
PaliGemma 2在多个任务上取得了业界领先的成绩,包括图像描述、乐谱识别和医学图像报告生成;并且提供了不同尺寸和分辨率的版本,用户可以根据不同的任务需求进行微调,以获得更好的性能。
OpenAI的发布会仿佛连续剧,让人眼花缭乱,谷歌也悄悄发布了PaliGemma 2模型,迈向可调视觉语言模型的下一代。
今年5月,谷歌发布PaliGemma,也是Gemma家族中的第一个视觉语言模型,致力于模型民主化,降低视觉模型的使用难度。
PaliGemma 2模型以更高性能的Gemma 2为基座,增加了视觉能力,微调起来更容易,性能也更好。
技术报告中分析了任务类型、模型尺寸和分辨率之间的相互作用,相比PaliGemma进一步扩大了迁移任务的数量和范围,包括与OCR相关的任务,如表格结构识别、分子结构识别、乐谱识别,以及更长、更细粒度的图像描述和放射学报告生成,并且在这些任务上都取得了最先进的结果。

报告链接:https://arxiv.org/pdf/2412.03555
PaliGemma 2的主要特点为:
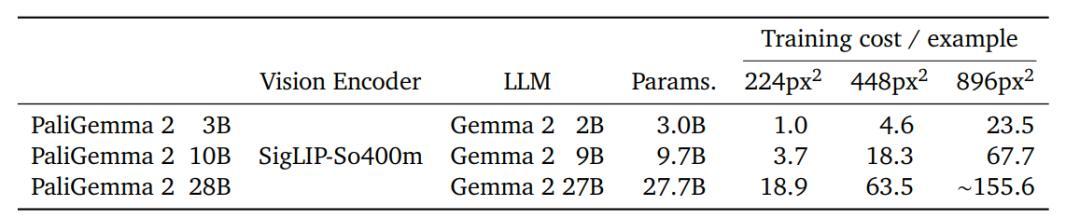
1. 模型尺寸包括3B、10B、28B 参数,可适应任务分辨率为224px、448px、896px的视觉输入。
2. PaliGemma 2可以为图像生成详细的、上下文相关的描述,而不只是简单的对象识别来描述动作、情感和场景的整体叙述。
3. PaliGemma 2在化学式识别、乐谱识别、空间推理和胸部X光报告生成方面的性能更强。
PaliGemma一代的用户可以直接升级到PaliGemma 2,无需进行重大代码修改即可获得性能提升。
模型架构
