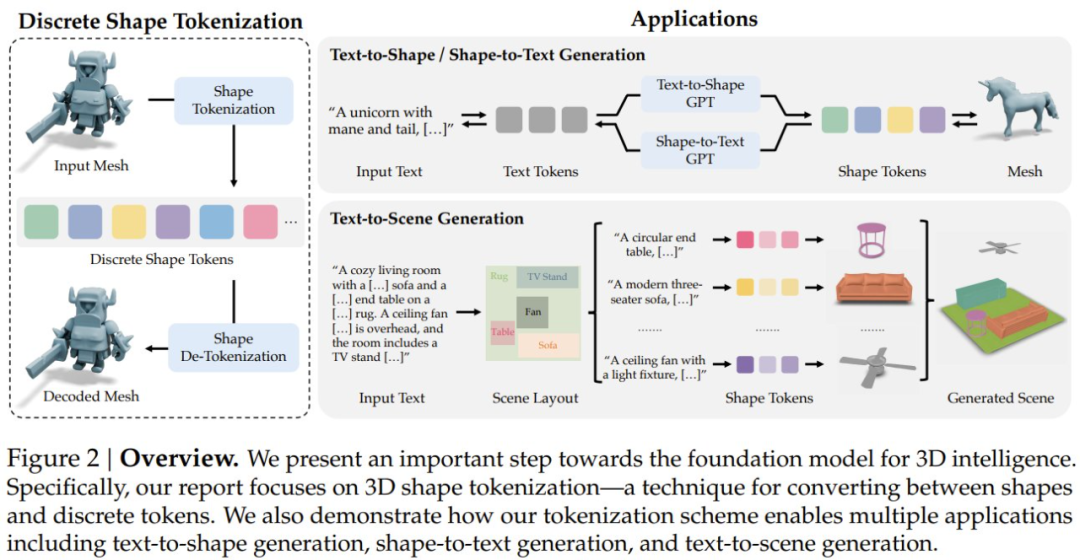
形状 token 化
为了忠实地捕捉各种几何特性,包括光滑的表面、锐利的边缘、高频细节,需要一种具有足够表现力的 3D 几何表示,其可用作多模态自回归序列模型的输入和输出 token。
立足于这样的需求,Roblox 从 3DShape2VecSet 等连续形状表示开始,并将其调整为离散 token,以实现对跨模态的输入和输出的原生处理 —— 类似于 Chameleon 等混合模态基础模型。
如图 3 所示,Cube 的高层架构采用了编码器 - 解码器设计,其会将输入的 3D mesh 编码成一种隐含表征,而这种隐含表征之后又可被解码成一种隐式占用场(implicit occupancy field)。
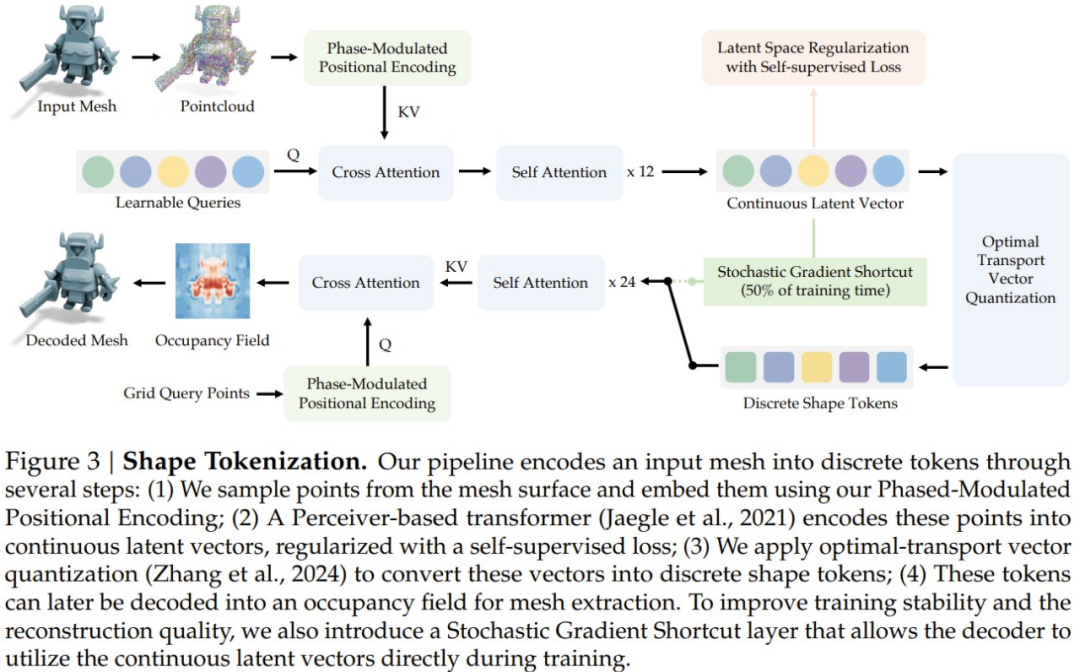
其中一个关键区别在于会通过一个额外的向量量化过程来离散化这个连续的隐含表征,而由于其不可微分的性质,这又会带来额外的难题。
为此,他们提出了两种技术:随机梯度捷径和自监督隐含空间正则化。
他们还提出了另一项架构改进:使用相位调制位置编码。其作用是能提高基于感知器的 Transformer 在交叉注意力层中为空间不同点消歧的能力。
该团队表示:「这些架构变化使我们训练出的形状 token 化器可以忠实地捕捉各种形状,同时产生适合用于训练基于 token 的混合模态基础模型的离散 token。」
