

不知道有多少人还记得今年4月Reddit宣布对API接口收费的事。
省流版回顾是,因为不满意OpenAI和谷歌等公司白嫖自己平台的数据来训练他们的大模型,Reddit准备开始对调用它API的公司收费了。
最近有人发现,受此事影响,Reddit上规模不小的三个小组r/aww、r/pics和r/gifs(分别有3410万、3000万和2160万人订阅),纷纷被John Oliver的梗图“爆吧”了。
因为Reddit小组内显示的帖子都是按点赞数排序的,所以当进入这三个小组,翻下来满屏都是John Oliver那张充满喜感的脸庞……
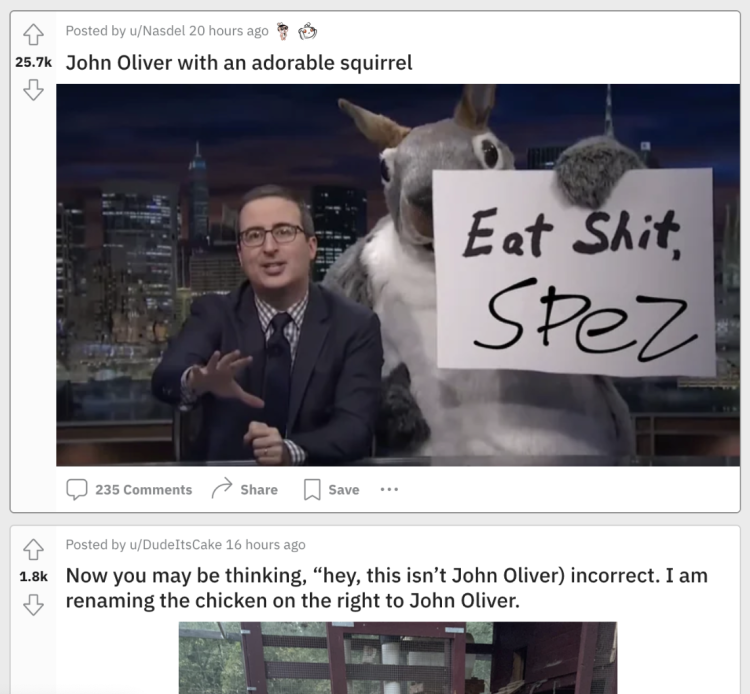
spez是Reddit CEO Steve Huffman在Reddit的用户名
r/gifs和r/aww还把各自的组名改成了“GIFs of John Oliver”和“A subreddit for cute and cuddly John Oliver pictures”。

John Oliver是知名脱口秀节目《上周今夜秀》的主持人,这档节目因对时事新闻的嘲讽而出名,网友的集体行为艺术明显是想借他的梗图表达对Reddit的不满。
比如有一个22.2万人点赞的图,画面内容是John Oliver和《芝麻街》三个主要角色的合影,配文则是:John Oliver和Reddit的CEO和高管们。

更抓马的是,这些梗图用到的素材好多都是John Oliver自己主动提供给网友的。

所以这到底是怎么一回事?
挑拨离间的Reddit?
Reddit曾在今年4月18日透过媒体宣布,将对调用其API的公司收取数据使用费,当时Reddit的CEO Steve Huffman明确表示,“Reddit 的数据语料库非常有价值,但我们没有必要把所有这些有价值的数据免费提供给一些全球数一数二的大公司。”
这个决定乍一听是针对OpenAI和谷歌等开发大模型的公司说的,但很快,一些其他领域的开发者回过味来,自己可能才是被宰得最狠的那个。
闹得最大的一次是在本月8日,iOS平台上的第三方Reddit客户端Apollo宣布将在6月30日正式关闭。

我们知道,一直以来Reddit移动端做得很差,所以催生了很多第三方App的开发。他们会用到Reddit提供的免费API接口,来帮用户更便捷地翻阅Reddit上的内容,Apollo就是最受用户欢迎的第三方Reddit客户端之一。
Apollo的开发者Christian Selig谈到关闭Apollo的原因时说,在新的API政策下,Reddit将对每5000万个API请求收取1.2万美元的费用,而按照Apollo的用户规模和使用情况,上个月就要先支付168万美元(70亿个API请求),每年可能要向Reddit支付高达2000万美元的费用。
问题是这一天价费用对Christian Selig这样的个人开发者以及定位免费的Apollo来说,根本付不起。
Christian Selig和Reddit多次沟通无果,最后做出了关站的决定。其实事情一般发展到这里大家就可以散了,Reddit对API收费也在情理之中,不过真正让用户感到愤怒的,是Reddit接下来一系列的骚操作。
Christian Selig还在和Reddit商谈时,有一天突然收到一条信息,问他怎么评价Reddit内部声称的“Apollo试图威胁Reddit索要1000万美元以平息纷争”的事。
但让Reddit没想到的是,Christian Selig在和他们的沟通中进行了录音。随后他便把这部分通话的文字记录和音频发在了网上,并评价Reddit是在“明目张胆地撒谎”。

