

通义全新推理模型 QVQ 宣布开源
12 月 25 日,通义千问宣布,基于 Qwen2-VL-72B 构建的开源多模态推理模型 QVQ 开源。
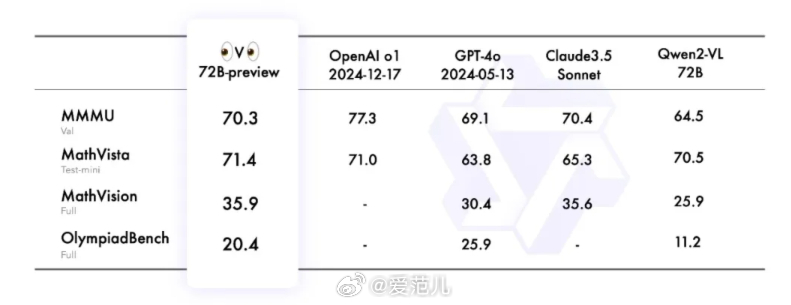
据官方介绍,QVQ 在人工智能的视觉理解和复杂问题解决能力方面实现了重大突破。在 MMMU 评测中,QVQ 取得了 70.3 的优异成绩,并且在各项数学相关基准测试中相比 Qwen2-VL-72B-Instruct 都有显著提升。通过细致的逐步推理,QVQ 在视觉推理任务中展现出增强的能力,尤其在需要复杂分析思维的领域表现出色。
官方表示,尽管 QVQ 的表现超出了预期,但仍会出现一些局限:
- 语言混合与切换:模型可能会意外地混合语言或在语言之间切换,从而影响响应的清晰度;
- 递归推理:模型可能会陷入循环逻辑模式,产生冗长的响应而无法得出结论;
- 安全和伦理考虑:模型需要增强安全措施,以确保可靠和安全的性能,用户在部署时应保持谨慎;
- 性能和基准限制:尽管模型在视觉推理方面有所改善,但它无法完全替代 Qwen2-VL-72B 的能力。此外,在多步骤视觉推理过程中,模型可能会逐渐失去对图像内容的关注,导致幻觉。
官方还表示,通义千问的愿景是开发一个「全能」和「智能」的模型,同时通义正在增强其的视觉语言基础模型,赋予其基于视觉信息的深度思考和推理的高级能力。在不久的将来,通义计划将更多的模态整合到一个统一的模型中,使其更加智能,能够应对复杂的挑战并参与科学探索。
目前,QVQ 模型已在魔搭社区和 HuggingFace 等平台上开源。