

美图 投稿
图像编辑大礼包!美图5篇技术论文入围CVPR 2025。
比如无痕改字,手写体书面体、海报广告上各种字体都可以修改。
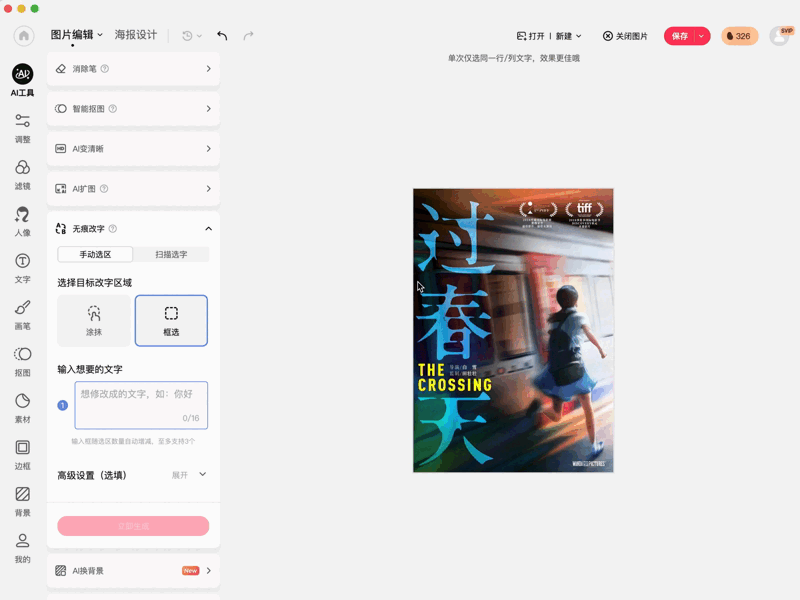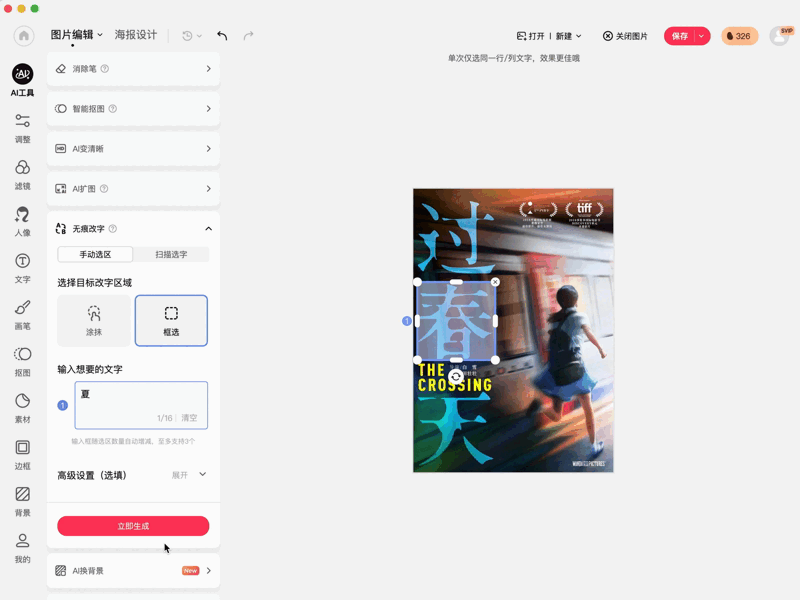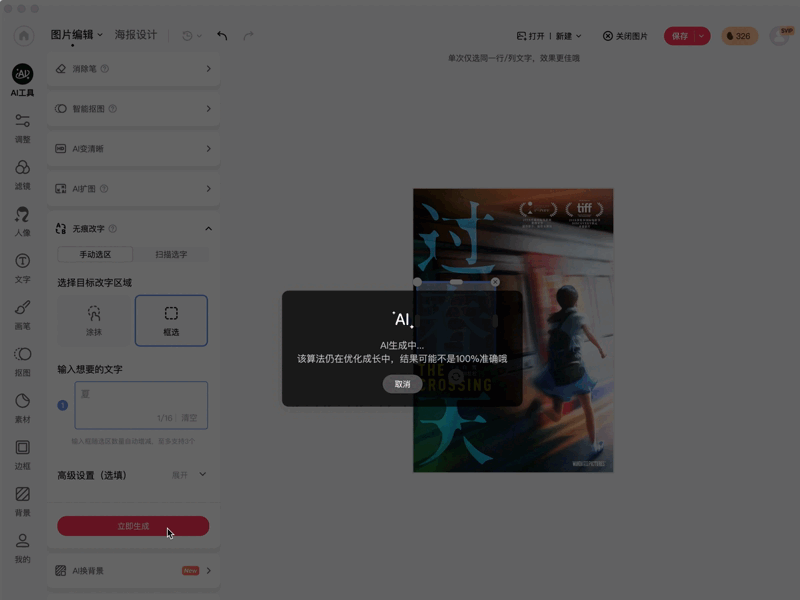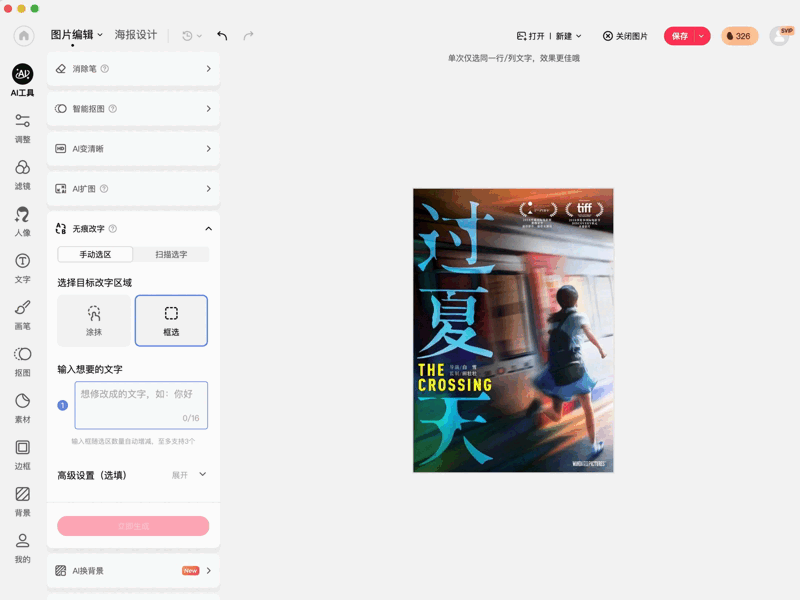
又或者基于语义的局部编辑,只需涂抹或框选工具就能在指定区域生成。
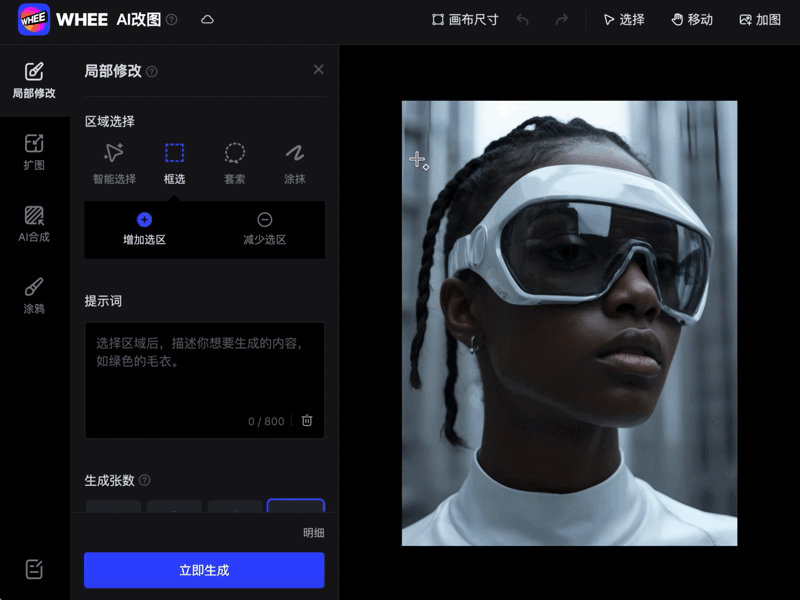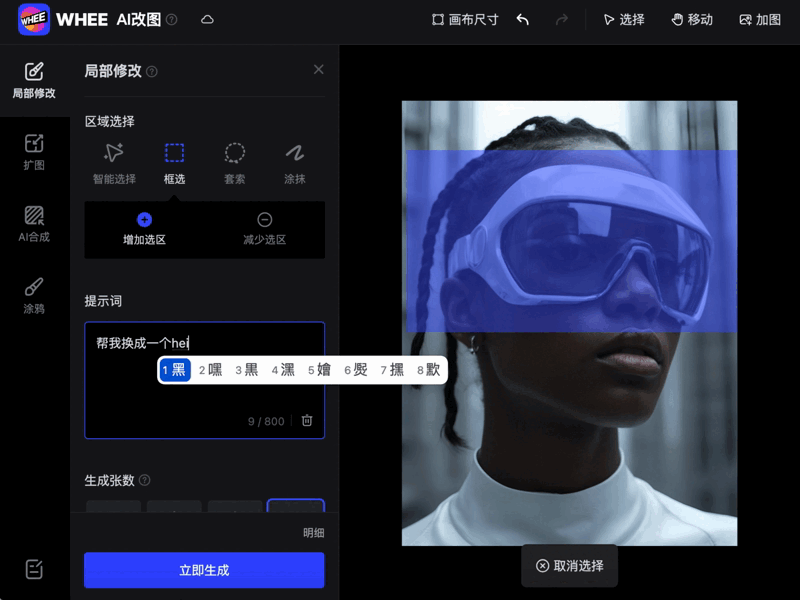