

本文第一作者为陈宇辉,中科院自动化所直博三年级;通讯作者为李浩然,中科院自动化所副研;研究方向为强化学习、机器人学习、具身智能。
视觉-语言-动作模型在真实世界的机器人操作任务中显示出巨大的潜力,但是其性能依赖于大量的高质量人类演示数据。
由于人类演示十分稀缺且展现出行为的不一致性,通过监督学习的方式对 VLA 模型在下游任务上进行微调难以实现较高的性能,尤其是面向要求精细控制的任务。
为此,中科院自动化所深度强化学习团队提出了一种面向 VLA 模型后训练的强化微调方法 ConRFT(Consistency-based Reinforced Fine-tuning)。其由离线和在线微调两阶段组成,并具有统一的基于一致性策略的训练目标。这项工作凸显了使用强化学习进行后训练以增强视觉-语言-动作模型在真实世界机器人应用中的潜力。
目前,该论文已被机器人领域顶级会议 Robotics: Science and Systems XXI(RSS 2025)接收。

研究背景
视觉-语言-动作模型(Vision-Language-Action, VLA)在训练通用机器人策略方面取得的最新进展表明机器人数据集上进行大规模预训练后 [1,2],其拥有在理解和执行各种操作任务方面的卓越能力。
虽然预训练的通用策略能够捕捉泛化性的表征,但其仍然难以在真实机器人和任务上做到零样本泛化 [3],因此使用任务专用的数据进行后训练微调对于优化模型在下游任务中的性能来说非常重要。
目前广泛使用的方法是使用人类遥操作收集的数据对 VLA 模型进行监督微调(Supervised Fine-tuning, SFT)。然而,模型的性能严重依赖于数据集的质量和数量。由于人类收集数据的次优性和策略不一致性等固有问题,这些数据很难提供最优轨迹 [4],导致微调后的模型效果不佳。
与此同时,大语言模型(Large Language Model, LLM)和视觉-语言模型(Vision-Language Model, VLM)的最新进展凸显了强化学习在对齐模型策略与人类偏好之间差距 [5] 或改进模型推理 [6] 方面的价值,证明了部署使用任务专用的奖励函数的强化学习(Reinforcement Learning, RL)来从在线交互中机性能策略更新具有巨大的潜力。
然而,与 LLM/VLM 不同,VLA 模型需要机器人与真实世界进行物理交互,因而将 RL 扩展到 VLA 模型面临着巨大的挑战。尤其是在要求精细控制的操作任务上,交互安全性和成本限制要求 RL 算法具有探索的安全保障和很高的样本效率。
ConRFT:基于强化学习的 VLA 模型微调方法
为了充分利用 RL 技术的优势,利用在线交互数据高效微调 VLA 模型,我们提出了一种强化微调(Reinforced Fine-tuning, RFT)方法,包含离线和在线两个阶段,并采用统一的训练目标。
基于我们之前的工作 CPQL [7],本文方法将 SFT 与 Q-learning 相结合,并利用一致性策略微调 VLA 模型。离线微调过程中利用人类收集的专家数据,在模型与真实环境交互之前提取有效的策略和稳定的价值函数。