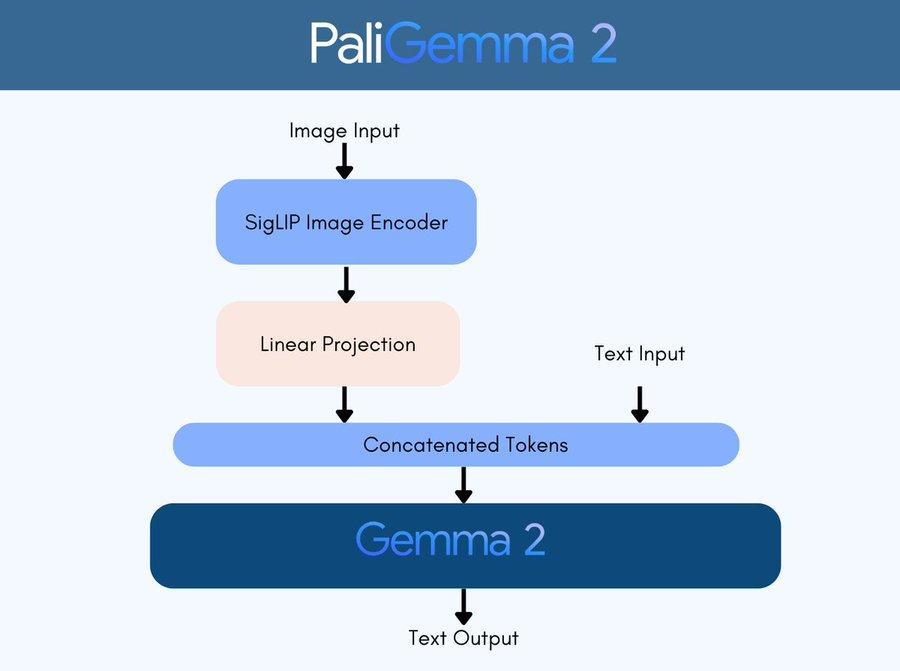
研究人员遵循与PaliGemma相同的建模、训练和数据设置:使用预训练SigLIP-So400m视觉编码器,通过线性投影将「嵌入序列」映射到Gemma 2的输入空间;视觉嵌入与文本提示结合后,输入到Gemma 2语言模型;最后通过自回归采样从语言模型中获得预测。

研究人员将PaliGemma 2的预训练分为三个阶段(不包括对单模态组件进行预训练)。
第一阶段,结合预训练的SigLIPSo400m和Gemma 2的原始模型权重,并在超过10亿个多模态任务样本上进行训练;图像分辨率为224*224像素;在此阶段没有冻结任何参数。
第二阶段,先在448*448像素分辨率下对5000万个样本进行训练,然后在896*896像素分辨率下训练1000万个样本。在任务选择上,增加那些「能从高分辨率图像中受益的任务」比例,增加输出序列的长度,以促进长视觉文本序列的OCR等任务的学习。
第三阶段,将第一或第二阶段的检查点微调到目标任务。PaliGemma包括一系列学术基准,包括一些涉及多张图像和短视频的基准。
此外,研究人员还探索了文档的相关任务、长图像描述生成和医学图像理解的新应用。
实验结果
研究人员测试了PaliGemma 2在文本检测和识别、表格结构识别、分子结构识别、光学乐谱识别(optical music score recognition)、长图像描述生成、空间推理以及放射图像报告生成(radiography report generation)任务上的性能。
模型尺寸和分辨率
