

雷锋网 AI 科技评论按:如何有效处理大规模图像,对于推动人工智能研究与应用的发展而言至关重要。这也是为何 Facebook AI 选择创建并开源 PyTorch-BigGraph(PBG)的原因—— 一款更快、更轻易为大规模图像生成图嵌入的工具,特别针对那些模型对内存来说过大的多关系图嵌入(multi-relation graph embeddings)。 PBG 比起一般的嵌入软件,表现更快,同时能产出与先进模型相当的嵌入质量。有了这个新工具,任何人都能使用单个或多个并行机器迅速生成高质量的大规模图嵌入。雷锋网 AI 科技评论将开源博文编译如下。
作为例子,我们发布了首个包含 5000 万个维基百科概念的完整维基嵌入图,以供 AI 研究社区使用。该嵌入图可以协助其他研究人员执行基于维基数据概念的机器学习任务。
PBG 开源网址:https://github.com/facebookresearch/PyTorch-BigGraph
维基嵌入图:https://dl.fbaipublicfiles.com/torchbiggraph/wikidata_translation_v1.tsv
由于 PBG 是采用 PyTorch 进行编写的,因此研究人员和工程师可以轻易替换损失函数、模型以及更多其他组件,PBG 将自行计算梯度并进行扩展。
大规模图嵌入
当今的图像规模可能非常大,比如具有数十亿个节点与数万亿个边缘。这时候,常规的图嵌入方法无法很好地进行扩展以适应大规模图像操作。总的来说,大规模图嵌入存在两种挑战:首先,系统的速度必须足够快,以满足实际科研与生产的用途。以现有的方法为例,训练一个具有万亿边缘的图像可能需要耗费数周甚至数年时间。第二个挑战是内存。例如,要想嵌入具有 20 亿个节点、每个节点具有128个浮点参数的图像,需要我们具备高达 1TB 的参数,这远远超出了商用服务器的内存容量。
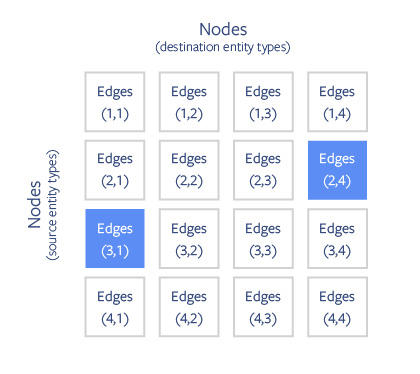
而 PBG 通过对图像进行块分区(block partitioning),能够有效克服图嵌入的内存问题。这些节点被随机划分为 P 个大小合适的分区,以适应内存容量,然后再根据源节点与目标节点将边缘划分为 P2buckets。
针对大规模图像的 PBG 分区方案。节点被划分为 P 个大小合适的分区。然后根据源节点与目标节点将边缘划分为 buckets。在分布模式下,多个 buckets 的非重叠分区将能被并行执行(如蓝色方块所示)。
把节点与边缘进行分区后,我们每次可以在一个 bucket 中进行训练。 在对 bucket(i,j)的训练过程中,只有分区 i 和 j 的嵌入会被存储到内存中。
PBG 提供两种方法以供进行分区图嵌入训练。在单个机器训练中,嵌入与边缘一旦不被使用,就会被替换出磁盘;在分布式训练中,嵌入将分布在多台机器的内存里。
分布式训练
PBG 通过 PyTorch parallelization primitives 来实现分布式训练。 由于单模型分区每次只能被一台机器使用,因此一次最多可以在 P / 2 台机器上进行图嵌入训练。 只有机器需要切换至新的 bucket 时,才会传送模型数据。 为了保证分布式训练效果, PBG 通过经典参数服务器模型来表示不同类型边缘的共享参数。
PBG 分布式培训的体系结构图。 机器通过 lock server 来协调训练不相交的 buckets。 分区模型的参数通过分片分区服务器进行交换,并共享通过分片参数服务器异步更新的参数。
PyTorch-BigGraph 评估结果
为了准确评估 PBG 的性能,我们采用包含超过 1.2 亿个节点与 27 亿个边缘的开源 Freebase 知识图。此外还采用较小的 Freebase 知识图子集——FB15k,它包含了 15,000个节点和600,000个边缘,一般被用作多关系嵌入方法的基准。
PBG 基于 Freebase 知识图所训练的嵌入 t-SNE 图。如国家、数字和科学期刊之类的实体具有类似的嵌入情况。
论文中,我们成功证明 PBG 与 FB15k 数据集最先进的嵌入方法效果相当。
各种嵌入方法在 FB15k 数据集链路预测任务上的性能表现。 PBG 在 TransE 与 ComplEx 嵌入模型的基础上达到了同等性能。我们测量了链路预测的平均倒数等级(MRR)和 Hit@10 statistics。 Lacroix 通过非常大的嵌入维度成功实现更高的MRR,这个我们也能通过 PBG 进行复制,但不在这份报告中呈现。
接着,我们使用 PBG 训练完整的 Freebase 图嵌入。该大小的数据集能够适应现代服务器,但 PBG 的分区与分布式执行可以有效减少内存使用与训练时间。我们发布了针对维基数据的首个嵌入图,这是同类数据的最新知识嵌入图。
PBG分区方案可在不降低模型质量情况下,将内存使用量有效减少 88%。使用多台并行机器可以减少更多训练时间。
我们还在论文中评估了 PBG 在几个公开社交图数据集上的嵌入结果。我们发现, PBG 优于同类方法,主要是分区与分布式执行有效减少了内存使用与培训时间。对知识图而言,分区或分布式执行能使训练模型对于超参数与建模的选择变得更加敏感。不过我们也发现,对社交图而言,嵌入质量对于分区与并行的选择似乎并不那么敏感。
嵌入、分布式训练的好处
PBG 将允许我们在无需耗费专门计算资源(如GPU或大量内存)的情况下,对大规模图嵌入(包括知识图表、股票交易图表、在线内容、生物数据等)进行训练。我们希望 PBG 可以对那些拥有大规模图形数据集,但缺乏相应 ML 处理工具的小型公司或组织能有所帮助。
虽然我们选择在 Freebase 这样的数据集上演示 PBG,但 PBG 的最终目是想处理哪些10至100倍大的图像。我们鼓励从业者们在更大的数据集上进行实验。近期无论是计算机视觉(通过深度学习标签来改进图像识别质量)还是自然语言处理(word2vec、Bert、Elmo)领域所取得的突破,都是基于大规模数据集的任务无关预训练(task-agnostic pretraining)的成果。我们希望基于大规模图形的无监督学习,最终可以产生更好的图形结构数据推理算法。
via https://ai.facebook.com/blog/open-sourcing-pytorch-biggraph-for-faster-embeddings-of-extremely-large-graphs/
雷锋网 AI 科技评论




