

机器之心报道
编辑:陈陈、杜伟
5 月 3 日至 5 日,第 28 届国际人工智能与统计学会议(AISTATS)在泰国举办。

作为人工智能、机器学习与统计学交叉领域的重要国际会议,自 1985 年创办以来,AISTATS 致力于促进计算机科学、人工智能、机器学习和统计学等领域研究者之间的交流与合作。
昨日,会议主办方公布了本年度时间检验奖,授予 UCSD 与微软研究院合著的论文《Deeply-Supervised Nets》(深度监督网络),共同一作分别为 Chen-Yu Lee(现为谷歌研究科学家)和 AI 圈所熟知的谢赛宁(现为纽约大学助理教授)。该论文被当年的 AISTATS 接收。
根据 Google Scholar 数据显示,该论文被引数已经超过了 3000,足可见其含金量。

在得知自己 10 年前的论文获得 AISTATS 2025 时间检验奖之后,谢赛宁分享了更多背后的故事。
他表示,《Deeply-Supervised Nets》是读博期间提交的第一篇论文,并且有趣的是,这篇论文最初被 NeurIPS 拒稿了(分数为 8/8/7)。那种痛苦一直萦绕在他心头,也许现在终于可以放下了。他还说到,不会将投顶会比作「抽奖」,但坚持不懈确实能带来很大的帮助。
最后,谢赛宁寄语同学们:如果你们在最近的论文评审结果出来之后感到沮丧,并正在为下一篇论文做准备,则可以将他的经历当作一点小小的提醒,继续前进(就会有收获)。

同样地,另外一位共同一作 Chen-Yu Lee 也发文对 10 年前的论文获得 AISTATS 2025 时间检验奖感到自豪,并表示这项研究成果至今仍具有重要意义和影响力。

评论区的网友纷纷发来对谢赛宁论文获奖的祝贺。
接下来,我们看看这篇来自 10 年前的论文主要讲了什么内容。
论文讲了什么?