研究人员探索了不同尺寸和分辨率的模型在完成各种任务时的表现如何,主要选择了三种尺寸(3B、10B和28B),并在两种不同的图像清晰度(224像素和448像素)下对模型进行训练,任务包括了对自然照片、文件、图表和视频的图像描述、视觉问答和指代分割等。
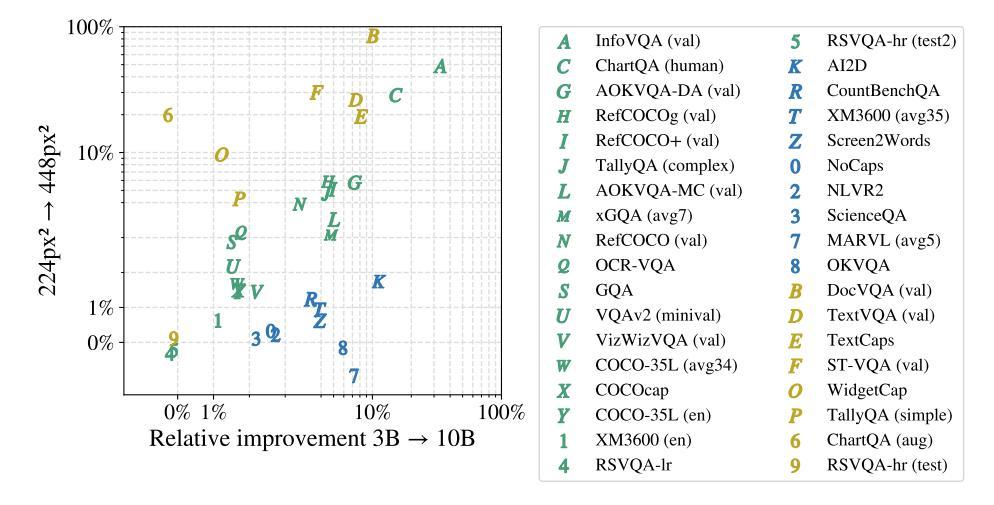
从结果中可以发现,让模型处理更高清晰度的图像或者使用更大尺寸的语言模型,都会增加预测时的计算量,但大多数任务都能从这两项改进中获得性能提升。
涉及文本、文档、屏幕和图表理解的任务,提高图像清晰度带来的收益更大,可能是因为这些任务中使用的图像原生分辨率就比224像素大,所以提高分辨率后效果更明显。
涉及多语言数据或需要复杂视觉推理的任务,主要从增大模型尺寸中获益。
文本检测和识别
在高级光学字符识别(OCR)任务时,模型需要从图像中定位和识别出单词,输出结果为一个数据对「转录文本,边界框」,研究人员遵循HierText竞赛的规则,使用单词级别的精确度、召回率和F1分数作为评估指标。
如果单词结果与真实边界框的交并比(IoU)大于或等于0.5,并且转录文本与真实文本匹配,则认为该单词结果是true positive,但HierText协议不会归一化字母大小写、标点符号,也不会根据文本长度进行过滤,而是直接将预测结果与真实结果进行比较。
研究人员使用常见的OCR基准测试,包括ICDAR’15、Total-Text、MLT17和MLT19、HierText、TextOCR、IntelOCR等多个数据集的训练分割混合上对PaliGemma 2进行了微调,并在ICDAR’15和Total-Text测试集上进行评估。

结果显示,在896像素分辨率下,PaliGemma 2 3B的性能超过了最先进的HTS模型。
