

编辑:Panda
ARC Prize,曾在去年底 OpenAI 12 天连发的最后一天赚尽了眼球,其发布已经 5 年的基准 ARC-AGI 首次迎来了得分达到优良等级的挑战者:o3 系列模型。参阅机器之心报道《刚刚,OpenAI 放出最后大惊喜 o3,高计算模式每任务花费数千美元》。
自那以后已经过去了两个多月,AI 领域早已经迎来了巨大的改变,其中尤其值得提及的便是 DeepSeek-R1 模型。凭借开源和低成本等优势,这款性能强大的推理模型不仅已经成为国内 AI 或云服务商的标配,还正被集成到越来越多的应用和服务中,甚至原来很多原本与 AI 没有直接关联的应用也以接入 DeepSeek 为卖点进行宣传。
那么,DeepSeek-R1 的 ARC-AGI 成绩如何呢?根据 ARC Prize 发布的报告,R1 在 ARC-AGI-1 上的表现还赶不上 OpenAI 的 o1 系列模型,更别说 o3 系列了。但 DeepSeek-R1 也有自己的特有优势:成本低。
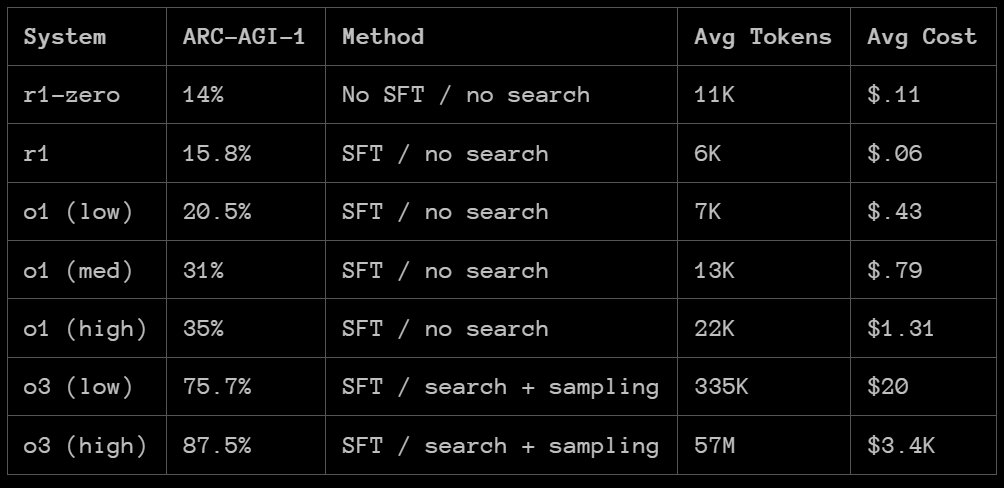
来源:https://arcprize.org/blog/r1-zero-r1-results-analysis
上周六,ARC Prize 又发布了一个新的基准,这一次 DeepSeek-R1 不仅超过了 o1-mini,与 o3-mini 的差距也非常小。

这个新基准名为 SnakeBench,是一个 1v1 的对抗性基准。其思路很简单:将两个 LLM 放在一起进行贪吃蛇比赛。如下展示了一局 o3-mini 与 DeepSeek-R1 的对抗。

官方网站:https://snakebench.com
项目地址:https://github.com/gkamradt/SnakeBench
SnakeBench:缘起
ARC Prize 的推文表示,SnakeBench 的设计灵感来自著名 AI 研究科学家 Andrej Karpathy 的一条推文,其中涉及到了让 AI 智能体在游戏中进行对抗以进行评估的思路。(这条推文还涉及到另一个使用游戏来评估 LLM 的基准 TextArena,感兴趣的读者可访问:https://www.textarena.ai )

ARC Prize 表示,使用游戏作为评估环境可以检验 LLM 的多种能力,包括:
实时决策
多重目标
空间推理
动态环境
模型的表现
ARC Prize 报告说他们目前已经使用 50 个 LLM 进行了总共 2800 场比赛,为这些模型的「贪吃蛇实时策略和空间推理」能力排了个座次。

具体过程是怎样的呢?
首先,以文本格式提供两个 LLM 角逐的棋盘,其中会通过提示词明确说明所用的 XY 坐标系。因此需要明确,这里提供的并非真正的 2D 表示 —— 这种信息转译可能会丢失某些空间推理信息。下面展示了一个提示词示例:

在游戏进行时,首先随机初始化每条蛇。然后要求两条蛇(LLM)同时选择下一步动作。当一条蛇撞到墙、撞到自己或撞到另一条蛇时,游戏结束。之后,根据游戏结果计算每条蛇的 Elo 评分。
以下为完整榜单:

据介绍,整体来说,Big Llama、o1、o3、Sonnet 3.5 和 DeepSeek 的表现最好,而其它 LLM 总是会撞墙。下面展示了几局效果最好的比赛:

ARC Prize 官网还详细列出了这四局比赛的完整详情,下面展示了其中第二局(DeepSeek-R1 vs o3-mini)的详情。在这里,不仅可以看到 LLM 每一步的选择,而且还能看到 LLM 为每一步选择给出的理由。当然,对于 DeepSeek-R1 模型,我们还可以清楚地看到其完整的思考过程。

Dry Merge CTO Sam Brashears 还注意到了一个非常有趣的回合。此时,o3-mini 和 DeepSeek 同时与一个苹果相邻,而它们竟然同时认为对方不会冒险吃这个苹果,于是决定自己去吃,结果导致双双毙命。

此时,DeepSeek 想的是:「如果我向右移动到 (8,7) ,同时如果蛇 1 也向左移动,则有与蛇 1 相撞的风险。但是,为了保证分数,吃到苹果优先于规避风险。」
而此时 o3-mini 也有类似的想法:「尽管我们的敌蛇(蛇 2)的头位于 (7,7) 处,也有可能想吃这个苹果,但没有强烈的迹象表明它会冒险用自己更长的身体与我正面碰撞。因此,吃到苹果的直接好处大于风险。」

以下是 ARC Prize 总裁 Greg Kamradt 总结的几点关键发现:

推理模型占据主导:o3-mini 和 DeepSeek 赢得了 78% 的比赛。
LLM 经常误解以文本格式提供的棋盘布局。这会导致模型错误地定位蛇头的位置,或者导致蛇撞到自己的尾巴。
较低档的模型(包括 GPT-3.5 Turbo 和 Haiku)表现不佳,而只有 GPT-4、Gemini 2.0 和 o3-mini 表现出足够的策略游戏推理能力。这说明基本的空间推理仍然是 LLM 面临的巨大挑战。大多数模型都无法跟踪自己的位置,并且会犯明显的错误。
上下文很关键。为了让 LLM 做出正确选择,需要让其加载大量信息,包括棋盘位置、苹果位置、其它蛇的位置等。
有趣的是,这种 LLM 对抗竞技显然很容易复现,CoreView 联合创始人兼 CTO Ivan Fioravanti 便基于 Ollama 让 deepseek-r1:32b 与 qwen2.5-coder:32b 进行了贪吃蛇比赛。

另外也有用户分享了自己让具有视觉能力的 LLM 玩贪吃蛇的经历,不过不同于 SnakeBench 的结果,反倒是 Gemini 表现最好。

参考链接
https://x.com/arcprize/status/1890464921604719103
https://x.com/GregKamradt/status/1890466144533749866