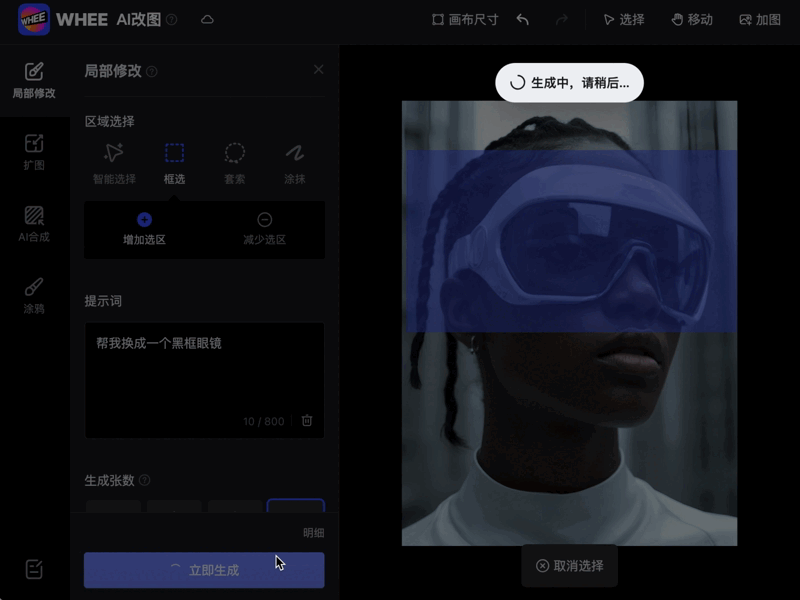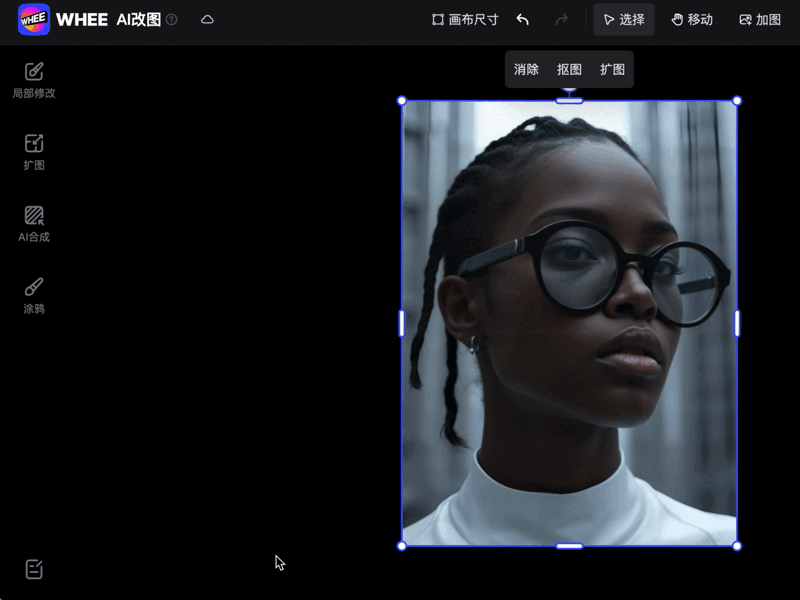
还有超级精细的交互式分割算法等等。
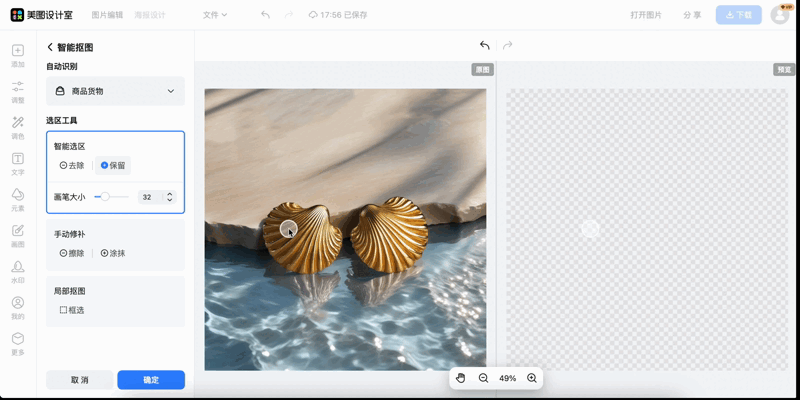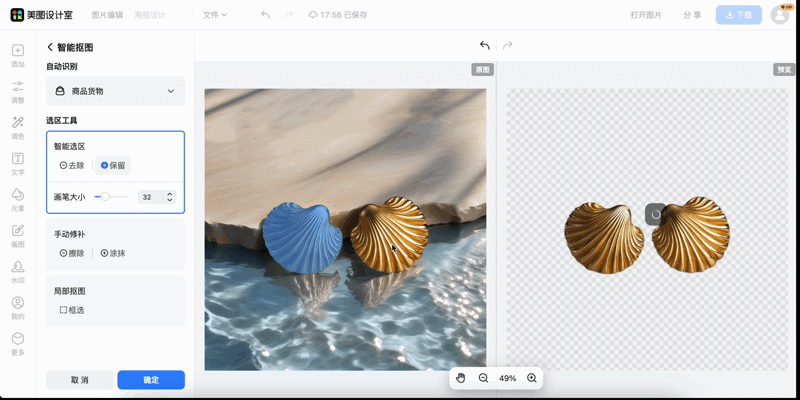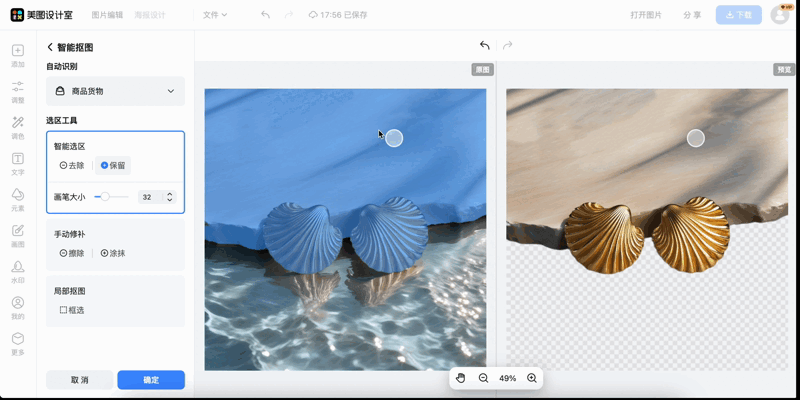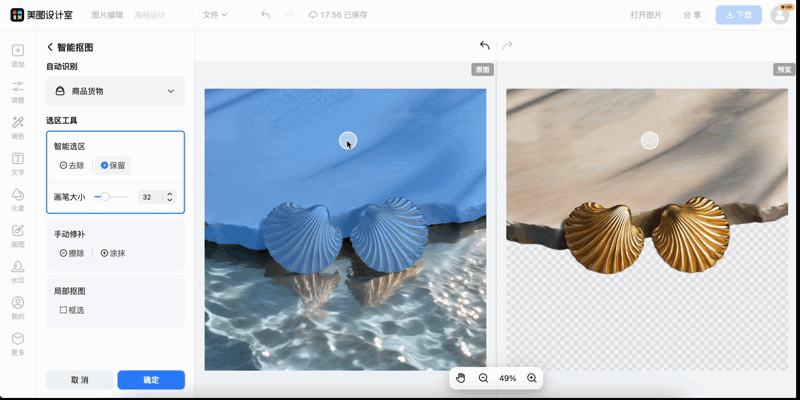
更关键的是,这些前沿技术已经在美图各大APP(美图秀秀、WHEE、美图设计室等)中上线了。
今天就带大家一文看尽美图在AI图像编辑最新成果。
美图5篇论文入选CVPR 2025