需要注意的是,PaliGemma 2并没有依赖于OCR专用的架构组件,只通过微调一个通用的视觉-语言模型(VLM)即实现了sota,展现了PaliGemma 2的多功能性,以及在第2和第3阶段进行OCR相关预训练的优势。
降低分辨率后,预测质量大幅下降,并且增大模型尺寸并没有带来改进。
表格结构识别
表格结构识别任务的目标是从文档图像中提取表格文本内容、相应的边界框坐标以及HTML格式的表格结构。
研究人员选择PubTabNet的516k张表格数据图像,和FinTabNet数据集中来自标普500公司年报的113k个财务报告表格,去除边界框超出图像框架的数据后,把图像填充为正方形以匹配目标输入分辨率。
研究人员使用树编辑距离相似度(TEDS)和网格表格相似度(GriTS)两个指标来评估模型质量,主要测量单元格文本内容、单元格拓扑/结构和边界框质量。
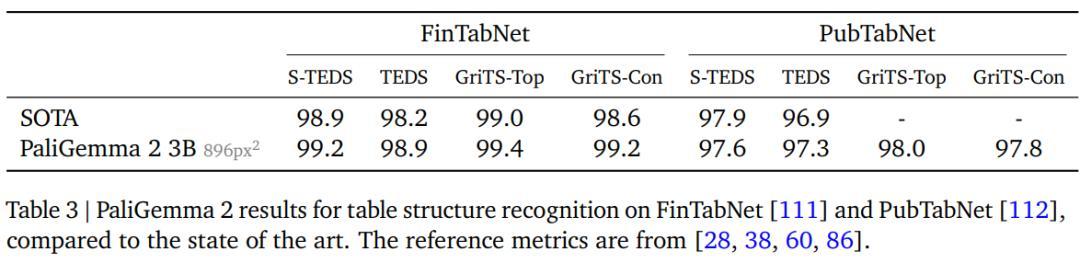
结果显示,PaliGemma 2在大多数指标下都展现出了最高的性能,并且增加模型尺寸也没有对模型的性能带来提升,而使用更低的图像分辨率则会导致质量出现小幅下降。
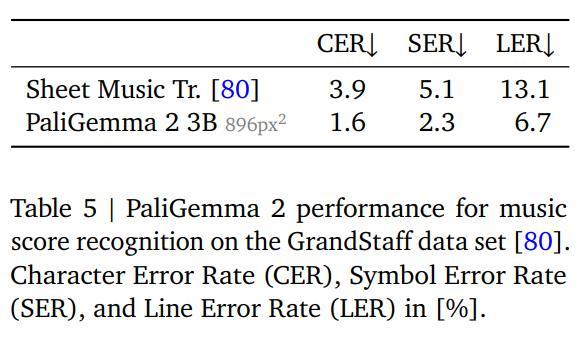
乐谱识别
研究人员使用了GrandStaff数据集进行微调,包含53.7k张图像,基于标准化的平均编辑距离、字符错误率(CER)、符号错误率(SER)、行错误率(LER)进行评估。

结果显示,随着分辨率的提高,错误率也在逐渐降低,但将模型大小从3B增加到10B并没有影响性能。
放射报告生成