相位调制位置编码
为了将形状编码成一个紧凑的隐含表示,研究者首先从其表面采样 𝑁_𝑝 个点以创建一个点云 P。先前的工作在使用 transformer 网络处理 P 之前,通过正弦位置编码函数 𝛾(・) 对其进行嵌入:
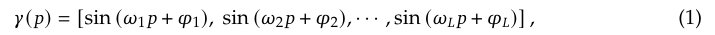
其中 𝛾(𝑝) 分别应用于 P 中三个坐标通道 𝑝 ∈ [𝑥, 𝑦, 𝑧] 的每一个,且 𝜔_𝑖 = 2⌊𝑖/2⌋𝜋, 𝜑_𝑖 = 𝜋/2 (𝑖 mod 2),对于 𝑖 = 1,・・・,𝐿,其中 𝐿 是基频的数量。
𝛾(・) 函数的周期性特性导致在空间中相隔 2𝜋/𝜔_𝑖整数倍的点会在第𝑖个通道中被映射为相同的编码。这一现象使得空间上相距较远的点可能会映射到相似的嵌入向量(图 4a),而这些向量在经过交叉注意力层的点积运算后难以被有效区分。由于嵌入无法区分空间上相距较远的点,相应地,也无法区分不同形状表面的特征,最终导致形状重建质量下降。
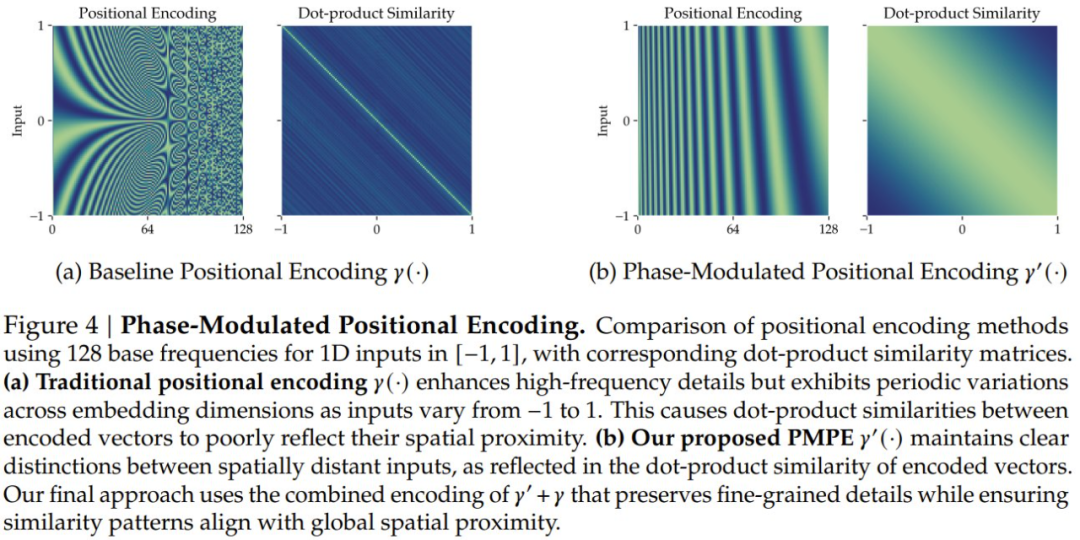
为了解决这个问题,需要一种新型技术来编码点,使其不仅能像传统位置编码那样捕获多尺度特征,还能在点积注意力机制中保持空间上相距较远的点的区分性。研究者从相位调制技术中汲取灵感,提出了相位调制位置编码 (PMPE)。PMPE 在所有正弦函数上调制相位偏移,并使用嵌入函数𝛾_PM,定义为:
