

原标题:资源 | DLL:一个炙手可热的快速深度神经网络库
选自arXiv
作者:Baptiste Wicht 等
机器之心编译
参与:乾树、李泽南
DLL 是一个旨在提供由 C++实现的受限玻尔兹曼机(RBM)和深度信念网络(DBN)及其卷积版本的软件库,由瑞士 University of Applied Science of Western Switzerland、弗里堡大学的研究者共同提出。与常用的深度学习框架类似,它还支持更多标准的神经网络。目前,该工具已开发至 1.1 版本。
项目链接:https://github.com/wichtounet/dll
引言
近年来,神经网络以深度学习之名重获青睐。所谓的深度即是运用更大更深的网络,通常 z 指的是使用更大的输入维度来融合更多的上下文知识,以及增加网络层数来提取不同粒度级别的信息。
深度学习的成功主要归因于三个因素。第一,大数据的出现,意味着有大量的训练数据可用。第二,新的训练策略,例如无监督的预训练,它保证了深度网络会很好的初始化,并且还可以学习大量未标记数据集的高效特征提取器。
第三,更强劲的硬件有助于加速深度网络的训练过程。深度网络目前正在提高多领域的最新技术。成功的深度学习应用应该在物体识别 [1],图像标注 [2],上色 [3] 或生成高仿真的图像 [4] 等领域取得近乎人类的表现。
此外,免费且易用的框架的可用性以及基于公共数据集的详细实现样例的可用性也促成了深度学习技术的广泛运用。
从实际角度出发,理想的深度学习框架应当易于使用,能够提供高精度的快速训练,并有多种配置选项。满足所有要求十分困难,因为有些要求自相矛盾。鉴于此,我们可能会感受到现有框架之间的巨大差异。
在本文中,我们提出并开发了一个专注于高效计算,针对特定的网络模型和算法配置的深度学习框架。尽管我们意识到这些问题的局限性,但我们相信,我们在框架中实现的不同优化可能会引起研究社区的兴趣。
我们的框架叫做深度学习库(DLL),它是免费且开源的。开发这一框架的最初原因是其他机器学习框架中缺乏对受限玻尔兹曼机(RBM)[5] 和卷积 RBM(CRBM)[6] 的支持。在本论文截稿前,这一问题仍然存在。随着我们的不断开发,该框架扩展了通用的神经网络操作,现在可以用来训练标准人工神经网络(ANNs)和卷积神经网络(CNNs)[7] 等不同种类。
虽然也有 GPU 加速,但是 DLL 已针对中央处理器(CPU)的进行了速度优化。尽管 GPU 开始成为训练训练深层网络的即成标准,但它们并不总是可用,并且一些发布程序仍然针对现有的 CPU 实现。而且,一旦网络训练完成,通常会在 CPU 上执行推理。
因此,我们认为能够在合理的时间内训练神经网络并实现在 CPU 上的快速推理仍然很重要。在本文中,我们也记录了对 GPU 的成功优化,但我们必须注意到 GPU 的高级并行化已经充分利用 [8],[9],尤其是卷积网络 [10]。
除了加速外,本文的特别贡献是对几个最新的热门框架的综合评估。评估是在四个不同的模型和三个数据集上进行的。最终根据 CPU 和 GPU 上的计算时间以及训练模型的最终准确度进行比较。
本文的其余部分如下。第二节详细介绍 DLL 库。第三节介绍实验部分。第四节介绍 MNIST 的实验结果,第五节介绍 CIFAR-10 的实验结果,第六节介绍 ImageNet 的实验结果。最后,第七节给出总结。
DLL:深度学习工具库
深度学习库(DLL)是最初专注于支持 RBM 和 CRBM 的机器学习框架。它是在几项研究工作 [11] - [14] 的背景下开发并使用的。它还支持各种神经网络层和标准反向传播算法。它是用 C ++ 编写的,主接口是 C ++(在论文 II-B 节中有示例)。该框架也可以通过用简单的描述语言来使用,以使研究人员更容易上手。
该框架完全支持 RBM 模型 [5]。还可以使用对比散度(CD)[15] 进行训练。该实现是根据 [16] 中的模型设计的。它还支持深度信念网络(DBN),先逐层预训练,然后使用梯度下降法进行微调。
RBM 支持大范围的可见和隐藏单元类型,如二值函数,高斯函数和整流线性单元(ReLU)[17]。同时也按照 [6] 的模型整合对 CRBM 的支持,同时第二版整合最大池化层为池化层。
该框架还支持常规神经网络。即可以训练人工神经网络和 CNN。CNN 也支持最大池化层和平均池化层。这些网络可以使用小批量梯度下降法进行训练。同时支持动量和权重衰减等基本学习选项。
该框架还支持一些高级特性,如 Dropout [18] 和 批归一化 [19]。最后,该框架也整合了 Adagrad [20],Adadelta [21] 和 Adam [22] 等自适应优化器。并支持自动编码器 [23] 和卷积自动编码器 [24]。他们可以接受有噪声的输入数据来训练以增强泛化性能,这种技术被称为去噪自动编码器 [25]。
DLL 库遵从 MIT 开源许可条款,免费使用。该项目的详细信息以及部分教程可参考主页。
实验评估
我们通过一些实验将 DLL 与目前流行的深度学习框架进行了比较。每种模型在每个框架上的训练时间都会进行比较,无论是在 CPU 上还是在 GPU 上。所有实验都计算了在每个框架上测试的准确度。结果表明,所有测试框架在使用相同参数进行训练时都准确率都不相上下。
我们在这里指出,这些实验的目标不是针对测试数据集取得最优性能。事实上,这些模型之所以简单,是为了与大量的框架进行比较。此外,如果我们的目的是取得高准确率,网络不应该总是像实验那样训练多个 epochs。
最后,重要的是:我们不知道所有框架的全部细节。我们尽最大努力保持网络架构和训练参数的同一性,但可能框架本身的一些实现细节导致训练方法,解释执行时间的差异略有不同。
本研究介绍的所有实验都运行在频率为 3.4 GHz Intel R CoreTM i7-2600,12 GB RAM 的 Gentoo Linux 机器上(针对这些测试而禁用 CPU 调频)。机器开启了 SSE 和 AVX 矢量化扩展。BLAS 通过 Intel R Math Kernel Library(MKL)以并行模式执行。基准 GPU 是 NVIDIA Geforce R GTX 960 显卡,配以 CUDA 8.0.4.4 和 CUDNN 5.0.5。为了确保实验可重现,用于这些实验的源代码已开源。
项目地址: https://github.com/wichtounet/frameworks
以下是研究人员选取的对比框架:
1)Caffe [30]:Caffe 是一个高级机器学习框架,专注于速度和表达。它是用 C++ 开发的,可通过文本描述性语言使用。Caffe 1.0 可通过源码安装并支持 GPU 和 MKL。
2)TensorFlow [31]:一个允许构建数据流图来执行数值计算的通用的低级框架。该框架的核心用 C ++ 编写,但这些功能大多可通过 Python 接口调用。Tensorflow 1.3.1 可通过源码安装并支持 CUDA,CUDNN 和 MKL。
3)Keras [32]:一个高级机器学习库,为 Tensorflow 或 Theano 提供前端接口。用 Python 编写。提供了大量的高级模型,简化了机器学习模型的开发。可使用 Tensorflow 1.3.1 的官方软件包来安装 Keras 2.0.8。
4)Torch [33]:Torch 是最早于 2002 年出现的一个低级机器学习框架。通过 Lua 前端接口调用。虽然它是一个低级框架,但包含了用于机器学习的高级模块。它可以通过 Git commit 3e9e141 进行源码安装并支持 CUDA 和 MKL。
5)DeepLearning4J [34]:DeepLearning4J 是用 Java,C 和 C ++ 编写的 Java 深度学习框架。它具有非常多的功能,且专注于分布式计算。可从 Maven 获取 0.9.1 版本。
这些框架是根据它们的流行程度来选择的,也是也为了编程语言的多样性。DLL 可直接从源代码调用,截稿时可用的最新版本是(Git commit 2f3c62c)。