本以为经过这次,Reddit会重新思考定价的事,可它不仅依然强硬地表示会推进新的API政策,
还继续抨击Christian Selig,“对我们说一套,对外却完全是另一套话……录音并泄露私人电话,以至于我不知道我们该如何与他做生意。”
这场糟糕的回应最终导致Reddit上7000多个小组都加入到了抗议Reddit的活动中,有的小组大部分内容都变黑了,有的转为私有,还有的则选择直接关闭。

一度甚至搜不到Reddit上最大的小组r/funny
尽管这波抗议让Reddit几乎瘫痪,Reddit CEO Steve Huffman依然发表了一些惊人的言论,比如把为Reddit小组无偿奉献的组长们称作是“地主绅士”,而很多组员则是不得不听他们的话,“就像一个城市里的抗议活动持续了太久,其他市民都想继续他们的生活……如果能评论,我敢打赌这些组员会说 ‘把它关掉,这很烦人’。”
随后便有了本文开头用户的行为艺术。
这几个小组的组长为了推翻Steve Huffman的言论,号召各自的组员进行了一次投票来决定小组的未来,选项则是:A-恢复正常,B-只允许发John Oliver的梗图。

结果选B的票数压倒性地获得了胜利。
一切因大模型而起
Reddit其实不是第一个因为大模型调用数据的问题而更改API费用规则的平台。今年2月,马斯克宣布推特的API访问将在未来设置付费墙。
根据推特客户代表在3月初公布的一份文件来看,该公司计划向开发者提供三个级别的企业包:
其中最便宜的Small Package每月需要支付4.2万美元,可以访问5000万条推文。更高的级别可以让研究人员或企业访问更多数据,分别为1亿条和2亿条推文,但每月的费用分别为12.5万美元和21万美元。
也就是说,开发者每年至少要向推特支付50万美元的费用(但50万5000万条推文的数据量对训练大模型来说远远不够)。
而到了4月19日(也是Reddit宣布将对API使用收费的后一天),因对未来无法免费访问推特数据不满,微软发布公告称将不再对推特提供面向用户的广告数据管理服务。

接着就是马斯克在第二天发推文称可能会起诉微软,指控其“非法”利用推特数据训练AI。

另外Getty Images也在今年2月起诉了Stability AI,称其侵犯了Getty Images的图片版权。
不过类似的事发展到Reddit这里,情况似乎不太一样,一是Reddit没选择起诉大模型公司,二是在Reddit的API收费标准曝光之后,大模型公司们(尤其是OpenAI)仍在保持沉默。
很多人不知道的是,如今OpenAI的CEO山姆·奥特曼(Sam Altman)曾是Reddit的早期投资人。
奥特曼早期创业开发的移动应用程序Loopt曾和Reddit是老牌知名孵化器Y Combinator投资的同一批创业公司,后来创业失败,在2012年卖掉Loopt之后,奥特曼便加入了Y Combinator做兼职合伙人。
2014年,Y Combinator创始人Paul Graham选了比自己小整整20岁的奥特曼继任Y Combinator的总裁,再后来就有了奥特曼领导的Y Combinator在2014年9月领投Reddit B轮融资的事。
他甚至还在2014年Reddit CEO Yishan Wong辞职后,担任了Reddit 8天的临时CEO。
此后的7年多时间,奥特曼一直都是Reddit的董事会成员,直到2022年1月才宣布离开。他在离开时表示,“作为用户我很爱Reddit,也很爱我在董事会度过的岁月,Steve领导的团队和董事会的其他成员都很棒,整个公司都是非常有能力的人。”

因此有人猜测,凭着7年的“交情”,Reddit对API使用收费的决定反而可能是和OpenAI商量好了的。
数据被认为是未来大模型竞争的关键要素之一,尤其随着Meta的开源大语言模型LLaMA发布,不久前针对大模型开源与否的“谷歌和OpenAI没有护城河”的说法也一度被广泛讨论——结论之一就是,用于训练大模型的数据质量要优于数据大小。
而不论是数据质量还是数据大小,Reddit都是占优势的。首先它是全球访问量排名第11的网站(美国访问量排名第6),其次它每天都在产生不断更新的、对当下最热事件的真实讨论——怎么看都是训练大模型最理想的数据库。

此前有报道称,Reddit计划在今年晚些时候IPO,意味着至今收入仍以广告为主且仍未盈利的Reddit迫切需要找到更多盈利途经,而不差钱的OpenAI明显又比个人开发者更有吸引力。
奥特曼之前也说过,OpenAI在积极和内容公司合作、获得授权,表示愿意为特定领域的高质量数据支付高价。
一个出数据,一个出钱,看起来是非常完美的组合了。还有人猜想,以后Reddit会接入大模型也说不定。
从目前Reddit强硬的态度来看,它似乎并没有太多想照顾个人开发者的意思,在用户和商业利益面前,它选择的是后者。但一个矛盾的问题是,Steve Huffman口中Reddit平台能够训练大模型产生最佳结果的、同时具备“新颖性和相关性”的数据,又是一个又一个Reddit用户创造的。
但就像Steve Huffman会说出“一个城市里抗议活动持续了太久,其他市民都想继续他们的生活”的话,他似乎非常坚信用户不会离开。