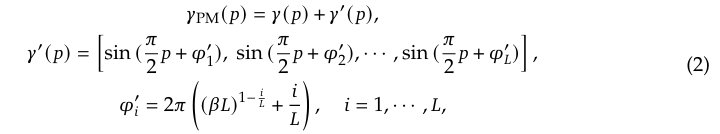
其中𝛾(𝑝) 是传统的编码函数,𝛽是控制通道间相位变化率的超参数。这里的 (𝛽𝐿)(1-𝑖/𝐿) 项用于改变基频,以避免𝛾(𝑝) 和𝛾′(𝑝) 之间的共振。
与使用指数增长频率来捕获多尺度特征的𝛾(𝑝) 不同,𝛾′(𝑝) 对每个通道使用相同的频率𝜋/2,但通过𝑖的非线性函数来改变相位偏移𝜑′𝑖。这种非线性相位调制确保了空间上相距较远的点在映射到嵌入空间时保持区分性,如图 4b 所示。
实验表明,PMPE 显著提高了重建保真度,特别是对于复杂的几何细节。PMPE 还减少了例如色斑 (disco) 等伪影的产生。
用于梯度稳定化的随机线性捷径
在将输入形状编码为连续隐向量后,研究者采用最优传输 VQ(optimal transport VQ)将隐向量转换为离散 token 序列。由于 VQ-VAE 中的量化层涉及不可微分的码本嵌入(codebook embedding)分配,可能导致训练不稳定。
研究者引入了额外的线性捷径层,可随机跳过整个量化瓶颈。他们以 50% 概率通过线性层投影编码器的隐向量,直接输入解码器。这与直接捷径(direct shortcut)方法不同,后者使用恒等层而非线性层,实验证明表现不佳。
额外的线性层使捷径路径能作为量化路径的教师网络,防止陷入局部最小值。实验证明这种方法可降低训练和验证损失,并能提高训练稳定性。