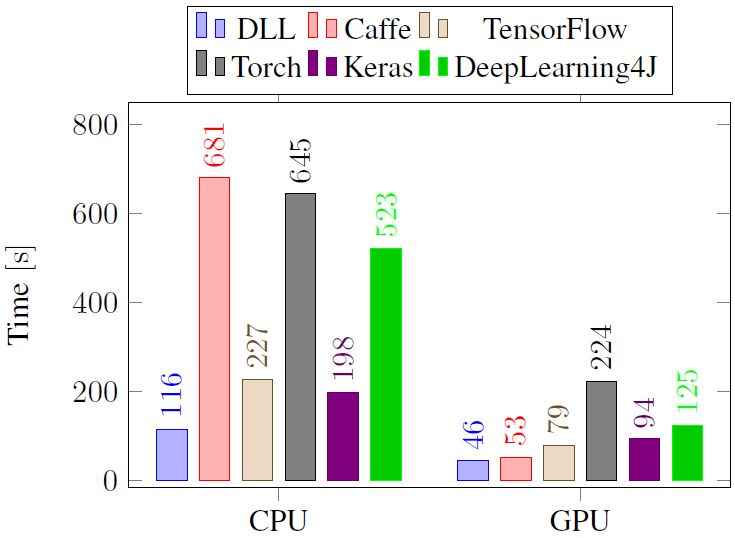
图 2:各框架基于 MNIST 数据集的全连接神经网络实验在 CPU 和 GPU 上的训练时间性能的比较。

图 3:各框架在 CNN,MNIST,CPU 和 GPU 上的训练时间性能比较。
论文:DLL: A Blazing Fast Deep Neural Network Library

链接:https://arxiv.org/pdf/1804.04512.pdf
深度学习库(DLL)是一个全新的机器学习库,它专注于速度。DLL 支持前馈神经网络,如全连接的人工神经网络(ANN)和卷积神经网络(CNN)。它还对受限玻尔兹曼机器(RBM)和卷积 RBM 提供非常全面的支持。
我们这项工作的主要动机是提出与评估有潜力加速训练和推理时间的创新的软件工程策略。这些策略大多独立于深度学习算法。我们在三个数据集和四个不同的神经网络模型上对 DLL 与其它五个流行的深度学习框架进行了比较。实验表明,所提出的框架在 CPU 和 GPU 上均有大幅提升。在分类性能方面,DLL 可获得与其他框架相似的准确度。
本文为机器之心编译,转载请联系本公众号获得授权。