

编译 | 程茜
编辑 | 心缘
智东西2月20日报道,今日凌晨,微软第一个世界和人类行动模型(WHAM)Muse登上国际顶级学术期刊Nature。
Muse是视频游戏生成模型,其参数量最高达到16亿,是基于接近7年的人类游戏数据进行训练,其可以理解游戏中的物理和3D环境,然后生成对应玩家的动作以及视觉效果。
不过,因为研究工作仍处于早期,目前其仅限于以300×180像素的分辨率生成游戏视觉效果。
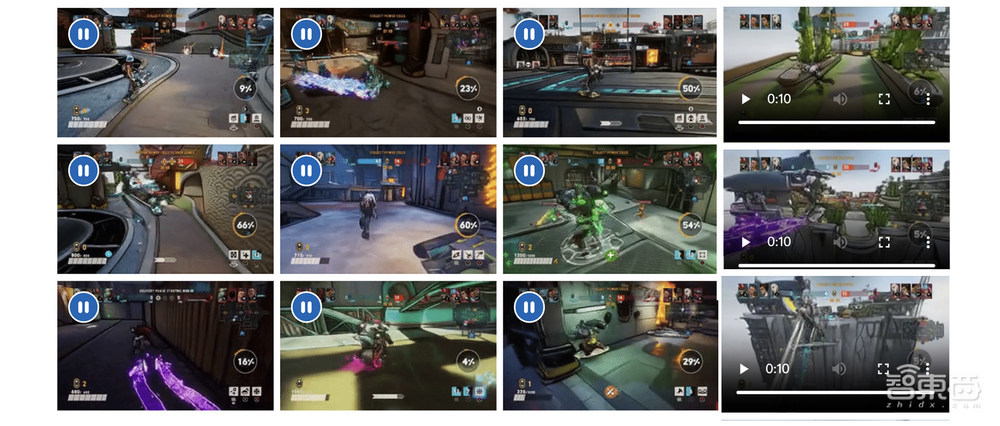
论文中显示,其生成的游戏视频效果能同时保持一致性、多样性和持久性。具体来说,其生成的两分钟视频效果人类真实游戏效果相近;会提供不同摄像机移动角度、不同角色、游戏工具的多样性效果;还支持开发者添加新元素,并自动合理融入画面。

这一模型由微软研究员游戏智能团队、可教的AI体验(Tai X,Teachable AI Experiences)团队与微软旗下游戏工作室Xbox Games Studios的电子游戏制作公司Ninja Theory合作开发。
微软正在开源权重和样本数据,并提供了一个可视化的交互界面WHAM Demonstrator供开发者体验,开发者可以在开发人员可以在Azure AI Foundry上学习试验权重、示例数据和 WHAM Demonstrator。
Xbox正在考虑基于Muse为用户构建简短的交互式AI游戏体验,将很快在Copilot Labs上试用。

一、基于7年人类游戏数据训练,模型参数16亿
Muse上下文长度为1秒,在7 Maps数据集上训练,每张图像都以数据集的原始分辨率300×180编码为540个Tokens。7 Maps数据集的数据量相当于7年多的人类游戏时间。研究人员从Xbox游戏Bleeding Edge的7张游戏地图中提取了大约50万个匿名游戏会话的数据,磁盘上总计27.89TiB。
此外,还有1500万到8.94亿参数的模型,上下文长度为1秒,在7 Maps过滤后的Skygarden数据集上训练,每张图像将以128×128编码成256个Tokens。该数据集指的是仅在Skygarden地图上进行1年匿名游戏的数据。
微软官方发布的示例都是通过提示模型使用10个初始帧(1秒)的人类游戏和整个游戏序列的控制器动作来生成的。
例如,用户可以将视觉对象作为初始提示加载到模型,下方视频添加了Bleeding Edge中的图像,然后使用Muse从此起点生成多个可能的延续图像。

此外,用户还可以浏览生成的序列并进行调整,例如使用游戏控制器来指导角色。这些功能演示了Muse的功能如何将迭代作为创作过程的一部分。

Muse在生成游戏视频时可以保持一致性、多样性和持久性。
在一致性方面,下方视频都是基于基于 Muse生成,两段视频演示了该模型生成长达两分钟的一致游戏序列的能力。

多样性方面,以相同的初始10帧(1 秒)真实游戏为条件,下面视频中,上方的三个视频显示了行为多样性(不同的摄像机移动、在生成位置附近徘徊以及导航到中间跳板的各种路径),下方的三个视频显示了视觉多样性(角色的不同悬浮板)。

在持续性方面,模型还可以在修改游戏序列时提示它并保留新引入的元素。例如,在下面的演示中,可以看到新角色被添加到游戏的原始视觉对象中,视频中这一新角色会保留,还会在后续视频中继续存在。

