
作者 | Video++极链科技后端Team
整理 | 包包
Git分支和工作流
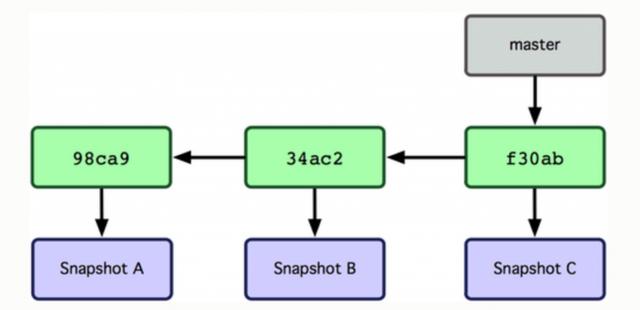
分支本质是一个指向提交对象的可变指针。Git 保存的不是文件的变化或者差异,而是一系列不同时刻的文件快照。在进行提交操作时,会保存一个提交对象(commit object),在多次提交后,commit对象形成连续的快照链,分支指针自动指向最新一次提交。Git 的默认分支名字是 master。如下图:

branch命令可以轻松创建一个新分支,就像这样:
$git branch new_branch
这一命令实际是为当前提交对象添加了一个新的指针。这种分支形式比大多数版本控制系统更为轻量,无论是创建还是切换都几乎可以在瞬间完成。Git 鼓励在工作流程中频繁地使用分支与合并,这完全不会增加仓库负担,并且可以基于这一特性创建更自由和更可靠的合作开发流程。
许多使用Git 的开发者都喜欢使用这种方式来工作:仅在master分支上保留完全稳定的代码,这些代码通常处于已发布或等待发布的状态。此外使用一些短期分支,比如用develop分支开发新特性,使用test分支修复bug,测试稳定性,直到代码质量达到发布要求,再合并到master分支,完成一个版本的开发。
不同的开发者团队可以自由创造适合自己组织形式的分支策略。社区中也存在许多深受欢迎的流程范例,比如经典的gitflow工作流、PR工作流、集中式工作流等等,它们通常适用于不同的合作方式,并不是某种强制规范。有兴趣的读者可以继续深入探索,此处不再过多介绍。
merge
假设我们基于master分支创建了feature分支用来开发新功能,经过一段时间开发之后,需要把feature的分支代码合并回到master,通常执行的操作是先检出master分支,然后执行git merge feature。
