


作者 | 刘千惠、邢东
编辑 | 蒋宝尚
过去的十年以深度神经网络为代表的人工智能技术深刻影响了人类社会。但深度神经网络的发展已经进入瓶颈期,我们仍处于弱人工智能时代。如何更近一步,跨入强人工智能,敲击着每一位智能研究者的心。
算法提升,则是走向强人工智能的一个方向;而受脑启发的硬件设计,则是人工智能的另一方向。
在硬件层面上,智能研究如何从对人脑的研究中受益?随着我国在类脑计算方面的深入,已有越来越多的学者开始拷问这一问题。
2020年4月25日,在未来论坛青创联盟线上学术研讨中,开展了AI+脑科学的主题讨论,共有六位嘉宾发表演讲,从Brain Science for AI和AI for Brain Science两个不同的视角进行前沿讨论。
其中来自清华大学的吴华强老师做了题目为“大脑启发的存算一体技术”的报告。在报告中吴教授介绍到:当思考未来计算的时候,量子计算、光计算是向物理找答案,类脑计算、存算一体是向生物找答案,也就是向大脑找答案。
目前吴老师正在芯片上做电子突触新器件,做存算一体的架构。新器件方面主要研究的是忆阻器,它的特点是可以多比特,同时非易失,即把电去掉可以保持阻值,并且它速度很快。
另外,吴老师还提到,其用存算一体的计算结构设计的芯片与树莓派28纳米的CPU做过对比,在准确率相当的情况下,前者运行一万张图片是3秒,后者是59秒。

吴华强, 清华大学微纳电子系教授,清华大学微纳电子系副系主任,清华大学微纳加工平台主任,北京市未来芯片技术高精尖创新中心副主任。
吴华强:
我的报告将从硬件的挑战,研究进展以及展望三方面来介绍大脑启发的存算一体技术。
人工智能无处不在,从云端到我们手机端都有很多人工智能。不同的人工智能应用对芯片的需求是不一样的,比如数据中心、汽车无人驾驶要求算力特别高,而智能传感网、物联网和手机希望耗能低,追求高能效。不同应用对芯片的不同需求给了芯片领域很多机会。
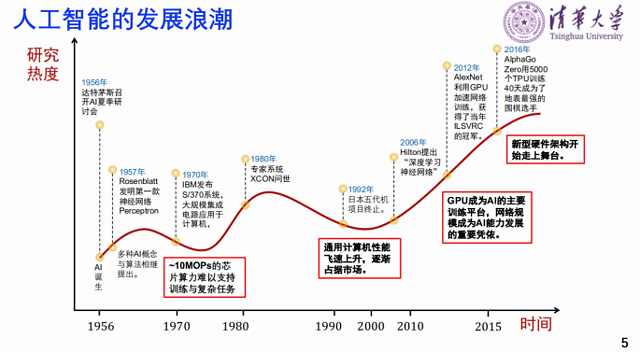
人工智能的三个发展浪潮和硬件算力也有关系。
从第一款神经网络Perceptron 网络AI开始火起来,到70年代进入低谷,一个非常重要的因素是,虽然有很好的理论模型,但是没有足够的算力。
后来专家系统出现,第二波浪潮又起来。这时候很多人做专门围绕人工智能的计算机。同时代摩尔定律快速推动芯片的发展,通用计算机的性能飞速上扬,专业计算机能做的通用计算机也能做,因此逐渐占据市场,第二波浪潮又下去。
第三波浪潮,深度神经网络的提出到利用GPU加速网络训练,GPU成为AI的主要训练平台。有了更大的算力,网络规模快速提升。AlphaGo Zero需要5000个TPU训练40天才成为地表最强的围棋选手,花费的时间还是很大的,因此人工智能的广泛应用需要硬件能力革新,支撑人工智能的发展。
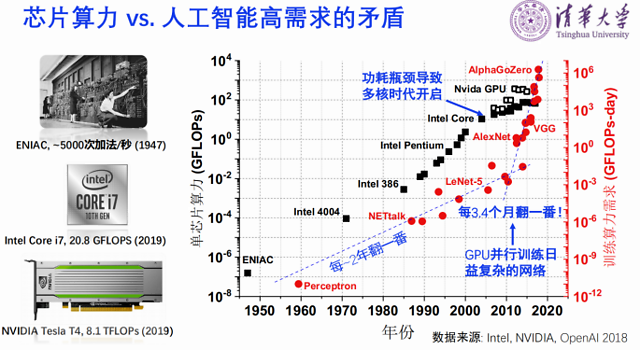