美图旗下美图影像研究院(MT Lab)联合清华大学、新加坡国立大学、北京理工大学、北京交通大学等知名高校发布的5篇论文入选CVPR 2025,均聚焦于图像编辑领域,分布在生成式AI、交互式分割、3D重建三个方面。
从技术路径来看,突破主要体现在以下3个方面:
(1)精细化策略设计:通过结合精细化策略(如基于点击的交互式分割方法NTClick、两阶段细化框架SAM-REF)显著提高交互分割的效率与精度,同时大幅降低用户操作复杂度。
(2)垂类场景下基于扩散模型的框架创新:结合特定编码器,提升生成任务质量,以及基于多任务训练框架,提升结构稳定性和风格一致性。
(3)外推视角的高质量合成:基于增强视图先验引导的方案,成功实现高保真的3D重建。
其中GlyphMastero、MTADiffusion属于生成式类任务,这不仅是CVPR最热门的前沿方向之一,美图近年来在该方向上也屡获突破,围绕生成式AI推出的多项功能与多款产品吸引了海内外大量用户,旗下美颜相机近期凭借AI换装功能,成功登顶多国应用商店总榜第一。
NTClick、SAM-REF关注交互分割工作,通过用户简单交互指导的精确引导图像分割,交互分割在复杂场景下能够显著提升分割效果和可靠性,在美图面向电商设计、图像编辑与处理、人像美化等功能的AI产品中有广泛应用,凭借在交互分割方面的领先优势,也带动旗下产品美图设计室的亮眼表现。根据美图最新财报数据显示,这款被称为“电商人必备的AI设计工具”2024年单产品收入约2亿元,按年同比翻倍,是美图有史以来收入增长最快的产品。
EVPGS则是3D重建方面成果,受益于深度学习的驱动,尤其是高斯泼溅(Gaussian Splatting)的兴起,3D重建在新视角生成、增强现实(AR)、3D内容生成、虚拟数字人等领域应用需求激增,在多个行业展现出强大的潜力。
GlyphMastero:高质量场景文本编辑的创新方法
针对场景的文本编辑任务,既要求保证文本内容符合用户编辑需求,还要求保持风格一致性和视觉协调性。研究人员发现,现有方法往往使用预训练的OCR模型提取特征,但它们未能捕捉文本结构的层次性,即从单个笔画到笔画间的交互,再到整体字符结构间的交互,最后到字符与文字行间的交互,这就导致在处理复杂字符(如中文)时容易产生扭曲或难以辨认的结果。
对此,美图影像研究院(MT Lab)的研究人员提出专为场景文本编辑设计的字形编码器GlyphMastero,旨在解决当前扩散模型在文本生成任务中面临的质量挑战。