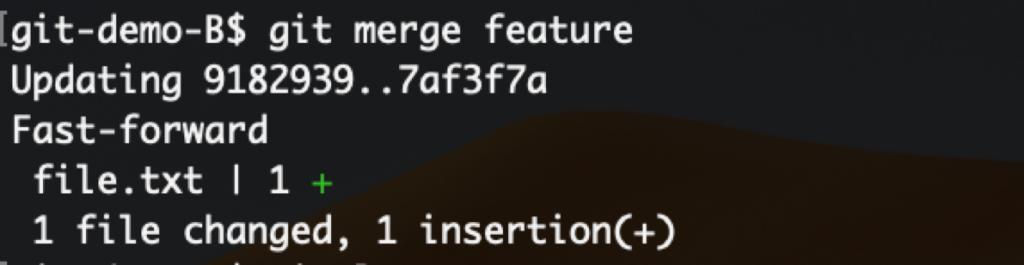
一般来说,在单人开发的情况下,merge通常会产生快进(fast-forward)方式的合并。如果在子分支(feature)被创建之后,父分支(master)未产生新的修改和提交,此时把feature合并回master,Git会在提交链上把master指针简单的前移,使两个分支进度同步,并形成无分支记录的提交链。执行时在控制台输出Fast-forward标识。这种merge方式下不会产生冲突,git log命令会看到如下记录:

但在团队合作开发时,通常会多人修改同一远程分支。其中使用的pull和push命令实际包含了merge操作。这时git使用另外一种方式来进行分支合并。目前只有一方修改的情况下,也可以使用 —no-ff 参数来模拟这种方式。
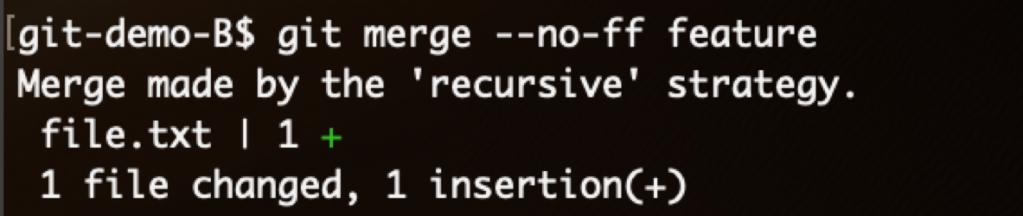
这里使用了git最基础的三路递归合并(recursive three-way merge),输出Merge made by the 'recursive' strategy.标明合并方式。这种合并会形成带分支历史的提交链:
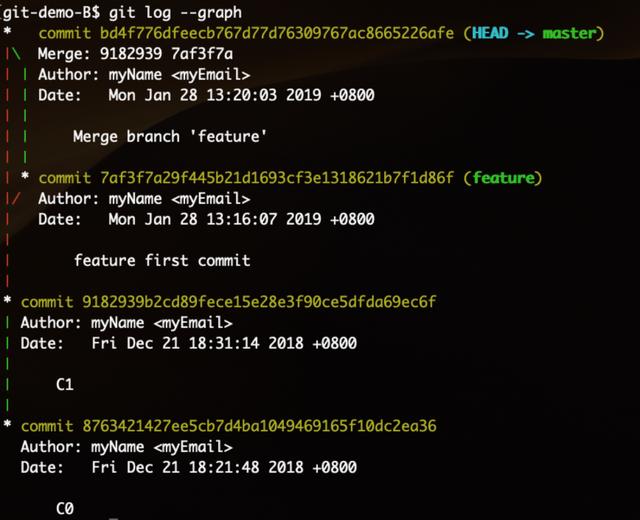
从图中可以看出,这种merge方式实际在发起合并的分支生成了一个带有Merge 标识的新提交。如果合并时存在冲突,解决冲突后的最终内容也会包含在这个新的提交中。
看到这里,可能有人会有疑问,工作空间中自始至终只出现了两个分支,为什么会是三路合并。从git 源码中可以找到merge执行的入口,它有这样的方法签名:

可以看出,除了含义明显的ours和theirs,还有一个待合并的文件叫做ancestor。根据文档和源码注释,这个版本实际是两个待合并分支的公共部分。在我们的例子中就是创建新分支的那个提交对象。
