

参与:杜伟、楚航、罗若天
本周重要论文包括:RSS 2022 和 NAACL 2022 各项获奖论文。
目录:
Solving Quantitative Reasoning Problems with Language Models
Human Action Recognition from Various Data Modalities: A Review
FNet: Mixing Tokens with Fourier Transforms
Iterative Residual Policy for Goal-Conditioned Dynamic Manipulation of Deformable Objects
VGSE: Visually-Grounded Semantic Embeddings for Zero-Shot Learning
Label Relation Graphs Enhanced Hierarchical Residual Network for Hierarchical Multi-Granularity Classification
Zero-Shot Logit Adjustment
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文1:Solving Quantitative Reasoning Problems with Language Models
作者:Aitor Lewkowycz等
摘要: 在 Google Research 提交的这篇论文中,他们推出了语言模型 Minerva,该模型能够解决数学和科学问题,让模型一步一步来。通过收集与定量推理问题相关的训练数据、大规模训练模型,以及使用先进的推理技术,该研究在各种较难的定量推理任务上取得了显著的性能提升。
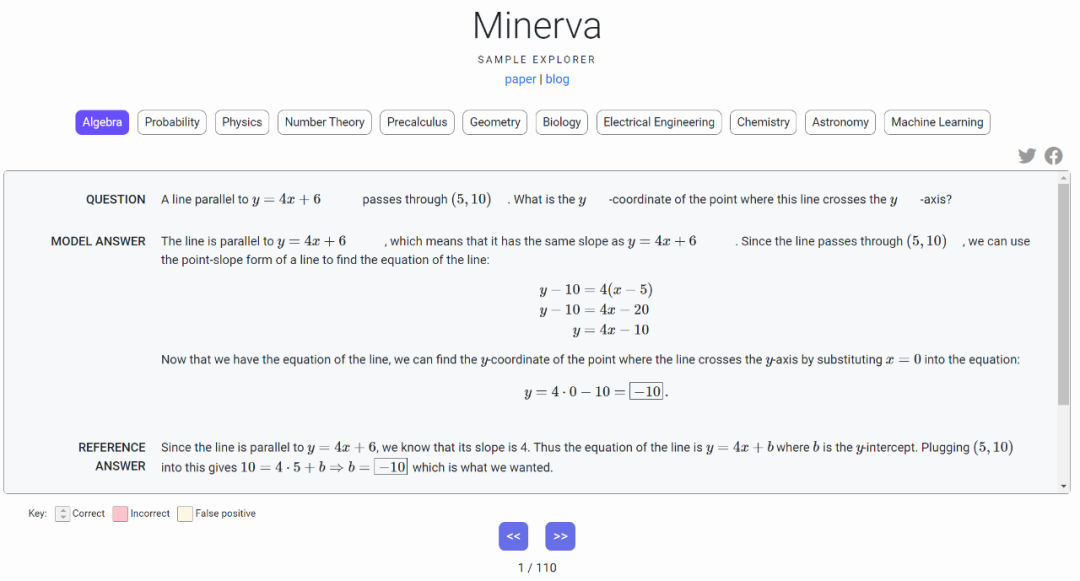
Minerva界面。

Minerva解数学题示例。

Minerva模型变体。
推荐: 人工智能学会数学推理了,考试成绩比CS博士还高。
论文2:Human Action Recognition from Various Data Modalities: A Review
作者:Zehua Sun等
摘要: 人类行为识别旨在了解人类的行为,并为行为指定标签,例如,握手、吃东西、跑步等。它具有广泛的应用前景,在计算机视觉领域受到越来越多的关注。人类行为使用各种数据模态来表示,如 RGB、骨架、深度、红外序列、点云、事件流、音频、加速信号、雷达和 WiFi,这些数据模态在不同的场景下具有不同的优势。
研究者基于主流深度学习,对当前基于深度学习的行为识别方法进行了全面的综述,涉及多种数据模态。本文已被TPAMI 2022收录。

HAR的基于RGB深度学习方法概览。

UCF101、HMDB51和Kinectis-400数据集上,HAR的基于RGB视频的深度学习方法性能比较。

基于骨骼的HAR的深度学习框架概览。
推荐: 最新综述基于不同数据模态的行为识别。
论文3:FNet: Mixing Tokens with Fourier Transforms
作者:James Lee-Thorp等
摘要: 自推出以来,Transformer 一直是语言建模多项进展的基础,部分原因在于其学习的注意力权重。然而,随着参数量的增加,Transformer 模型需要更多的算力来训练。
本文用混合输入 token 的未参数化傅里叶变换替换了 transformer 架构中的自注意力层。与类似的 Transformer 模型相比,替换之后的模型在 GPU 上的训练速度提高了 80%,在 TPU 上的训练速度提高了 70%,同时在许多任务中的准确性都能和原模型媲美。这项创新还让模型能够处理更长的输入序列,让未来研究远程上下文成为可能。NAACL 委员会称赞了该团队对大型语言模型效率的贡献。