GlyphMastero核心由字形注意力模块 (Glyph Attention Module)和特征金字塔网络 (FPN)两大部分组成。

△
GlyphMastero方法整体架构
字形注意力模块(Glyph Attention Module)
通过创新的字形注意力模块,建模并捕捉局部单个字符的笔画关系以及字符间的全局排布。该模块不仅对局部细节进行编码,还实现了字符与全局文本行之间的跨层次交互。

特征金字塔网络(FPN)
GlyphMastero还实现了一个特征金字塔网络(FPN),能够在全局层面融合多尺度OCR骨干(Backbone)特征,确保在保留字符细节特征的同时,又能够捕捉全局风格,并将最终生成的字形用于指导扩散模型对文本的生成和修复。
基于跨层次和多尺度融合,GlyphMastero可以获得更细粒度的字形特征,从而实现对场景文本生成过程的精确控制。
实验结果表明,与最先进的多语言场景文本编辑基准相比,GlyphMastero在句子准确率上提高了18.02%,同时将文本区域风格相似度距离(FID)降低了53.28%,这表明生成文本实现了更加自然且高融合度的视觉风格。

对比结果显示,在海报、街景和广告图等场景下,GlyphMastero 能够生成与原图风格高度契合的文本,无论是字体粗细、色调还是透视关系,都比之前的SOTA方法更为自然和精细。

目前GlyphMastero已落地美图旗下产品美图秀秀的无痕改字功能,为用户提供轻松便捷的改字体验。

△
美图秀秀无痕改字效果
MTADiffusion:语义增强的局部编辑方法
图像局部修复(Image Inpainting)提供了一个无需PS或其它图像处理工具,就可以轻松进行改图的全新方式,大大降低使用难度,用户只需要使用涂抹或者框选工具,选定想要修改的局部Mask区域,输入Prompt就能够在指定区域生成想要的图像。
但现有的Inpainting模型,常常在语义对齐、结构一致性和风格匹配方面表现不佳,比如生成内容不符合用户输入的文本描述,或是修复区域的细节缺乏准确性,光照、颜色或纹理与原图也容易存在差异,影响整体视觉一致性。
针对以上问题,美图影像研究院(MT Lab)的研究人员提出了一种图文对齐的Inpainting训练框架——MTADiffusion,MTADiffusion先使用分割模型提取出物体的mask,再通过多模态大模型对图像局部区域生成详细的文本标注,这种图文对齐的训练数据构造方式有效提升了模型的语义理解能力。

为了优化生成物体的结构合理性,MTADiffusion使用了多任务训练策略,将图像去噪任务(Inpainting)作为主任务,进行噪声预测,将联合边缘预测任务(Edge Prediction)作为辅助任务,用于优化物体结构。此外,MTADiffusion还提出了基于Gram矩阵的风格损失,以提升生成图片的风格一致性。

△
MTADiffusion整体框架
基于MTADiffusion方法,图像局部修复模型在BrushBench和EditBench上的效果都有明显提升,同时这些通用的策略也可以适配不同的基础模型。

△
在BrushBench上的对比效果

△
在EditBench上的对比效果
目前,MTADiffusion已落地美图旗下AI素材生成器WHEE,实现轻松高效的一站式改图。
此外,开发者目前也可通过美图AI开放平台集成局部重绘能力,赋能更多创意场景。

△
WHEE的AI改图效果
NTClick:基于噪声容忍点击的精细交互式分割方法
交互式图像分割(Interactive Segmentation)旨在通过尽可能高效的用户输入,预测物体的精确Mask,该技术广泛应用于数据标注、图像编辑等领域,其中“点击”凭借其高效与灵活性,逐渐成为交互分割中最主流的交互形式之一。
但随着目标对象复杂性和细节的增加,基于前背景点击的交互方式的优势逐渐减弱,因为在处理细小或复杂的目标区域时,准确点击对于精确定位的需求会大大降低交互效率,同时用户和设备友好性都非常有限。
为了解决这个问题,美图影像研究院(MT Lab)的研究人员提出了一种基于点击的交互式分割方法——NTClick,大幅降低了对精确点击的依赖,支持用户在处理复杂目标时,能凭借目标区域附近的粗略点击,预测精准的Mask。