通过自监督损失学习几何聚类的隐含表示
借鉴视觉模型研究,该研究采用自监督损失来正则化隐含空间,使相似形状产生接近的隐向量,图 5 展示了该编码器的自监督学习流程。研究者维护了编码器的指数移动平均版本作为教师模型,学生编码器接收掩码输入,教师编码器访问完整查询集。
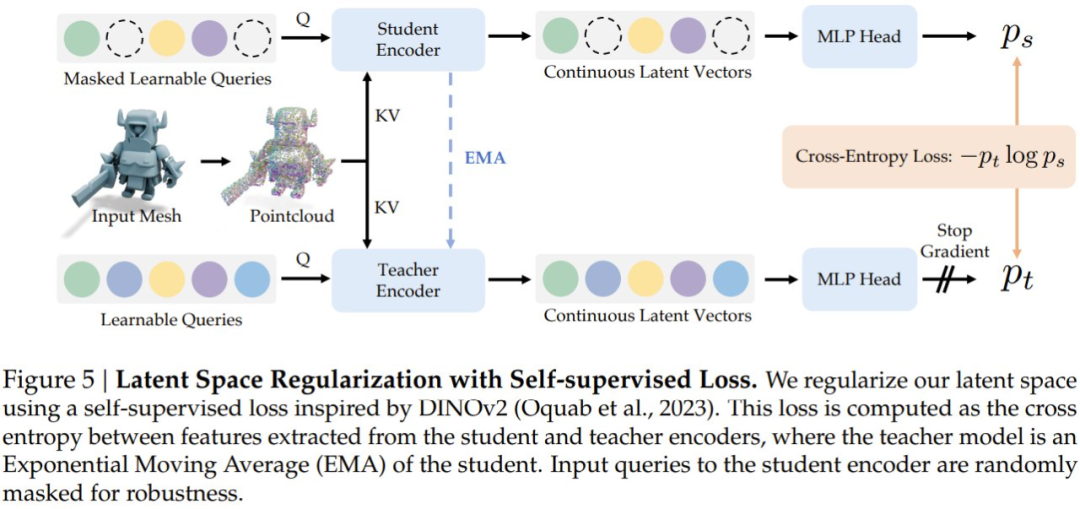
两个编码器使用额外 MLP 头生成「原型分数(prototype scores)」,自监督损失是这些分数间的交叉熵,通过 λ_SSL 平衡与重建损失的关系。这使几何相似形状能编码为高余弦相似度的隐向量。
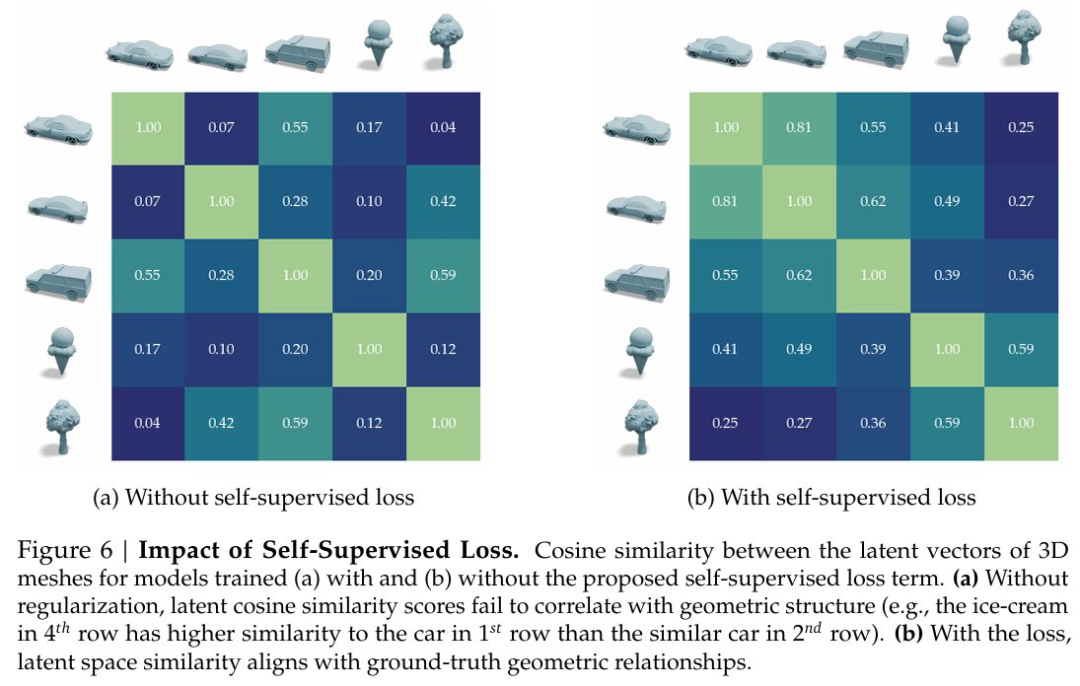
如图 6 所示,将几何相似形状编码为具有高余弦相似度的隐向量的能力自然地从额外的自监督损失中产生。研究者预计这一特性将对广泛的形状处理应用证明其价值。
实验
架构详情
该模型使用结构相似的编码器 (13 层) 和解码器 (24 层) Transformer,每层宽度 768,共 12 个注意力头,总参数量 2.73 亿。使用 512 个隐含编码 token,16,384 大小的码本,嵌入维度 32。PMPE 参数 β = 0.125,自监督损失 λ_SSL = 0.0005。VQ 层采用 OptVQ 变体,集成最优传输方法。
