

当前,联汇科技OmAgent开源智能体Om智能助手的内测申请通道已经正式开启,会看、会听、会思考的Om智能助手能够满足不同用户的个性化问题与需求,成为用户的私人助理。
特别值得一提的是,它的“视觉识别”能力尤为出色:当你拍摄一张菜单的照片,Om智能助手就能迅速识别并读出上面的菜名;或者当你拍下一张历史建筑的照片时,它还能提供关于该建筑的详细信息和背景故事……
那么,为什么Om智能助手能够看懂拍摄的文字或者图像?这与驱动其工作的Om多模态大模型密切相关。
OmClip是Om多模态大模型系列之一,作为多模态大语言模型(Multimodal Large Language Models, MLLMs),能够同时处理文本和图像数据,它不仅可以理解和生成文本,还能“看懂”图片,并对图片内容进行描述或回答相关问题。
其中,在多模态大语言模型中负责处理图像的部分叫作“视觉塔(Vision Tower)”,它的作用是将图像转换成模型可以理解的数字表示(称为特征或嵌入),相当于人类的眼睛。而光学字符识别OCR(Optical Character Recognition)是将图片中的文字转换成可编辑的文本,它是模型“识字”的基本能力。
为了让OmClip具备优越的识别能力,联汇研发团队在其中融入了多项技术创新,大幅提升了OmClip的识别性能。
技术创新
1、解冻视觉塔
在训练过程中,我们允许视觉塔的参数发生变化,就像是让一个已经学会识别物体的“眼睛”继续学习新的东西,比如识别中文的文字。
2、多层特征提取
我们不仅使用视觉塔最后一层的输出,还利用了中间层的信息,这种做法类似于同时观察物体的轮廓和细节,使模型更全面、更深入地理解图像内容。
3、专注于图像描述和OCR数据
在训练数据中,我们只保留了图像描述和OCR相关的数据,让模型专注于学习“看图说话”和“读图中的字”这两项任务。
4、基于SigLip的针对性训练
SigLip是多模态大语言模型主流视觉塔之一,我们利用了300亿量级的数据进行针对性训练,让视觉塔在保持SigLip常见物体识别优势的同时,学习编码中文OCR的特征。
为了验证OmClip能力,我们进行了相关实验。
数据集
我们以中文OCR为测试基准。由于SigLip视觉模型训练中不存在大量中文OCR数据集,所以对于基于SigLip的OmClip来说,该任务可以很好地测量在预训练过程中解冻视觉塔以增加新能力的效果。基于复旦大学视觉智能实验室(FudanVI)发布的中文文本识别基准数据集,包括网页文本、文档文本。为了提升难度,我们把语义不相关的多条文本拼接在一起,作为一张图片,最终得到训练集57k,验证集1k。
相关论文
Chen, J., Yu, H., Ma, J., et al. Benchmarking Chinese Text Recognition:Datasets, Baselines, and an Empirical Study. arXiv preprint arXiv:2112.15093, 2021.
实验结果
实验中,我们对四个模型的表现进行了比较:
1、原始SigLip
2、使用多层特征的SigLip
3、Llava OV SigLip
4、联汇的OmClip V
通过以两个指标评估模型性能:
1、整体准确率(Overall Acc):完全正确识别一张图片中所有文字的比例。
2、标准化编辑距离(Normalized Edit Distance):衡量模型输出与正确答案的差异程度,数值越小越好。
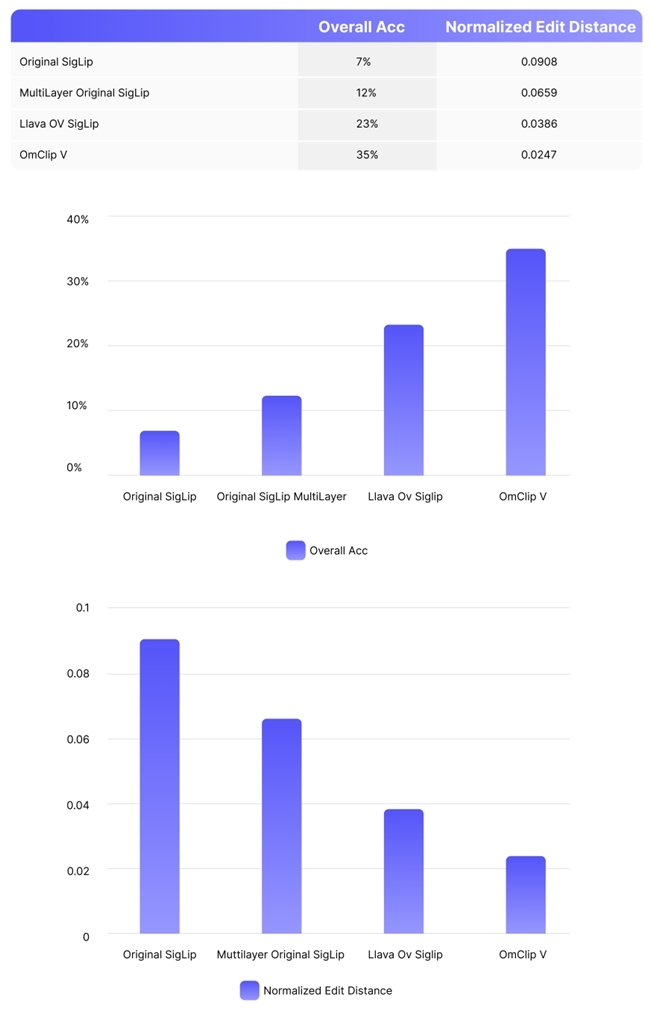
结果分析
实验结果清晰地表明:我们提出的方法在中文OCR任务上拥有显著优势。
1、中间层特征提取的效果
原始SigLip模型的准确率为7%,标准化编辑距离为0.0908。
使用多层特征(MultiLayer)后,SigLip的性能显著提升:
— 准确率提高到12%,相比原始模型提升了71.4%;
— 标准化编辑距离降低到0.0659,改善了27.4%。
这些数据支持了我们从视觉塔中间层提取特征并与最后一层特征结合的创新方法,能够即时提升视觉塔的性能。
2.、(解冻视觉塔)的突出表现
Llava OV SigLip模型的准确率为23%,标准化编辑距离为0.0386。
我们的OmClip V模型取得了最佳性能:
— 准确率达到35%,比Llava OV SigLip提高了52.2%,比原始SigLip提升了400%;
— 标准化编辑距离降低到0.0247,相比Llava OV SigLip改善了36%,相比原始SigLip改善了72.8%。
这一结果强有力地证明了在预训练过程中解冻视觉塔的有效性、先进性,特别是在增强模型处理中文OCR等新任务的能力方面。
实验证实,通过多层特征提取和视觉塔解冻预训练的两大关键创新点,不仅显著提升了模型在中文OCR任务上的性能,还为进一步改进视觉语言模型开辟了新的方向。
目前,OmAgent智能体框架已强势开源。
免责声明:本文为商业广告,仅为传递更多信息之目的,不代表本网观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。部分图片来源于网络,若遇侵权将第一时间删除。