博通这个季度业绩大超预期的,无疑是CEO Hock Tan给出的2027年AI收入600-900亿美金SAM(serviceable adressable market)。且专门说明了SAM这个口径更严谨,只计算现有3大客户可以拿到的收入机会。这远高于市场预期,意味着从今年到2027年,AI收入(AISC+网络)几乎每年翻倍。
其实这不是CEO第一次这么说。早在7月份的一次JPM的路演中,CEO Hock Tan称“博通未来5年的AI收入机会是1500亿美金”。当时的口径是5个客户贡献1500,意味着每个客户未来5年300亿(依然没有这次激进)。之后在9月高盛大会上(就是老黄参加那次),隔壁的Hock Tan表达了更为乐观的预期,“未来50%的AI Flops都会是ASIC,甚至CSP内部自用100%都将是ASIC”,说白了就是:所有巨头的AI算力分配都会像谷歌一样(谷歌内部自用几乎全TPU,GCP等外用几乎全英伟达GPU)
那么,年收入机会600-900亿美金什么概念?
按照Hock说的3家贡献600-900(谷歌、Meta、字节),意味着每家都将在2027年达到200-300亿美金的AI芯片采购需求(ASIC+网络)。而2024年这一口径对应的博通收入才120亿美金,其中谷歌TPU贡献80亿美金,Tomahawk 5和Jericho3交换机、PCIe Gen5/Gen6等网络贡献30亿美金。Meta只有一点点,字节几乎为0。公司明确提过的第四、第五个客户,才刚定了合作路线图,收入贡献也是0。(大概率是OpenAI、苹果。OpenAI给了博通两代ASIC项目,将在2026年启动,会采用3nm和2nm工艺,以及3D SOIC封装。而苹果项目比较迷,咨询了苹果北美参与该项目的大佬,其实内部前后道都搞定了,不确定给博通的是什么额外的die,比如switch之类。且还有第六个客户,不确定是谁,特斯拉、国内某某都有可能)
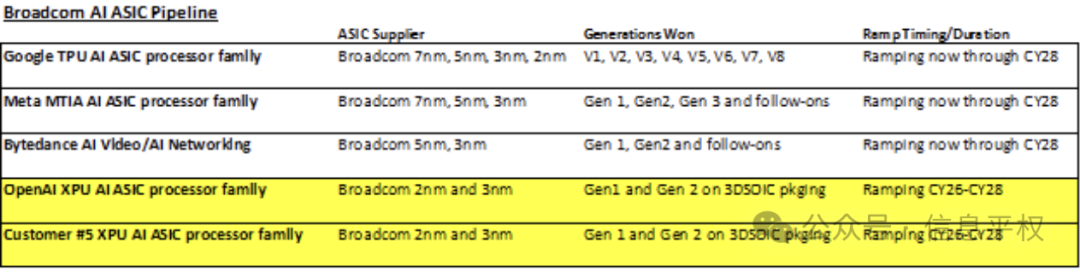
分开来看。谷歌要从目前的80亿美金收入贡献,到2027年的250亿美金TPU采购,是能想象的。尤其是昨天Gemini 2.0 Flash和Agent产品的发布,结合谷歌全球最大流量和庞大应用生态,推理起飞后的需求一定是井喷。之前大家去check到TPU cowos数字一般,很大原因是训练卡和推理卡的比例迁移,推理算力的占比在快速提升。
Meta的MTIA,按照之前的预期,会在2025年贡献博通20-30亿美金的收入,意味着在2025-2028后面三年,增长10倍。考虑到MTIA支持的就是Meta推荐引擎,而这个替换GPU也才刚刚开始,ASIC的部署和潜在的对GPU的替换,按道理也有巨大空间。这里还没有考虑GenAI算力需求,因为Meta同时在囤非常多的H卡(年底60w+)、构建10万卡集群训练Llama4、抢购GB200 Ariel。这部分训练需求后面都可以转推理。再之后是否用ASIC去支持GenAI推理,不知道是否在Hock Tan的假设之中。
最有趣的发现就是字节... 因为上述预期意味着字节的ASIC采购需求,要从0,爬到200-300亿美金。我们倒算下,单卡ASP的假设随机性很大,取决于届时的HBM含量,如果要在2026年-2027上市,PK的是rubin甚至rubin-Next,HBM搭载量奔着500GB以上的。意味着单卡BOM成本就要超过1万美金,单卡售价应该在2万美金附近。这样算下来一年出货量百万卡,与博通屡次声称的“百万卡集群”契合。显然字节也在一边买N,一边买国产,一边还在储备远期的ASIC...每个部分的采购金额看起来都非常巨大。
最后,AI网络收入,意味着会从今年的30亿美金,到2027年的150亿美金(与英伟达今年的网络收入相当)
总之,概括下这个大卫星:3家大客户,每家在2027-2028都会达到1年百万片ASIC的采购规模。且第四和第五大客户也开始快速爬升。
另一边,微软下一代项目给了Marvell,且承诺给的相当大。按照Marvell最近的管理层小会上的表态:微软的机会比想象中“显著”大,会成为公司最大的收入贡献。而微软在ASIC上的投入,可能也与最近在AI上的策略变化有关。Satya昨天在GB2上的访谈,直接讲明了在AI发展上与sam altman秉持不同观点。Sam跟微软要巨大训练资源,但Satya认为应用层才是重点模型层在“通用商品化”。可见微软的重心已经放在推理,而推理场景的多样性,会给ASIC更多机会。
看到这,几乎所有的巨头都在做ASIC,不同阶段而已。

得到什么结论呢?博通给我们描述了一副3年后的硬件蓝图。眼前显然是NV GPU的天下,3年后博通“认为”或“希望实现” ASIC与GPU至少平分天下,甚至替代。这背后代表了CSP的意志,他们从一开始就寻求英伟达之外的替代供应方案,但NV太牛逼了,比如2025年的GB200,还得抢...但一旦有契机和变化,成本可控、供应链可控的ASIC就会冒头。尤其是最近,Trainium 2其实之前就规划的,且性能指标也就平平,为什么AWS最近上调了需求,就是因为GB200缺量+模型向推理的迁徙太快,给了ASIC一点机会。因此CSP一定给了博通/Marvell非常大的远期承诺,能否做到真的是看AI发展变化、对手NV迭代速度。但这种“意志”会持续存在