
上次,学习到从Tushare获取到的数据,经归一化处理、并降维到二维后展示等内容,为自己设定了的目标是继续学习sklearn函数包。今天就来总结一下最近的学习成果,重点讨论研究一下聚类算法。
一、 聚类算法
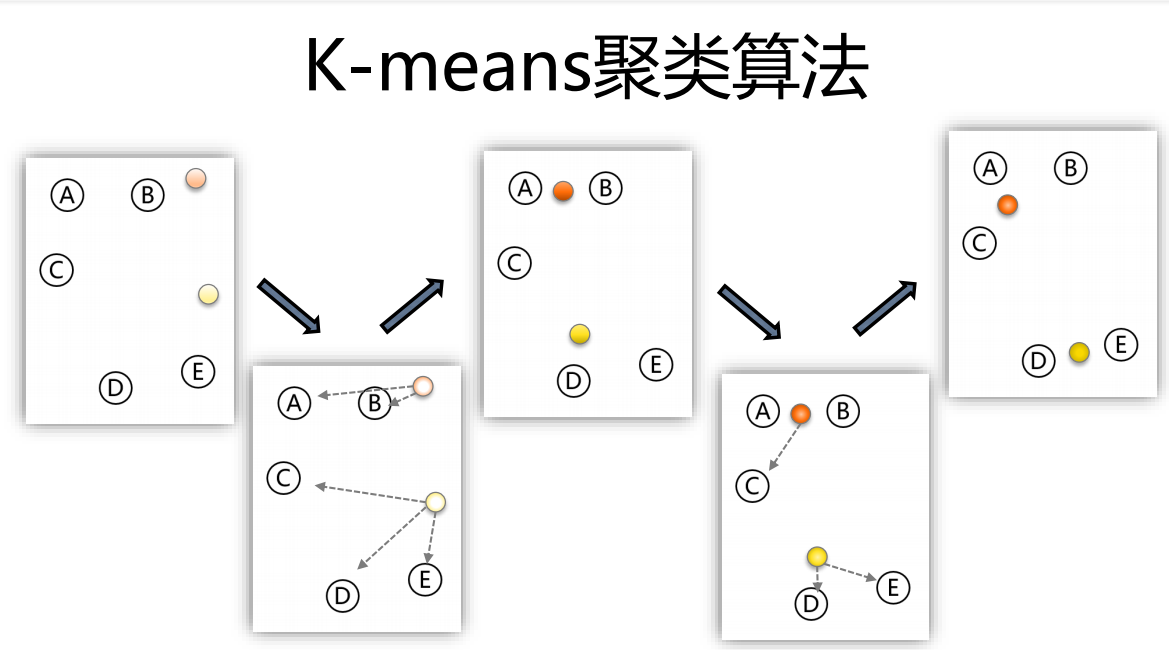
聚类算法广泛应用于非监督学习,其核心是对待处理的原始数据进行分类。聚类算法在 sklearn中有两种,一种是随机选取 k个样本作为中心点的kmeans,另一种是基于密度的DBscan。
1、kmeans算法包括四个步骤:
1)随机选择k个点作为初始的聚类中心;
2)对于剩下的点,根据其与聚类中心的距离,将其归入最近的簇
3)对每个簇,计算所有点的均值作为新的聚类中心
4)重复2、3直到聚类中心不再发生改变

在 sklearn中, kmeans有几个主要参数:
n_clusters:用于指定聚类中心的个数
init:初始聚类中心的方法,默认为k-meam++
max_iter:迭代次数,默认值为300
2、DBSCAN算法流程:
1)将所有点标记为核心点、边界点或噪声点;
2)删除噪声点;
3)为距离在Eps之内的所有核心点之间赋予一条边;
4)每组连通的核心点形成一个簇;
5)将每个边界点指派到一个与之关联的核心点的簇中(哪一个核心点的半
径范围之内)

在 sklearn中,DBSCAN有两个重要的参数
EPS:半径。
MINpts:核心点半径范围内的点数。
二、实践
1、聚类应该是在降维以后,也就是说聚类应该可以被展示出来。
2、代码中加入聚类后的运行效果。

样本聚类后的簇标签。

继续运行,进行拟合后的结果。
3、实现代码
# 聚类处理
import sklearn.cluster as skc
from sklearn import metrics
ss = np.array(newdata).reshape((-1,2))
print(ss)
db=skc.DBSCAN(eps=0.1,min_samples=20).fit(ss)
labels = db.labels_
print('Labels:')
print(labels)
raito=len(labels[labels[:] == -1]) / len(labels)
print('Noise raito:',format(raito, '.2%'))
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
print('Estimated number of clusters: %d' % n_clusters_)
print("Silhouette Coefficient: %0.3f"% metrics.silhouette_score(ss, labels))
for i in range(n_clusters_):
print('Cluster ',i,':')
print(list(ss[labels == i].flatten()))
plt.hist(ss,24)
#