
我们在把PDF文档转换为Word的过程中,偶尔会遇到转换后乱码或者排版混乱的现象,给我们造成了极大的困扰。
为什么PDF转换成Word会乱码?乱码了之后要怎么办呢?下面就由软发网为大家讲解一下。
1、为什么PDF转换成Word会乱码?
PDF和Word是两种不同类型的格式,PDF特有的版式保证了文档的稳定性,而Word的流式布局更方便编辑,从PDF到Word转换过程中就涉及到了中间版式的转换,这个过程中就会出现机器识别转换的错误,导致转换出来的Word乱码。
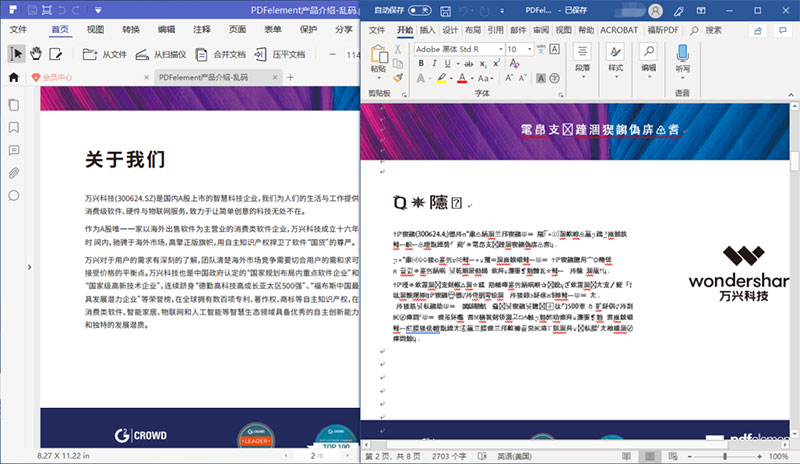
具体来说,转换乱码的原因主要有这几个:
1、原文档的文字编码丢失或不兼容。
2、文档转为PDF时使用了内嵌的字体。
3、PDF文档制作时没有严格按照PDF标准,反向转换时,也无法顺利反编译。
以上原因造成的乱码,用软件无论转换多少次都依然是乱码。
2、我们如何判断文档是否乱码呢?
不需要转换之后才知道文档是否乱码,只要打开PDF文档,选中里面的文字,复制出来看是否乱码, 如果复制出来是乱码,说明这个文档转换之后也会乱码。
3、PDF转换成Word后乱码怎么办?
那么要如何才能解决这个问题呢?这就要依靠我们强大的OCR技术啦。OCR,即光学字符识别,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字,把图像中的内容转成字符完成转换。图片越“干净”,文字识别准确率也会越高。反之,如果图片和文字黏在了一起,就会造成识别错误。

OCR是解决PDF转换Word乱码的好方法,但不是绝对万无一失的方法。在OCR转换之后如果还是有排版错乱和乱码的现象,就必须要手动微调了。现在网上也有一些人工文档处理平台可以提供这种服务,如果大家不想浪费时间也可以找他们帮你完成。