随后的在线微调阶段通过人在回路(Human-in-the-Loop Learning, HIL)进行干预,并使用奖励驱动的策略学习,从而解决了在真实环境下进行 RL 的安全要求和样本效率两个挑战。该方法示意图如下:
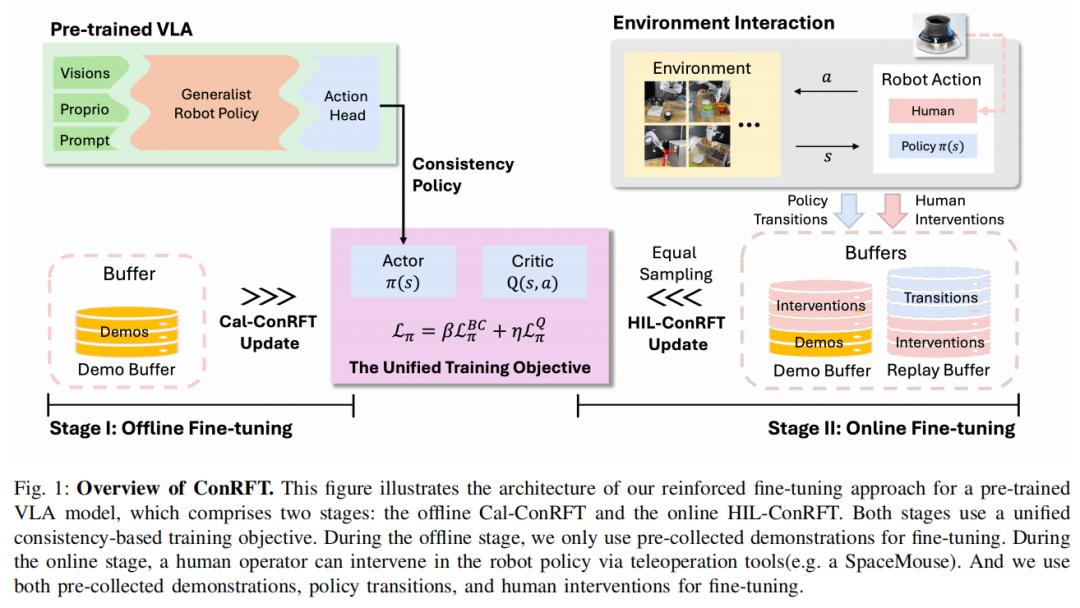
本文方法采用一致性策略(Consistency Policy)作为动作单元(Action Head),对 VLA 模型进行微调,解决了两个关键问题:
1)它有助于利用预收集的数据中经常出现的策略不一致和次优演示问题;
2)与基于扩散模型(Diffusion Model)的动作单元相比,其在计算上保持轻量,可以实现高效推理。
一致性策略是一种基于概率流常微分方程(Probability Flow Ordinary Differential Equation)的策略,它学习从高斯分布中采样的随机动作映射到基于当前状态的专家动作分布,从而生成目标动作用于决策任务。
阶段I:离线微调(Cal-ConRFT)
由于预训练的 VLA 模型通常缺乏对未见过场景的零样本泛化能力,因此离线阶段专注于使用预先收集的小型离线数据集(大约 20-30 次演示)训练策略,然后再过渡到在线微调阶段,从而减少整体在线训练时间和探索过程带来的安全风险。
为了能够有效利用离线数据,离线阶段选择(Cal-QL)[8] 作为价值函数更新方法,以提高 Q 函数对分布外(Out of Distribution, OOD)动作的鲁棒性。使用 Cal-QL 进行价值函数更新的训练目标如下:
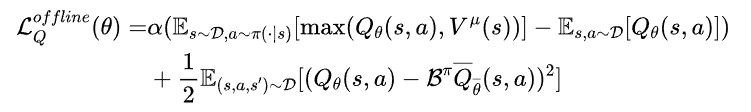
尽管通常情况下,Cal-QL 能够高效地利用离线数据集,但在只有少量演示(例如 20-30 个)可用时,其依然很难训练出有效的策略。因为有限的状态-动作覆盖会导致 Q 值估计不准,从而使策略难以推广到未见过的状态。相比传统的离线强化学习方法,其数据集通常由多种行为策略收集而成,可以提供广泛的状态-动作覆盖范围以减少分布偏移。
为了解决这个问题,离线阶段加入了 BC(Behavior Cloning)损失。BC 损失直接最小化策略生成的动作与演示中的动作之间的差异,通过鼓励模型模仿演示中的行为,在离线阶段提供额外的监督信号。这有助于 VLA 模型学习更有效的策略,并初始化稳定的 Q 函数。
具体而言,使用一致性策略动作单元的 VLA 模型更新训练目标如下:
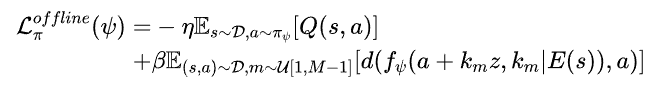
阶段II:在线微调(HIL-ConRFT)
虽然离线阶段可以从少量演示数据中提供初始策略,但其性能受限于预先收集的演示数据的范围和质量。因此,本文方法引入在线阶段,即 VLA 模型通过与真实环境交互并进行在线微调。
在阶段 II 的强化微调过程中,离线阶段的演示缓冲区
依然保持用于存储演示数据,同时还有一个重放缓冲区
来存储在线数据,并使用平均采样来形成单个批次(Batch)用于模型训练。