大体的流程是这样的,git merge会找出两个分支指向的最新commit,找到他们最近的公共祖先,然后对每个待合并的文件调用ll_merge,这个方法会比较各分支和祖先节点的差异。然后把这些差异整合成一个Merge提交,应用到当前分支上,生成最终的合并结果。
如果两个分支之间有多个公共祖先,git会选出最合适的祖先节点依照同样规则进行递归合并。可以使用git merge-base —all命令列出所有的备选祖先节点。
Git还可以一次性合并多个分支,只需要简单的把分支名当做merge的参数依次列出:
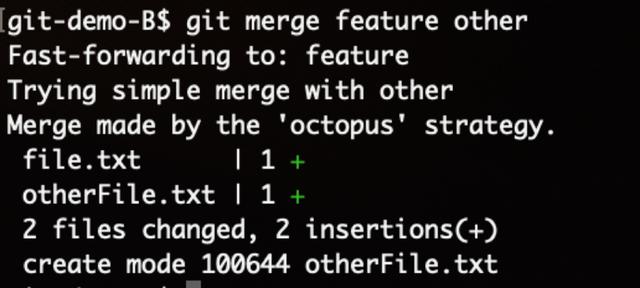
这种策略被称为octopus,其中核心逻辑与three-way merge相同,不再详述,可以通过阅读github上的源码和文档继续深入了解。
three-way merge机制有一定的隐患。如果其中一个待合并分支,比如ours,和ancestor版本的某一部分代码相同,但另一个待合并分支theirs中有不同的修改,合并的结果就会采用theirs分支不同的那部分,并不会依照修改的时间顺序来决定最终内容。在实际项目中可能会反复修改同一段代码来响应需求变更,就有几率发生这种合并结果与预计不符的情况,需要特别留意。
rebase
Git rebase,通常被称作变基或衍合, 可以理解为另外一种合并的方式,与merge 会保留分支结构和原始提交记录不同,rebase 是在公共祖先的基础上,把新的提交链截取下来,在目标分支上进行重放,逐个应用选中的提交来完成合并。
为了形象理解rebase的过程,可以看下面例子:
使用 merge 合并后:
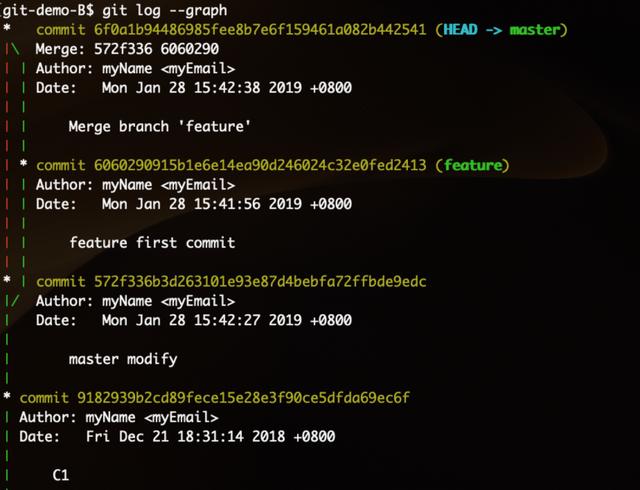
下面使用rebase方式达到同样效果:
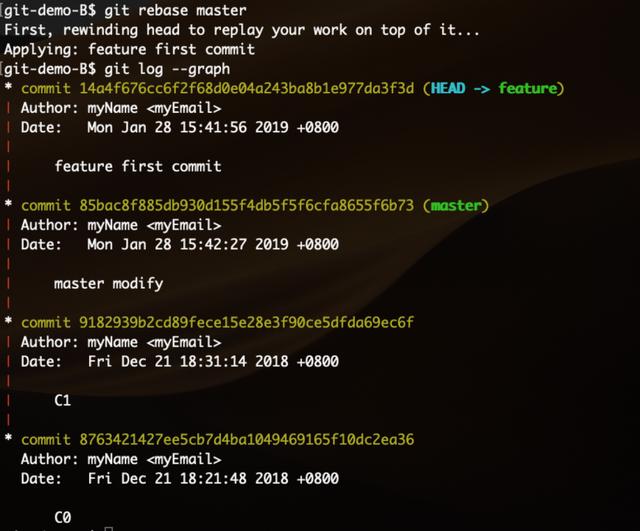
除了原本的多分支记录变为了直线提交链,还可以注意到,其中原本在feature分支上的提交,rebase后的SHA编码发生了变化。rebase消除了真实历史,重新生成了新的提交。
和merge类似,rebase在遇到冲突时也会暂停,需要手动修复后才可以继续。但是rebase的处理要相对繁琐一些,merge 如果发生 conflict,只需要在最终的Merge 提交上解决一次。而 rebase 的 conflict 可能发生在每一次提交的重新应用上,所以需要依次解决。
为了避免这种情况,可以在与另一分支合并之前,提前把所有需要提交合并为一个提交。同样需要用到rebase命令。
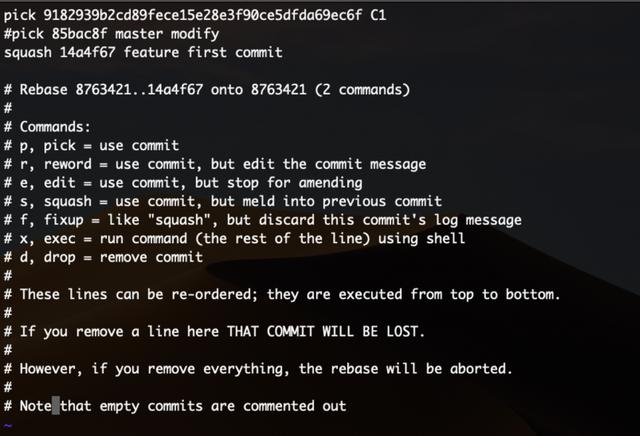
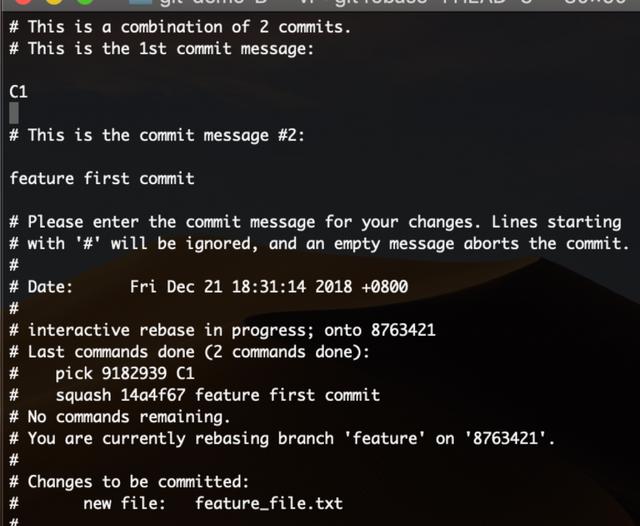
执行这样一个命令来合并当前最新的3个提交:

这条命令将打开一个编辑页面,我们可以修改前面的命令来合并或丢弃单个提交。
pick 表示将会应用这个提交。
squash 表示把当前提交合并到前一个提交,它的前面必须至少有一个被pick的提交存在。
把某条提交注释或删除表示丢弃这条记录。
这里选择合并第一个和第三个,丢弃第二个提交。
保存退出后进入新的编辑页面,提示编辑提交信息,这里选择不做改动。
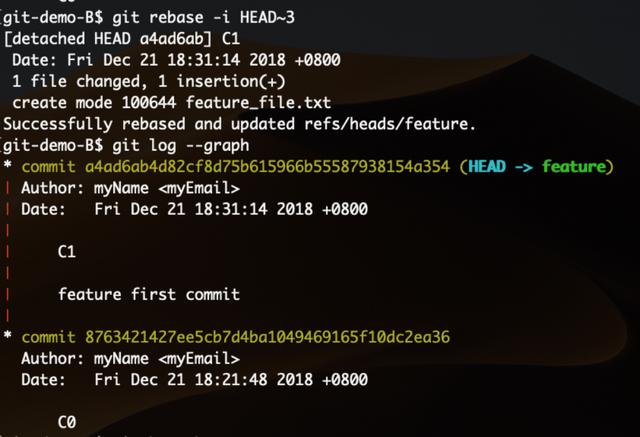
再次保存退出后成功合并完成,形成这样的log:
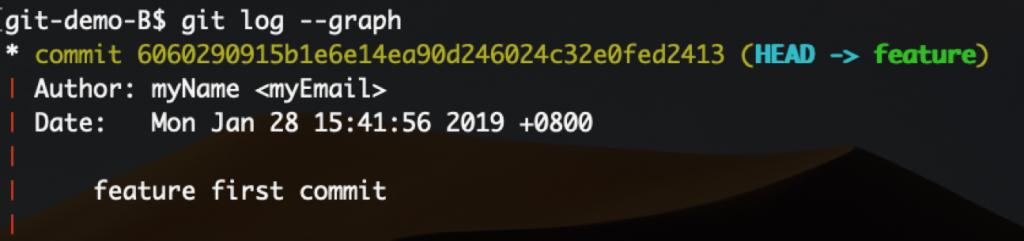
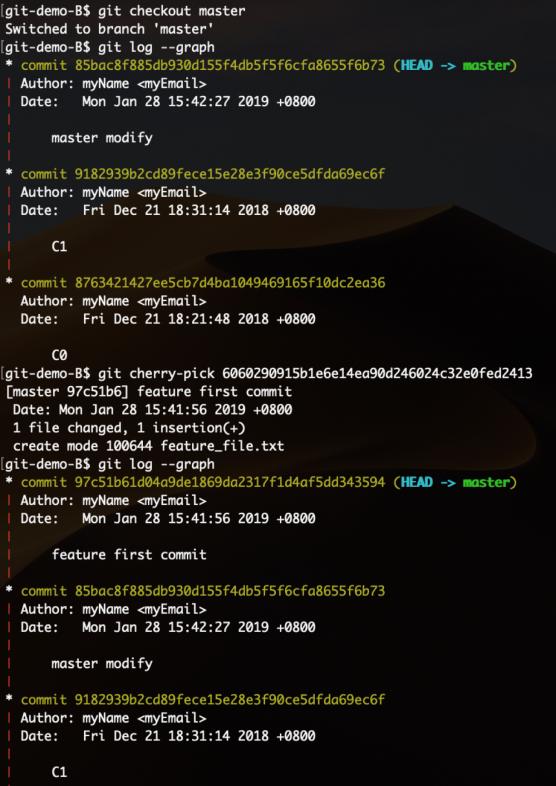
git还有一个可爱的命令cherry-pick,通常译作拣选。它的参数是提交对象的SHA编码,可以视为针对单个提交的rebase操作。示例如下:
总结
merge 和 rebase 的差异在于最终的历史记录,可以发现 merge 保持了所有分支的原始修改记录,可能会包含很多不必要的信息;而 rebase相当于对历史记录做出修剪,可以维持一条简单清晰的提交路线。
通常我们会在基于一个过时的版本进行了本地修改的情况下使用rebase,在实际开发中经常会出现这种情况,当你在本地分支上工作了几天,突然想起应该push到远程仓库时,远程分支已经被别人更新过了。此时你会得到一个reject信息。
有些人会选择用pull命令合并远程和本地的同名分支,但pull实际执行了fetch和merge两个操作,会生成复杂的分支历史和一个多余的merge提交。你也可以选择用fetch和rebase代替pull,始终生成一个美观的提交链。
rebase的另一个重要应用是合并过多的本地提交。因为防止修改内容丢失,经常commit到本地仓库是一个很好的开发习惯。但是当需要提交到公共分支时,大量无明确意义的提交信息对历史记录造成不必要的干扰。此时你可以用rebase命令把本地记录规范化,再进行推送。
使用rebase的时候需要遵循一条重要原则:不要对在你的本地仓库外有副本的提交记录进行变基。rebase的实质是丢弃一些现有的提交,然后相应地新建一些内容一样但实际上不同的提交。 如果其他人已经在这些提交上做出过大量修改、冲突合并等工作,那么你的rebase将成为他们的恶梦。
对于使用rebase还是merge来合并代码,实际并没有什么固定的模式,取决于开发者如何看待仓库的历史记录。一些人认为历史记录应该反映全部真实变更细节,而另一些人认为历史记录应该是精心维护的变更目录。具体如何使用取决于项目合作者的一致共识。无论是merge还是rebase,都应该了解其中原理,避免危险操作,才能享受到Git诸多特性带来的便利。