为了探索PaliGemma 2在医学领域的能力,研究人员将其用于自动胸部X光报告生成任务上,相当于对X光图像进行长描述。
MIMICCXR数据集包含37.7万张图像,及相应的放射报告;使用Gemini 1.5 pro来移除之前数据中涵盖的X光。
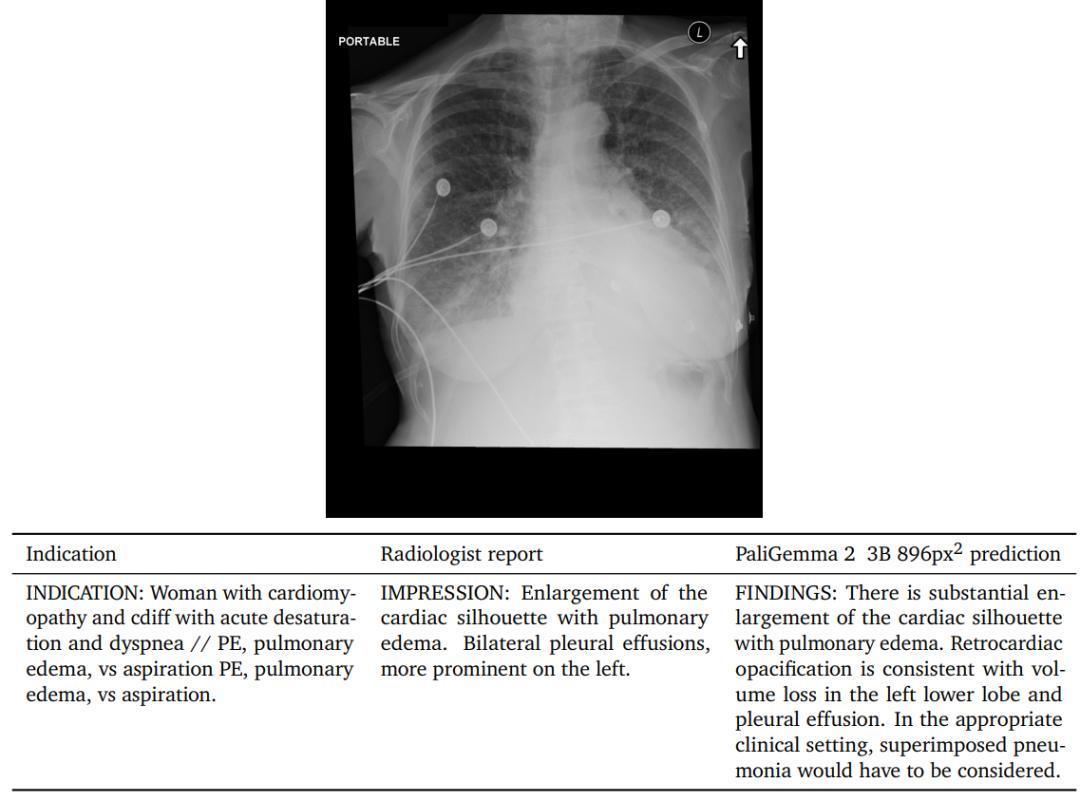
在使用该数据进行微调后,用RadGraph F1分数评估结果,衡量参考报告中提取的实体与生成报告之间的F1分数,可以反应报告中实体的缺失或召回情况,以及与图像特征的关系。
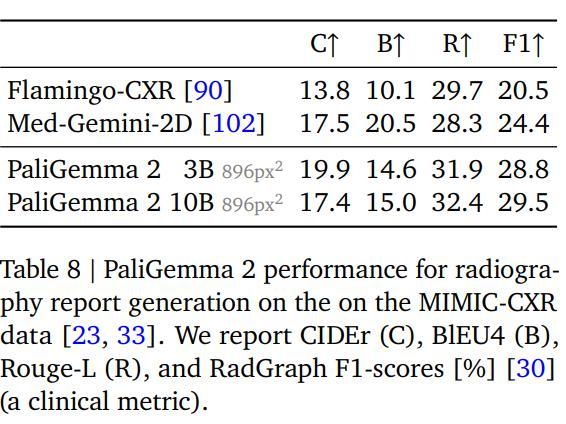
可以看到,PaliGemma 2模型的实现了最好的性能,提高分辨率和模型大小都能带来性能提升。
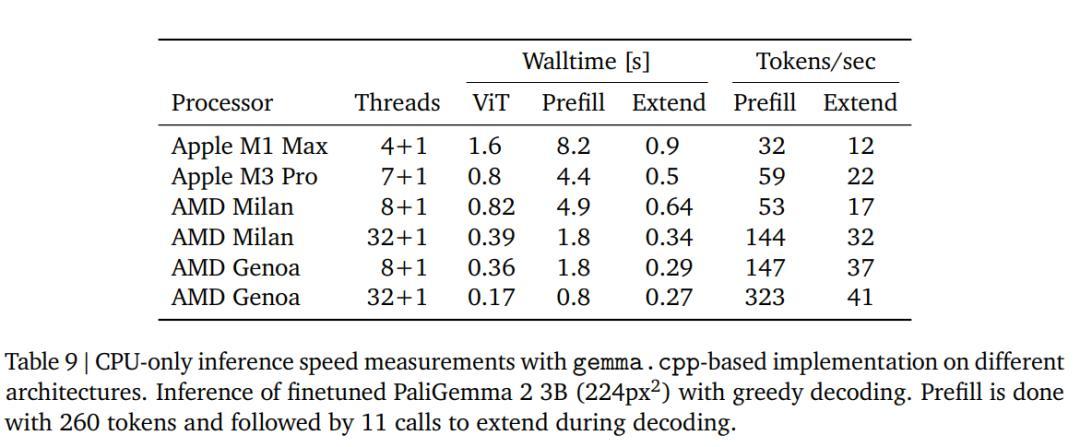
CPU推理和量化
为了评估只用CPU进行推理的速度,研究人员在四种不同的架构上使用gemma.cpp运行PaliGemma 2模型,检查点使用在COCOcap上微调过的PaliGemma 2 3B(224像素)模型。
提示词「描述这幅图像」的预填充长度为256+4=260个token(图像+文本),输出回复「A large building with two towers on the water」为11个token
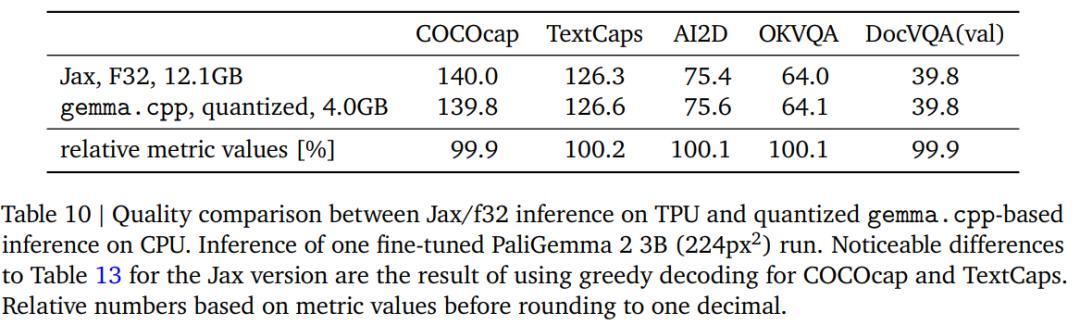
研究人员还对模型进行了量化实验,从32位浮点(f32)转换到16位(bf16)权重,结果显示性能差异并不大。
参考资料:
https://x.com/kimmonismus/status/1864832125851312495