芯片能提供的算力和人工智能的高需求是很矛盾的。第一台计算机ENIAC出现在1947年,算力是每秒钟5000次左右。英特尔2019年的CPU大约是20.8GFLOPS。我们看到它的变化是围绕着摩尔定律,即每18个月翻一番的集成度来提升算力。但是目前AI的需求是每3.4个月翻一番。因此需要寻找新方法提供算力。
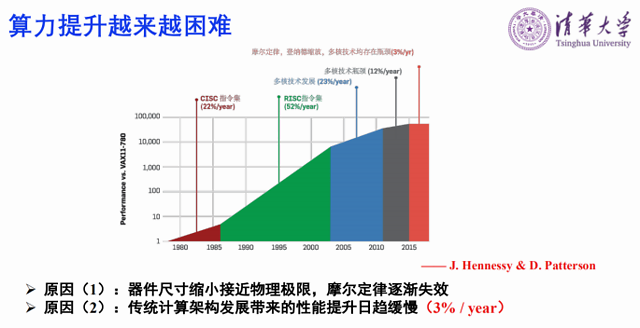
算力提升越来越困难有两个原因,一是过去摩尔定律是把器件做的越来越小,现在器件尺寸缩小已经接近物理极限了,所以摩尔定律逐渐失效。二是传统计算架构发展带来的性能提升日趋缓慢。现代计算系统普遍采用信息存储和运算分离的冯诺依曼架构,其运算性能受到数据存储速度和传输速度的限制。具体来说,CPU的计算速度小于1纳秒,但是主存DRAM是百纳秒左右,也就是存储的速度远远低于计算速度。
在能耗上,以TSMC45纳米的工艺为例,加减乘小于一个pJ,但是32位DRAM的读要高达640个pJ,这一比也是百倍的差距。因此存储速度远远低于CPU的速度,而存储的功耗也远远高于CPU的功耗。这还没有讲存储的写,写的功耗会更高。这样整个系统的性能受到数据存储速度和传输速度的限制,能耗也因为存储读的功耗和写的功耗很大,导致整个系统功耗都很大。

现在可以看到很多新的计算出来了,量子计算、光计算、类脑计算、存算一体。所以当我们要思考未来的计算时,我自己觉得量子计算、光计算是向物理找答案,类脑计算、存算一体是向生物找答案,也就是向大脑找答案。
著名的人机大战,人工智能选手 AlphaGo用了176个GPU、1202个CPU,功耗是150000W。而我们大脑体积大概1.2L,有10^11个神经元,10^15个突触,思考的时候功耗是20W。大脑的功耗这么少,这么聪明,这里面还有这么大容量的神经元、突触。所以我们希望用脑启发设计新的人工智能芯片。
我们想通过向生物学家学习、向神经学家学习,来看看大脑是如何处理计算的。大脑有几个特点,一个是有大量的神经元连接性,以及神经元加突触的结构,一个神经元将近连接了1万个突触。第二个它的时空信息的编码方式是用脉冲的方式。我们希望模仿大脑的结构和工作机制,用脉冲编码的形式来输入输出。
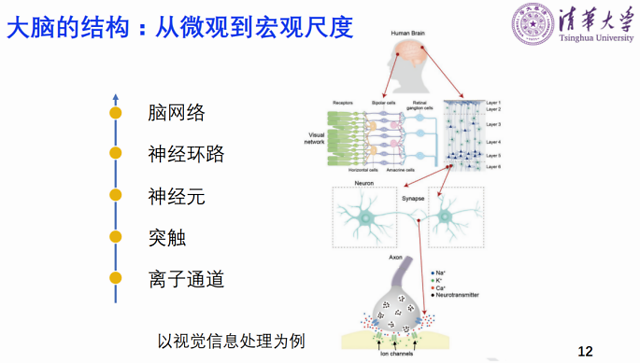
生物突触是信息存储也是信息处理的最底层的生物器件。我们想在芯片上做电子突触新器件,做存算一体的架构。新器件方面我们主要研究的是忆阻器,它的特点是可以多比特,同时非易失,即把电去掉以后可以保持这个阻值,并且它速度很快。还有很关键的一点,它和集成电路的CMOS工艺是兼容的,可以做大规模集成。近十年我们一直围绕这个器件来做其优化和计算功能。
美国DARPA的FRANC项目提出用模拟信号处理方式来超越传统的冯·诺依曼计算架构,希望带来计算性能系统的增加。任正非在2019年接受采访时说,未来在边缘计算不是把CPU做到存储器里,就是把存储器做到CPU里,这就改变了冯·诺依曼结构,存储计算合而为一,速度快。阿里2020年的十大科技趋势里提到计算存储一体化,希望通过存算一体的架构,突破AI算力瓶颈。存算一体的理念也是受大脑计算方式启发的。