论文标题: Deeply-Supervised Nets
论文地址:https://arxiv.org/pdf/1409.5185
论文摘要:近年来,神经网络(尤其是深度学习)的复兴备受关注。深度学习可采用无监督、有监督或混合形式,在图像分类和语音识别等任务中,当训练数据量充足时,其性能提升尤为显著。
一方面,分层递归网络已展现出自动学习数千乃至数百万特征的巨大潜力;另一方面,深度学习仍存在诸多悬而未决的基础性问题,也引发了学界对其局限性的担忧。
论文中表示,在当时深度学习框架存在的问题包括:隐藏层学习到的特征的透明度和辨别力降低;梯度爆炸和消失导致训练困难;尽管在理论方面做了一些尝试,但对算法行为缺乏透彻的数学理解等。
尽管如此,深度学习能够在集成框架中自动学习和融合丰富的层次特征。这得益于研究人员开发出了各种用于微调特征尺度、步长和收敛速度的方法,还提出了多种技术从不同角度提升深度学习的性能,例如 dropout 、dropconnect 、预训练和数据增强等。
此外,梯度消失的存在也使得深度学习训练缓慢且低效 。
本文提出了深度监督网络 (deeply-supervised nets,DSN) 来解决深度学习中的特征学习问题,该算法对隐藏层和输出层都强制进行直接和早期监督。并且还为各个隐藏层引入了伴随目标(companion objective),将其用作学习过程的附加约束(或新的正则化)。从而显著提高了现有监督深度学习方法的性能。
此外,该研究还尝试使用随机梯度技术为本文方法提供依据。证明了所提方法的收敛速度优于标准方法,得出这一结论的前提是假设优化函数具有局部强凸性(这是一个非常宽松的假设,但指向一个有希望的方向)。
这篇论文还提到,文献 [1] 采用分层监督预训练策略,而本文提出的方法无需预训练。文献 [26] 将标签信息用于无监督学习,文献 [30] 则探索了深度学习的半监督范式。文献 [28] 使用 SVM 分类器替代 CNN 传统的 softmax 输出层。本文提出的 DSN 框架创新性地支持 SVM、softmax 等多种分类器选择,其独特价值在于实现对每个中间层的直接监督控制。
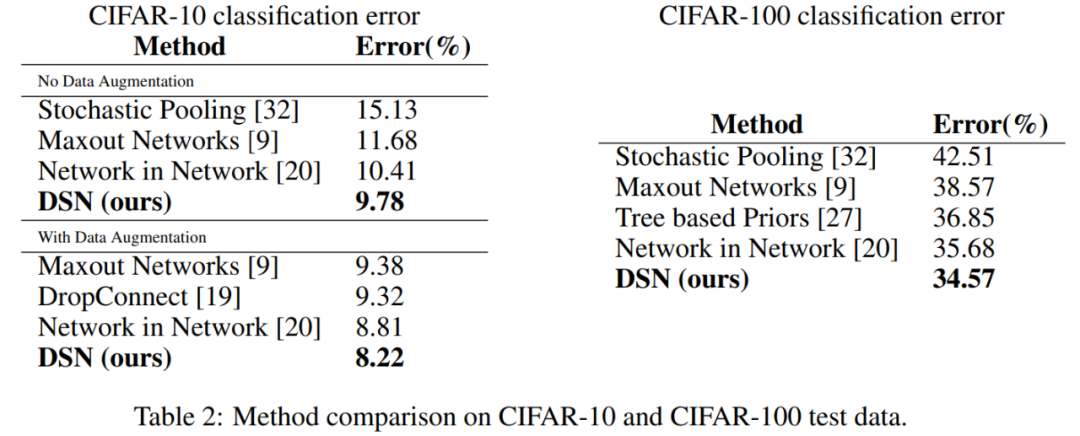
实验结果表明:无论在 DSN-SVM 与 CNN-SVM 之间,还是 DSN-Softmax 与 CNN-Softmax 之间,本文方法均取得一致性性能提升,并在 MNIST、CIFAR-10、CIFAR-100 及 SVHN 数据集上刷新当前最优纪录。
图 2 (a) 和 (b) 展示了四种方法的结果,DSN-Softmax 和 DSN-SVM 优于它们的竞争 CNN 算法。图 2 (b) 显示了针对不同大小的训练样本进行训练时不同方法的分类误差(在 500 个样本时,DSN-SVM 比 CNN-Softmax 提高了 26%)。图 2 (c) 显示了 CNN 和 DSN 之间的泛化误差比较。
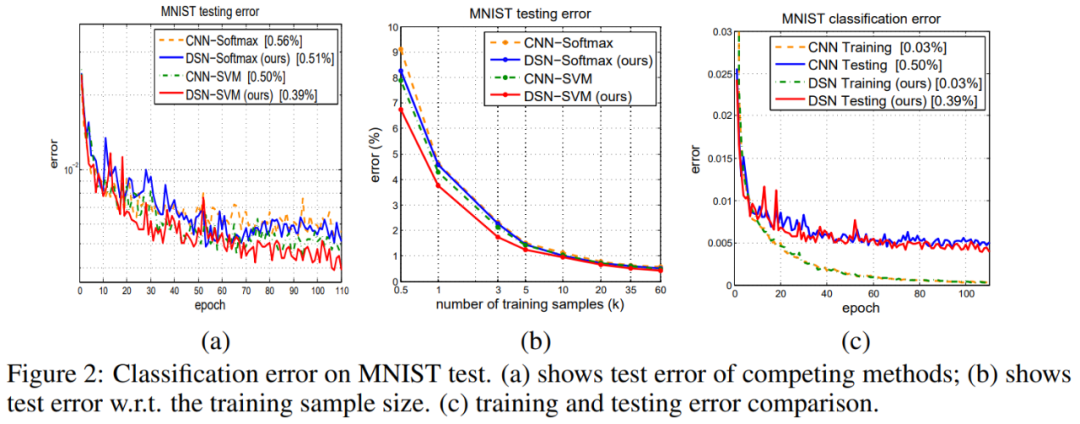
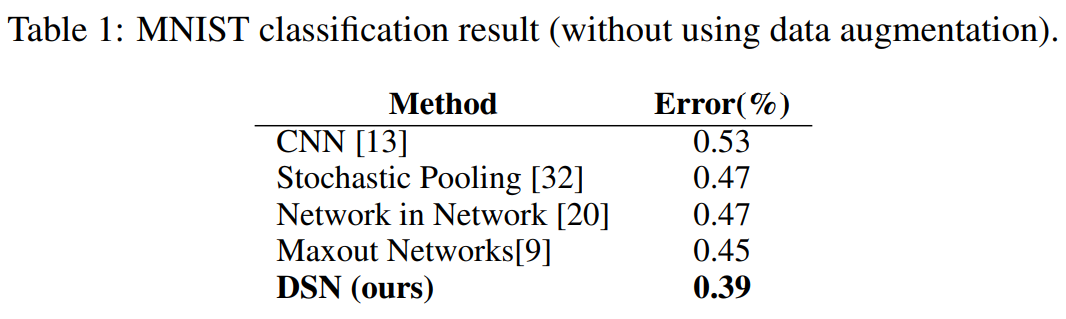
表 2 显示,在 CIFAR-10 和 CIFAR-100 上的性能提升,再次证明了 DSN 方法的优势。
为了比较 DSN 与 CNN 分别学习到什么特征,本文从 CIFAR-10 数据集的十个类别中各选取一个示例图像,运行一次前向传播,并在图 (3) 中展示从第一个(底部)卷积层学习到的特征图。每个特征图仅显示前 30% 的激活值。DSN 学习到的特征图比 CNN 学习到的特征图更直观。

需要特别说明的是,本框架可兼容近期提出的多种先进技术,如模型平均、dropconnect 和 Maxout 等。论文表示通过对 DSN 的精细化工程优化,可进一步降低分类误差。
© THE END