具有N个解码器块的FNet架构。

在各自任务上微调后,TPU上的GLUE验证结果。

GPU预训练的速度-准确率权衡。
推荐: NAACL 2022最高效NLP论文。
论文4:Iterative Residual Policy for Goal-Conditioned Dynamic Manipulation of Deformable Objects
作者:Cheng Chi等
摘要: 该论文研究了可变形物体的目标条件动态操作问题。基于其复杂的动力学 (物体变形和高速动作) 和严格的任务要求(精确的目标规范),这项任务非常具有挑战性。为了应对这些挑战,研究者提出了迭代剩余策略(IRP) ,这是一个适用于具有复杂动力学的可重复任务的通用学习框架。
研究证明了IRP在两个任务上的有效性: 抽打一根绳子以击中目标点;放置布料以达到目标姿态。尽管只是在固定的机器人装置上进行模拟训练,IRP 能够有效地推广到现实世界中具有看不见的物理属性的新目标,甚至不同的机器人硬件实施,这表明了其相对于其他方法的优秀推广能力。
这篇论文由哥伦比亚大学和丰田研究院的几位研究者共同完成,其中包括两位中国学者。

图上为以目标为条件的动态Rope操作,图下为以目标为条件的动态Cloth操作。

迭代残差策略。

不同Rope的同一个动作。
推荐: RSS 2022最佳论文。
论文5:VGSE: Visually-Grounded Semantic Embeddings for Zero-Shot Learning
作者:Wenjia Xu等
摘要: 北京邮电大学、马普所等机构的研究者提出了类别嵌入发掘网络(Visually-Grounded Semantic Embedding Network, VGSE),本文主要回答了两个问题:如何从可见类图像中自动发掘具有语义和视觉特征的类别嵌入;如何在没有训练样本的情况下,为不可见类别预测类别嵌入。
为了充分挖掘不同类别之间共享的视觉特征,VGSE 模型将大量局部图像切片按其视觉相似度聚类形成属性簇,从图像底层特征中归纳不同类别实例所共享的视觉特征。此外 VGSE 模型提出类别关系模块,在少量外部知识源的辅助下学习类别关系,能够将知识从源类别转移到目标类别,为没有训练图像的目标类别预测其类别嵌入。相较于其他基于语料自动挖掘而获得的属性,VGSE 模型在 CUB、SUN、AWA2 等零样本分类数据集上取得非常有竞争力的结果。
本论文已被 CVPR 2022 录用。

VGSE模型结构。

挖掘属性簇可视化结果。

结果比较。
推荐: 大幅减少零样本学习所需的人工标注,马普所和北邮提出富含视觉信息的类别语义嵌入。
论文6:Label Relation Graphs Enhanced Hierarchical Residual Network for Hierarchical Multi-Granularity Classification
作者:Jingzhou Chen等
摘要: 传统的图像识别数据集类别设定中,针对某个特定任务例如通用图像分类任务或者细粒度分类任务,类别标签往往只位于同一层级中,无法鲁棒地利用标注到不同层级上的图片,对标注的要求较高。
为了降低图像质量以及背景知识等带来的对标注数据的高要求、充分利用具有不同层级粒度标签的样本,设计建模目标层级语义结构的层级多粒度识别算法对于提升深度神经网络的鲁棒性具有十分重要的作用。
为此,浙江大学联合蚂蚁集团提出了一种基于标签关系树的层级残差多粒度分类网络,收录到 CVPR2022 中。

层级残差网络结构。

CUB-200-2011上与SOTA方法的比较。

各个数据集、不同重标记比例下对比方法的平均OA/结果。
推荐: 基于标签关系树的层级残差多粒度分类网络,建模多粒度标签间的层级知识。
论文7:Zero-Shot Logit Adjustment
作者:Dubing Chen 等
摘要: 南京理工大学和牛津大学的研究者提出了一个即插即用的分类器模块,只需修改一行代码就能大幅提升生成型零样本学习方法的效果,减少了分类器对于生成伪样本质量的依赖。
本文以一致化训练与测试目标为指引,推导出广义零样本学习评测指标的变分下界。以此建模的分类器避免使用重采用策略,防止分类器在生成的伪样本上过拟合对真实样本的识别造成不利影响。所提方法能够使基于嵌入的分类器在生成型方法框架上有效,减少了分类器对于生成伪样本质量的依赖。
本文已被IJCAI 2022会议接收。

GZSL与SOTA方法的比较。

纯原型学习器与基于生成的ZLA原型学习器之间的比较。
推荐: 用一行代码大幅提升零样本学习方法效果,南京理工&牛津提出即插即用分类器模块。
© THE END