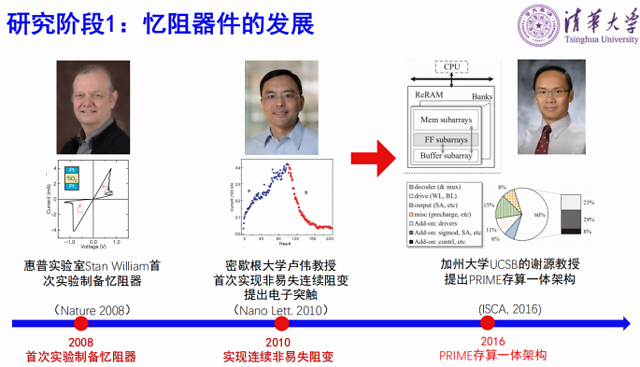
基于忆阻器的存算一体技术可以分为三个阶段:第一个阶段是单个器件的发展阶段。2008年惠普实验室的Stan William教授首次在实验室制备了忆阻器,之后美国密西根大学的卢伟教授提出了电子突触概念,美国UCSB大学的谢源教授提出了基于忆阻器的PRIME存算一体架构,引起广泛关注。
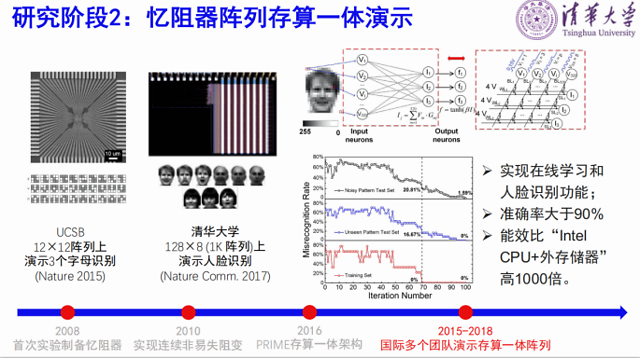
第二个阶段开始做阵列,2015年UCSB在12×12的阵列上演示了三个字母的识别,我们团队2017年在128×8的阵列上演示了三个人脸的识别,准确率能够大于95%,同时期还有IBM,UMass和HP等研究团队实验实现了在阵列上的存算一体。
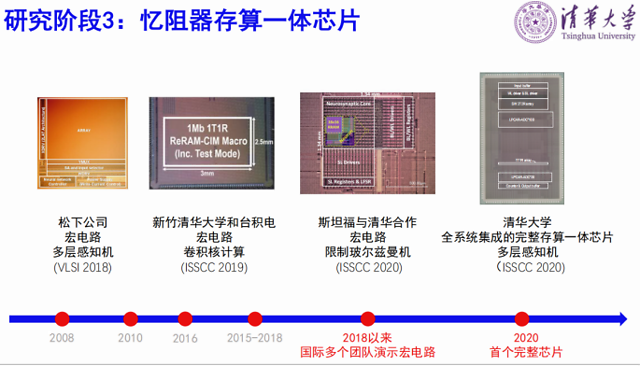
第三个阶段是存算一体芯片,我们以芯片设计领域的顶会ISSCC上近几年发表的文章为例,2018年松下展示了多层感知机的宏电路,2019年台湾地区新竹清华大学和台积电联合演示了卷积核计算的宏电路,今年清华和斯坦福合作做的限制玻耳兹曼机宏电路。
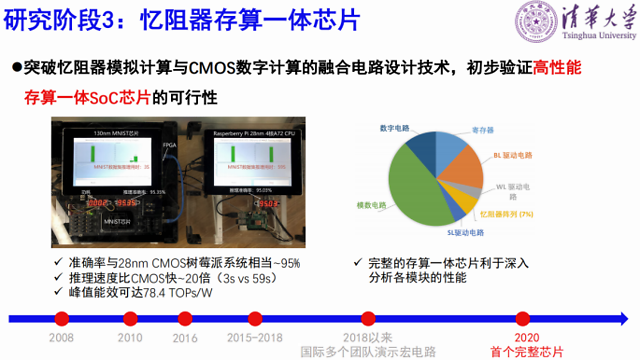
也是今年我们清华团队完成的一个全系统集成的完整的存算一体芯片,从系统测试结果来看,这个芯片能效高达78.4TOPs/W,是相当高的。我们还做了一个对比,一个是存算一体的芯片和系统,一个是用了树莓派28纳米的CPU。我们的芯片跑完一万张图片是3秒,而他们是59秒,我们的速度要快很多,准确率却相当。
今年1月我们在Nature上发表了一个忆阻器存算一体系统的工作。这个工作主要是把多个阵列放在一起组成一个系统,并验证是否能用作模拟计算来实现AI的工作。我们提出新型混合训练算法,实现了与软件相当的计算精度。还提出了新型卷积空间并行架构,成倍提升了系统处理速度。
为什么忆阻器存算一体适合人工智能呢?因为交叉阵列结构特别适合快速矩阵向量乘法。存算一体可以减少权重搬移带来的功耗和延时,有效地解决目前算力的瓶颈。另外,人工智能更关注系统准确性,而不是每个器件的精度,这特别符合忆阻器和模拟计算的特点。
我们还和毕国强老师合作了一篇综述文章。利用脑启发来设计人工智能芯片,我们把大脑从I/O通道,到突触,神经元,到神经环路,到整个大脑的结构,都和电子器件做了对比。文章题目叫《Bridging Biological and Artificial Neural Networks》,发表在2019年的Advanced Materials上面,如果大家感兴趣可以读这个文章。
展望未来,希望能够做一个存算一体的计算机系统。以前是晶体管加布尔逻辑加冯·诺依曼架构,现在是模拟型忆阻器加模拟计算和存算一体的非冯架构。
OMT:脑科学是如何助力AI的
在演讲报告之后,来自中国科学技术大学神经生物学与生物物理学系系主任毕国强老师,来自北京大学信息科学技术学院长聘教授吴思老师和三位报告演讲老师就脑科学已经为AI发展提供了什么思想、方法和技术?有哪些典型案例?做了激烈的讨论。
在会上胡晓林提到:有很多工作其实是从脑科学启发过来,追根溯源到1943年,麦克和皮茨这两个人第一次提出人工神经元MP神经元,如果没有他们提出人工神经元,后面的这些CNN等等都是不存在的,他们其实是做神经科学的,他们尝试发明计算模型并解释大脑的工作,他们提出了这种逻辑运算的MP神经元。后来Rosenbaltt把MP神经元扩展了一下,得到了多层感知机。后来在1989年、1990年的时候Yan LeCun等人提出来CNN,当时是受了Neocognitron模型的启发,Neocognitron是日本人Fukushima提出来的,我真的找过他那篇论文,Neocognitron的结构和现在CNN的结构一模一样,唯一区别是学习方法不一样,Neocognitron在1980年提出来时还没有BP算法。Neocognitron怎么来的呢?它是受到一个神经科学的发现,在猫的视觉皮层有简单细胞、复杂细胞两种细胞,从这两种细胞的特点出发构建了Neocognitron尝试去解释大脑怎么识别物体的。后来才发展到CNN。MP神经元和Neocognitron这是两个具有里程碑意义的方法,这是很典型的神经科学给我们AI的启发的工作,甚至可以说是颠覆性的工作。
坦白说到这次神经网络、人工智能的腾飞,这次腾飞期间我并没有看到特别多令人非常兴奋的脑启发的工作,我本人也做了一些这方面的工作,发现目前一些受脑科学启发的计算模型好像都没有我刚才说的那两个模型的意义那么大。希望这个领域能出现一些新的脑启发的方法,哪怕它们现在的性能非常差,但是十几年、几十年以后,它们也许会成为奠基性的工作。
吴思:我们要看我们怎么定义AI。如果泛泛的包括信息理论、动力学系统分析、统计学习等,那么这些都是计算神经科学每天在用的工具,它们一直在助力脑科学的发展。如果一定要强调最新的,比如说深度学习,那么如何将AI用于脑科学是目前的一个研究热点。国际上有多个组,也包括清华的胡晓林老师,大家把视觉系统当成一个深度学习网络,然后训练这个深度学习网络,同时加入一些生物学的约束,然后用对比的方法看这个系统能学习到什么,进而回答生物视觉认知的问题。
唐华锦:我补充一下吴思老师讲的,在传统上AI提供了很重要的大数据分析工具,视觉神经、视觉皮层,现在的AI提供了很重要的大数据工具,尤其是在高通量的脑成像方面,建立非常精细的脑模型,AI大数据起到重要的作用。还有实时的脑活动的分析上,比如斑马鱼的活动,如何同时实时记录以及把这些神经元的活动匹配到那些神经元上,这是大量AI深度学习帮助脑科学家在分析数据、统计数据上,包括三维重建,包括树突、轴突之间连接的结构也会起到非常重要的作用,AI还是提供了很好的工具在深入的解释上面。