此外,论文中还提到Muse训练的数据是通过与Ninja Theory的合作提供的,数据收集由最终用户许可协议涵盖,研究人员对数据的使用受与游戏工作室的数据共享协议的约束,并由机构审查委员会批准。这些数据是在2020年9月至2022年10月期间记录的。为了最大限度地降低人类数据的风险,他们已从数据中删除了任何个人身份信息(Xbox用户ID),并对结果数据进行清理,以删除非活跃玩家的数据。
二、多学科协作评估,确定三大模型能力
在早期,研究人员首先总结了27名从事游戏开发的创意人员的用户研究结果,以评估发散思维和迭代实践在使用生成式AI实现新颖性设计的重要作用。基于这些见解,他们确定了一组可能对实现创造性构思很重要的生成模型能力,即一致性、多样性和持久性。
其中,一致性可以使得生成的序列随时间推移并与游戏机制保持一致,多样性允许模型产生大量不同的序列,反映不同的潜在结果,以支持发散性思维,持久性使得用户对游戏视觉效果和控制器动作进行修改,并将它们同化到生成的游戏序列中。

Muse基于人类游戏数据进行训练,以预测游戏视觉效果(“帧”)和玩家的控制器动作(“模型架构和数据”部分)。生成的模型准确捕获了游戏环境的3D结构(“模型评估”部分)、控制器动作的效果和游戏的时间结构,使得其生成的视频可以连贯、一致且具有多样性。
一致性需要一个顺序模型,该模型可以准确捕获游戏视觉效果和控制器动作之间的依赖关系;多样性需要模型可以生成数据,保留数据集中视觉对象和控制器动作的顺序条件分布。最后,持久性是通过预测模型提供的,该模型可以以 (修改的) 图像和控制器动作作为条件。其研究方法的关键是将数据构建为一系列离散的Tokens。为了将图像编码为Tokens序列,研究人员使用VQGAN图像编码器。其中,用于对每张图像进行编码的Tokens数量是一个关键的超参数,它在预测图像的质量与生成速度和上下文长度之间进行权衡。
对于Xbox控制器动作,尽管按钮本身是离散的,但研究人员将左右摇杆的x和y坐标离散为11个Buckets,然后训练一个仅解码器的转换器来预测交错图像和控制器动作序列中的下一个Tokens。生成的模型可以通过对下一个Tokens进行自回归采样来生成新的序列。生成过程中,研究人员还可以修改Tokens,以允许修改图像或者控制器动作。
博客中还提到,研究人员最初使用的是V100集群进行训练,他们实现了扩展到在多达100个GPU上进行训练,这最终为H100的大规模训练铺平了道路。
此外,借助最初的评估框架和对H100的有效分配,研究人员能够进一步改进Muse实例,包括更高分辨率的图像编码器和更大的模型,并扩展到所有7个Bleeding Edge地图。
微软高级研究员Tabish Rashid提到:“最初分配H100是相当艰巨的,尤其是在早期阶段,要弄清楚如何最好地利用它来扩展到带有新图像编码器的更大型号。经过数月的实验,终于在不同的地图上看到模型的输出,并且不必眯着眼睛看较小的图像,这是非常有益的。”
三、生成效果接近人类真实水平,新角色也能合理融入
论文阐释了研究人员对模型一致性、多样性和持久性的具体评估结果。
研究人员通过Fréchet视频距离 (FVD)衡量一致性效果。研究中使用模型生成游戏视觉效果,以包含视频和控制器动作的1秒游戏体验为条件,再加上人类玩家在接下来的9秒内的游戏过程中采取的控制器动作,可以看出生成的游戏玩法与真实情况匹配。

Wasserstein距离是以前用于评估模型动作是否捕捉到人类动作全部分布的指标。研究人员将真实人类行为的边际分布与模型生成的边际分布进行了比较,Wasserstein距离越短,模型的世代就越接近人类玩家在我们的数据集中采取的行动。在训练过程中,所有模型的Wasserstein距离都会减小,接近人与人基线(计算为人类动作序列中两个随机动作子集之间的平均距离)。

为了评估模型的持久性,研究人员通过插入游戏内对象、其他玩家、地图元素之一来手动编辑游戏图像。结果表明,Muse能够保留已插入到看似合理但新的起始位置的常见游戏元素。

结语:微软世界模型,开启重塑游戏体验新大门
微软新推出的世界模型为我们呈现了生成式AI在游戏领域的巨大潜力,正如其在示例中所言,这样的模型既可以学习游戏世界的丰富结构,还能展示如何进一步支持模型的创造性使用。这可能会从根本上改变用户未来保存和体验经典游戏的方式,并使更多玩家接触到它们。
同时,他们一开始通过与多学科人员的协作,以找到构建模型能力满足创意人员需求的切入点,也为模型在不同场景的应用提供了经验。
目前,微软已经开源了权重和样本数据,会加速开发者基于此进行后续研究,或许会在不久的将来诞生基于AI的新颖游戏体验,挖掘出AI在游戏应用的更多应用场景。