NTClick 提出了一种全新的交互形式:噪声容忍点击,这是一种在选择细节区域时不需要用户精确定位的点击方式。
NTClick通过一个两阶段网络来实现对于粗糙交互的理解以及细节区域的精修:
第一阶段:Explicit Coarse Perception (ECP) 显式粗糙感知网络:
该阶段通过一个用于初步估计的显式粗略感知网络,在低分辨率下对用户的点击进行理解,并且预测出一个初步的估计结果-FBU Map。受到抠图技术中三元图的启发,FBU map将图像分为三类区域——前景、背景和不确定区域。其中,不确定区域通常对应细小或边缘模糊的部分,为后续精细化处理提供指导。
第二阶段:High Resolution Refinement (HRR) 高分辨率精修网络:
该阶段将 ECP 得到的FBU Map进行上采样,并与原始 RGB 图像拼接,输入到高分辨率精修网络中。HRR 网络专注于细粒度区域的像素级分类,通过稀疏网格注意力机制和近邻注意力机制的组合,在计算开销可控的前提下,在高分辨率下进行精细化感知,实现对微小结构(如植物细枝、精细雕塑等)的精准分割,输出最终的预测结果。

△
NTClick 两阶段架构
在包含精细目标的DIS5K等多个数据集上的实验结果显示,NTClick拥有明显更高的感知精度,并且在越复杂的场景下优势越明显。这表明,NTClick不仅保持了高效且用户友好的交互方式,在分割精度上也显著超过了现有方法。

△
实验结果
可视化结果也显示,NTClick 在处理细小目标(如首饰、线绳)时,相比传统方法具有更清晰的边界和更高的分割精度,同时用户的交互负担明显降低。

△
对比结果
近年来美图在分割算法上屡获突破,友好的交互方式叠加强大算法泛化能力,持续提升场景覆盖率与分割精细度,而对场景的理解深度与对用户体验的极致追求,也助力智能抠图这个垂类场景一跃成为美图设计室的王牌功能。

△
美图设计室智能抠图效果
SAM-REF:高精度场景下的交互式分割
交互式分割当前有两种主流方法,FocalClick、SimpleClick等早期融合(Early fusion)方法,这是现有专家模型所采用的方法,这类方法在编码阶段就将图像和用户提示进行结合以定位目标区域,但该方法基于用户的多次交互操作,需要对图像进行多次复杂计算,会导致较高的延迟。
相反的,Segment Anything Model (SAM)、InterFormer等后期融合(Late fusion)方法,能够一次性提取图像的全局特征编码,并在解码阶段将其与用户交互进行结合,避免了冗余的图像特征提取,大大提高了效率。
其中SAM 是具有里程碑意义的通用分割模型,尽管它具备高效性和强大的泛化能力,但由于采用晚期融合策略,限制了SAM直接从提示区域提取详细信息的能力,导致其在目标边缘细节处理上存在不足。例如,对于细小物体或纹理复杂的场景,SAM 往往会出现边界模糊或局部信息缺失的问题。
为了解决这一问题,美图影像研究院(MT Lab)的研究人员提出了两阶段细化框架——SAM-REF,能够在维持SAM运行效率的同时,提升 SAM的交互式分割能力,尤其是在高精度场景下。

SAM-REF在后期融合的基础上,引入了轻量级细化器(Refiner),从而在保持效率的同时,提升SAM在高精度场景下交互式分割能力,其核心结构包括:
全局融合细化器(Global Fusion Refiner, GFR)
该模块专注于捕获整个对象的详细信息,通过轻量特征提取,结合SAM的Embeds中的语义信息,利用图像和提示重引导来补充高频细节。
局部融合细化器(Local Fusion Refiner, LFR)
该模块对目标区域进行局部裁剪,并对局部细节进行精细化处理,避免对整个图像进行重复计算,提高计算效率。
动态选择机制(Dynamic Selector, DS)
通过分析目标区域的误差率,自适应选择 GFR 处理的全局特征,或者 LFR 处理的局部细节,以达到最佳分割效果。

△
SAM-REF核心架构
实验结果显示,SAM-REF在NoC90上相较于基线方法(如SAM和FocSAM)提升了16.3%,在NoF95减少了13.3%,同时Latency仅有早期融合方法(如FocalClick)的16.5%。可以看出,SAM-REF 在分割精度上有明显提升,且计算成本仅增加 0.003 秒/帧,基本维持了 SAM 的高效性。
可视化结果也显示,相较于SAM,SAM-REF在具有挑战性的场景中能更有效地识别纤细的结构,并能够在持续点击交互中提升分割精度。