训练数据
研究在约 150 万个 3D 物体资产上训练模型,包括 Objaverse 等公开数据集和 Roblox Creator Store 资产。所有资产归一化至 [-1,1] 范围内,训练时在表面采样 8,192 点用于输入编码,额外采样 8,192 点计算占用损失(occupancy loss)。
模型比较
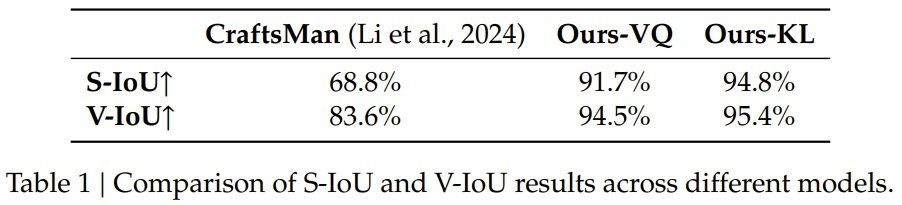
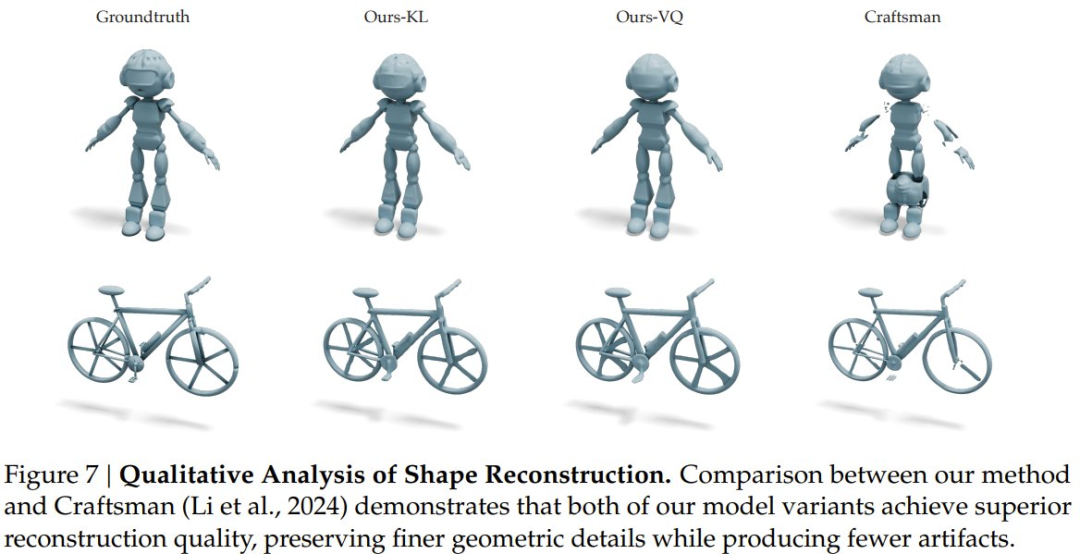
研究比较了离散形状 tokenizer 与一种连续变体,并与 CraftsMan(在 17 万物体上训练)进行对比。在 Toys4K 数据集上评估表面交并比(S-IoU)和体积交并比(V-IoU)表明,该研究的 VQ-VAE 模型和连续变体均优于 CraftsMan,但连续变体仍优于离散模型,表明向量量化过程存在几何保真度损失。
如表 1 和图 7 所示,该研究提出的 VQ-VAE 模型(Ours-VQ)和连续变体(Ours-KL)在 S-IoU 和 V-IoU 指标上均优于 CraftsMan。连续变体仍然优于其对应的离散模型,这表明通过向量量化过程仍然存在一些几何保真度的损失。研究团队计划在未来的工作中弥合这一差距。
最后,Roblox 在论文中展示了一些具体的应用,包括文本到形状生成、形状到文本生成和文本到场景生成:



