

这两天,AI视频生成赛道越来越热闹了。
7月24日,快手可灵全面开放内测;同一天,创企爱诗科技发布产品PixVerse V2,可生成多达40秒的高质量短视频;26日,独角兽智谱AI上线AI视频生成功能“清影”。
“清影”支持时长6s的文生视频/图生视频,清晰度为1440x960。跟其他家不同,智谱AI这次直接推出付费版本——付费5元,解锁一天24小时的高速权益,付费199元,解锁一年的付费高速权益。
当然,所有人还是可以免费使用,不用排队,也不限次数。
一年的AI视频生成付费高速权益只要199元,跟不少互联网产品的会员包年费用相差无几,AI视频生成好像真的离普通用户越来越近了。
一:一天5元,免费也行
目前,「清影」已上线清言App,面向所有用户免费开放。在智谱清言PC/APP上,点击「清影智能体」,就可以开玩了。
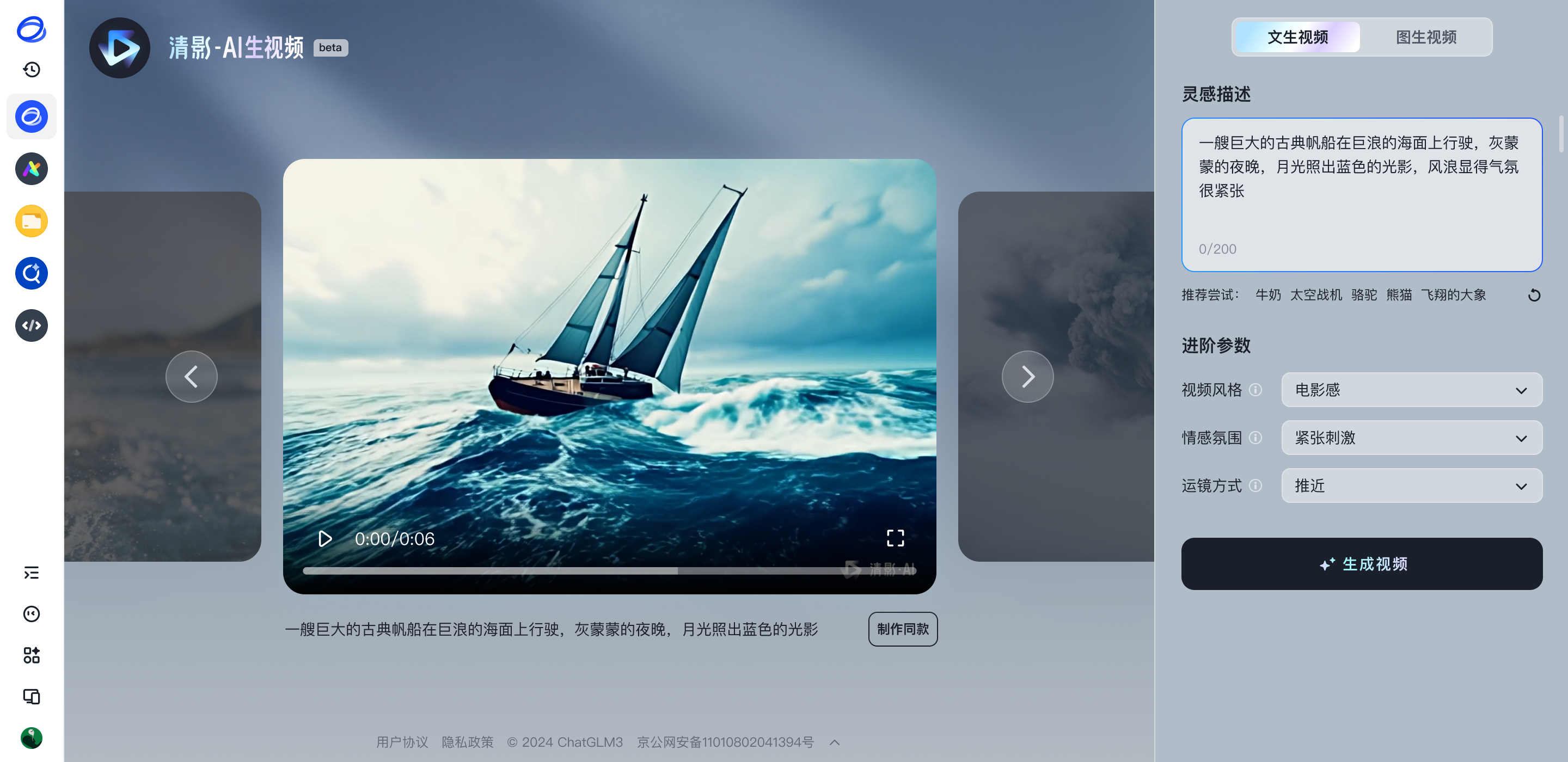
用户只需要输入一段文字,然后选择自己喜欢的风格,再配上清影自带的音乐,等待30秒左右,就可以生成一段视频。
如果想要输出的视频更符合心中所想,还可以按照结构性原则来写prompt(提示词),清影使用手册里给出了两款公式结构:
简单公式:[摄像机移动]+[建立场景]+[更多细节]
复杂公式:[镜头语言] + [光影] + [主体 (主体描述)] + [主体运动] +[场景 (场景描述)] +[情绪/氛围/风格]
笔者一步到位,按照复杂公式的要求输入了以下提示词:摄影机平移,一个红发小精灵睡在旋转木马的躺椅上,翻了个身。他浑身毛茸茸的,看起来很可爱,背景是璀璨银河,星光洒在精灵身上,随着旋转木马的转动,小精灵露出了满足的笑容。
「清影」文生视频|视频来源:极客公园
从生成效果来看,还是蛮符合设定也蛮可爱的。
文生视频之外,清影这次也开放了图生视频的能力,输入一张图片+相应的提示词,或者只输入图片,清影就可以生成视频画面。
极客公园养有许多猫猫,笔者随机抓拍了一只眼睛瞪圆溜溜的小猫,把这张图片喂给清影,再输入提示词:图中的猫咪给自己戴上墨镜,动作连贯自然且真实,画质高清。

极客公园的小猫「毛栗栗」|图片来源:极客公园
「清影」图生视频|视频来源:极客公园
智谱AI CEO 张鹏介绍,清影(Ying)底座的视频生成模型是CogVideoX,它能将文本、时间、空间三个维度融合起来,参考了Sora的算法设计,它也是一个DiT架构,通过优化,CogVideoX 相比前代(CogVideo)推理速度提升了6倍。目前生成 6s 视频,模型花费的理论时间只需要30s。
二、为什么智谱能做到
为什么包括智谱AI在内的各家都在做多模态模型?
核心是为了让机器能够更好地模拟人类的认知和感知机制,从而提升人工智能系统的整体性能和应用范围。
多模态模型能够处理多种类型的数据,如语言、图像和声音等。这与人类大脑的多模态信息处理能力非常相似,因为人类大脑能够同时接收和处理来自不同感官通道的信息,例如视觉、听觉和触觉。
并且,在多模态模型中,注意力机制被广泛使用来识别和融合不同模态的信息,这种机制在人类大脑中也存在。
因此,智谱AI在 all in 大模型路线之初,就开始多模态领域的相关布局,这也是他们实现实现全系列产品矩阵对标 Open AI 的重要一环。
从2021年开始,智谱AI先后研发了CogView(NeurIPS’21)、 CogView2(NeurIPS’22)、CogVideo(ICLR’23)、Relay Diffusion(ICLR’24)、CogView3 (2024)。
智谱AI的文生视频模型就是基于CogView而来的CogVideo,张鹏谈到了该模型的三大技术特点:首先,为了解决内容连贯性的问题,智谱AI自研了一个3D VAE结构,将原视频空间压缩至 2% 大小,大幅减少了视频扩散生成模型的训练成本和训练的难度。
其次,在可控性上,智谱 AI 自研了一个端到端的视频理解模型,用于为海量的视频数据生成详细的贴合内容的描述文本,使得生成的视频能够理解超长的、超复杂的 prompt 指令,更符合用户的输入。
最后,模型采用了将文本、时间、空间三个维度全部融合起来的 Transformer 的架构,可高效利用模型参数将文本信息和视频信息进行混合。
张鹏也谈到,目前,多模态模型的发展还处于相当初级的阶段,一是从生成视频的效果看,多模态模型对物理世界规律的理解、高分辨率、镜头动作连贯性以及时长等都有很多地方需要提升;二是从模型本身而言,现有的模型架构还不能高效地压缩视频信息,如果多模态模型继续发展,还是需要有更创新的新模型架构出现。
他判断,未来大模型的技术突破方向之一依然是原生多模态大模型,scaling law 将继续发挥作用。