由于 VLA 模型会根据其当前策略不断收集新的数据,数据分布会自然地随着策略而演变,这种持续的交互减少了离线阶段面临的分布偏移问题。因此,在线微调阶段直接使用标准 Q 损失进行价值函数更新:
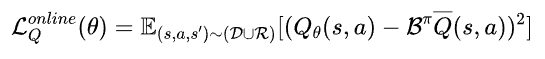
对于 VLA 模型,在线微调阶段使用与离线阶段结构统一的训练目标,因此 VLA 模型可以快速适应并实现策略性能提升:
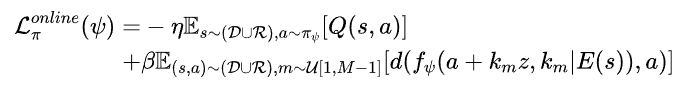
可以注意到,在线阶段仍然保留了 BC 损失。主要有两个原因:
1)它确保策略与演示数据一致,防止出现可能导致性能崩溃的剧烈偏差;
2)由于强化学习本质上涉及探索,因此它在高维状态-动作空间中可能变得不稳定,而 BC 损失可以防止策略与离线基线方法偏差过大,从而降低低效或不安全行为的风险。这在真实机器人的训练中和要求精细控制的操作任务中非常重要,尤其是在不安全动作可能导致物体损坏或其他危险的物理环境中。
此外,在线阶段通过人在回路学习将人工干预融入学习过程。具体而言,其允许人类操作员及时干预并从 VLA 模型接管机器人的控制权,从而在探索过程中提供纠正措施。
当机器人出现破坏性行为(例如碰撞障碍物、施加过大的力量或破坏环境)时,人工干预至关重要。这些人工纠正措施会被添加到演示缓冲区
中,以提供高层次的指导,引导策略探索朝着更安全、高效的方向演变。
除了确保安全的探索之外,人工干预还可以加速策略收敛。因为当策略导致机器人陷入不可恢复状态或不良状态(如机械臂将被操作物体扔出桌面或与桌面撞击),或者机器人陷入局部最优解(如果没有外部帮助,则需要花费大量时间和步骤才能克服)时,人类操作员可以介入纠正机器人的行为,并引导其朝着更安全、有效的方向演变。
实验结果与分析
为了评估本文方法在真实环境中强化微调 VLA 模型的有效性,我们在八个不同的操作任务上进行了实验,并选择 Franka Emika 机械臂作为实验平台,如下图所示。

这些任务旨在反映各种操作任务挑战,包括物体放置任务(例如将面包放入烤面包机)、要求精确控制的任务(例如将轮子对准并插入椅子底座)以及柔性物体处理的任务(例如悬挂中国结)。
在八个真实环境任务上的实验测试证明了 ConRFT 性能超越最先进(SOTA)方法的能力。VLA 模型在本文提出的框架下经过 45-90 分钟的在线微调后,平均任务成功率达到 96.3%,展现了极高的策略性能和样本效率。
此外,它的性能优于基于人类收集数据或强化学习策略数据训练的 SFT 方法,平均成功率提高了 144%,且平均轨迹长度缩短了 1.9 倍,这些结果凸显了使用奖励驱动的强化微调方法在提升 VLA 模型在下游任务上性能的巨大潜力。
策略测试
通过奖励驱动的强化微调,VLA 模型表现出对外部人为干扰的极强鲁棒性,确保更可靠地完成任务。包含外部人为干扰的策略效果可以参考 Pick Banana 和 Hang Chinese Knot 任务。
Pick Banana(含外部人为干扰)