△
SAM-REF的可视化结果
结合在交互分割领域的能力提升,美图旗下美图设计室为用户带来简单、高效、精准的智能抠图体验,用户无需精准点击,就能轻松调整选区。无论是人像、商品、复杂背景甚至发丝细节等难处理元素,分割质量都更加稳定,无需专业技能就可以获得高质量抠图。

△
美图设计室交互分割效果
EVPGS:基于3D高斯泼溅的外推视角合成
新视图合成(Novel View Synthesis, NVS)旨在生成与输入图像不同视角的新图像,但传统方法(如 NeRF、3D Gaussian Splatting)依赖于“数量较多”且“分布均匀”的训练视角来保证重建质量。
针对”数量较多“的要求,一些研究已经探索了极少视角(三张甚至更少)的三维重建方法。然而,在许多实际应用场景中,“分布均匀”却难以实现。例如,当用户手持手机绕物体或某个场景拍摄一圈时,往往能获得几十甚至上百张训练图像,但这些图像的视角通常集中在同一水平面上,缺少丰富的角度变化。
在这样的情况下,若尝试从俯视视角或仰视视角合成新图像,重建质量会显著下降。如下图所示,当拍摄的训练数据仅包含蓝色标记的水平视角时,尝试从红色标记的视角进行图像合成,结果往往出现严重的失真问题。

为应对此类实际应用挑战,美图影像研究院(MT Lab)的研究人员提出了基于增强视图先验引导的外推视图合成方案——EVPGS,解决高斯泼溅(Gaussian Splatting) 在外推视角下的失真问题,有效提升合成质量。

EVPGS的核心思想是在训练过程中得到外推视角的先验信息,应用视角增强策略来监督GS模型的训练。EVPGS可以生成可靠的视角先验,称之为增强视角先验(Enhanced View Priors),整个过程采用由粗到细(coarse-to-fine)的方式,对视角先验进行伪影去除和外观优化。
EVPGS技术实现路径分为三个阶段:
预训练阶段:
该阶段选用RaDe-GS作为Backbone,仅使用训练视角作为监督进行预训练。EVPGS可以支持不同的GS方法作为Backbone,均能在外推视角合成任务中取得显著的效果提升。
粗优化阶段:
该阶段选用Stable Diffusion 2.1模型对外推视角先验进行伪影去除,再使用预训练阶段得到的物体Mesh渲染的深度图,对GS模型直接渲染的深度图进行监督,二者分别从外观和几何两个维度对预训练模型进行正则化,有效提升了外推视角先验的表现。
细优化阶段:
该阶段采用几何重投影方法,从训练视角中寻找外推视角先验的对应像素值,并将其作为外推视角先验的像素。然而,该过程受到视角差异带来的遮挡和光照变化的影响,可能导致投影结果不准确。因此,该阶段还引入了遮挡检测策略与视角融合策略,有效缓解上述问题的影响,生成更加可靠的增强视角先验,用于监督 GS 模型的训练。

△
EVPGS训练方案
实验结果显示,在平均约30° 的外推角度下,相比于基于高斯泼溅的系列方法(3DGS、2DGS、GOF等),EVPGS 的细节保真度显著提高,纹理重建更清晰,无明显伪影。这也证明EVPGS可以接入到不同的GS Backbone中,并取得显著的效果提升,以RaDe-GS作为Backbone,在外推视角合成任务中达到了业界最佳效果。

△
实验结果
可视化结果显示,EVPGS比起Baseline有更少的伪影,能够恢复更多高频率的纹理和文字细节。

△
可视化结果

△
美图3D重建方案效果
此外,EVPGS主要针对物体场景的重建,但将其在室外场景数据集(Mip-NeRF360)上进行测试时,发现依旧可以取得不错的效果,这也进一步证明了EVPGS在外推视角合成任务的场景可扩展性。

△
EVPGS在室外场景数据集的实验结果