


美国时间4月30日,Facebook F8 开发者大会在美国加利福尼亚州的圣何塞举办。在此次开发者大会期间,Facebook开源了简化模型优化的工具——BoTorch和Ax,还发布了Pytorch 1.1。
Facebook F8 大会主要面向围绕该网站开发产品和服务的开发人员及企业家,大会通常包括主题演讲以及 Facebook 新产品、新工具的发布。其名称源自 Facebook 的 8 小时黑客马拉松竞赛。
在今年的 Facebook F8 大会上,扎克伯格谈到了过去一年最敏感的隐私问题,称「过去我们常常是先发布,然后发现问题后再解决」,「未来我们会更加谨慎,咨询专家做出评估,并采取更为主动积极的应对策略」。
除此之外,Facebook 还发布了 PyTorch 的最新迭代版本——Pytorch 1.1 以及用于简化模型优化流程的新工具 BoTorch 和 Ax。
开源 Ax 和 BoTorch 简化 AI 模型优化
在 F8 开发者大会上,Facebook 开源了两款全新的 AI 工具:Ax 和 BoTorch,让开发者无需大量数据就能在研究与产品中解决 AI 难题。
据 Facebook 博客介绍:
- BoTorch 是一个基于 PyTorch 的灵活、新式的
- 贝叶斯
- 优化库;
- Ax 是一个理解、管理、部署、自适应实验的易获取、通用 AI 平台;

项目地址:https://botorch.org (https://botorch.org/)
其实,BoTorch 并非首个贝叶斯优化工具,但 Facebook 发现已有的工具难以扩展或者自定义,无法满足他们日益增长的需求。所以,Facebook 开发了全新的方法,让它能够支持多噪声目标函数优化,可扩展到高度并行的测试环境,利用低保真度逼近、优化高维参数空间。
Facebook 利用 PyTorch 的计算能力,重新思考了实现模型和优化程序的路径,开发出了 BoTorch。整体来说,BoTorch 提供了一个模块化以及用于组合贝叶斯优化原语的易扩展接口,包括概率代理模型,采集函数(acquisition functions)和优化器。它还提供以下支持:
当前硬件(包括 GPU)上的自动差分、高度并行化计算,以及通过 PyTorch 与深度学习模块的无缝集成。
GPyTorch 中最顶级的概率建模,包括支持多任务高斯过程(GP)、可扩展 GP、深度核学习、深度 GP 和近似推理。
通过再参数化技巧的基于蒙特卡罗的采集函数,使得实现新思想变得简单,不需要对基础模型施加限制性假设。
Facebook 表示,BoTorch 大大提高了贝叶斯优化研究的开发效率。它为无法分析解决方案的新方法打开了大门,包括批量采集函数和正确处理具有多个相关结果的丰富多任务模型。BoTorch 的模块化设计使研究人员能够更换或重新排列单个组件,自定义算法的各个方面,从而使他们能够对现代贝叶斯优化方法进行最前沿的研究。
自适应实验可扩展平台 Ax
为了配合 BoTorch,Ax 提供了易于使用的 API,以及面向产品和研究复现所需的管理。在开发层面,这使得开发人员能够专注于应用的问题,例如探索配置等;在研究层面,它让研究人员能够花更多时间专注于贝叶斯优化的构建块。
下图展示了 Ax 和 BoTorch 在优化生态系统中的应用。以 Facebook 为例,Ax 与其主要 A / B 测试、机器学习平台,以及模拟器、其他后端系统相接,需要最少的用户参与来部署配置以及收集结果。
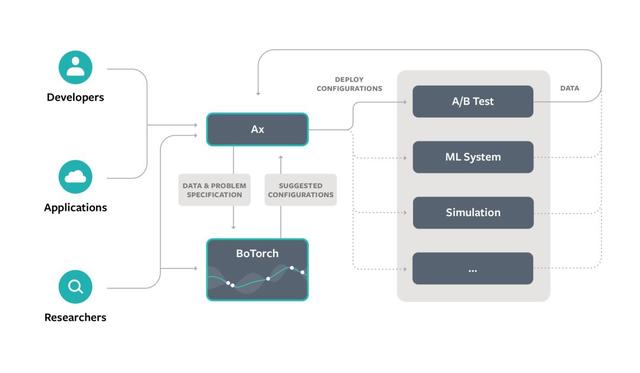
Ax 让开发人员能够创建自定义优化应用程序,或者从 Jupyter 笔记本中临时优化。新算法可以使用 BoTorch 库或其他应用程序实现。
通过以下核心功能,Ax 降低了开发人员和研究人员进行自适应实验的障碍:
- 跨框架接口:实现新的自适应实验算法。虽然 Ax 大量使用 BoTorch 作为其优化算法,但提供了通用的 NumPy 和 PyTorch 接口,以便研究人员和开发人员可以插入任何框架中可实现的方法。
- 可定制的自动化优化程序。根据实验的特征,Ax 从贝叶斯优化、 bandit 优化以及其他技术中选择适当的优化策略。用户可以轻松定制这些默认例程,以满足其特定应用程序的需求。
- 系统理解工具。交互式的可视化让用户可以查看代理模型、执行诊断,以及了解不同结果之间的权衡。
- 人可参与的优化。除了支持多个 objective 和系统理解之外,Ax 的底层数据模型还使实验者能够在收集新数据时安全地介入其搜索空间和目标。
- 创建自定义优化服务的能力。多个 API 使得 Ax 既可用作部署控制、收集数据的框架,也可用作可通过远程服务调用的轻量级库。
- 用于评估新的自适应实验算法的基准测试套件。轻松比较不同算法在测试问题上的优化性能,并保存结果,以便进行可重复的研究。
为了展示 Ax 是如何工作的,以下是一个使用人工 Booth 函数作为评估函数的简单优化循环示例:
from ax import optimize
best_parameters, _, _, _ = optimize(
parameters=[{"name": "x1","type": "range","bounds": [-10.0, 10.0],},{"name": "x2","type": "range","bounds": [-10.0, 10.0],},],
evaluation_function=lambda p: (p["x1"] + 2*p["x2"] - 7)**2 + (2*p["x1"] + p["x2"] - 5)**2,
minimize=True,)
best_parameters# returns {'x1': 1.02, 'x2': 2.97}; true min is (1, 3)
发布 PyTorch1.1
自 2017 年开源以来,PyTorch 已经成为全世界最受欢迎的深度学习框架之一。去年秋季发布的《2018 年 GitHub Octoverse 报告》称 PyTorch 是 GitHub 平台上最受欢迎的开源项目之一,全世界有 3100 万开发者使用 PyTorch。去年 12 月,在 NeurIPS 2018 大会上,Facebook 发布了 PyTorch 1.0 正式版。时隔半年,今天,Facebook 发布了 PyTorch1.1。
项目地址:https://github.com/pytorch/pytorch/releases/tag/v1.1.0
官方博客:https://pytorch.org/blog/optimizing-cuda-rnn-with-torchscript/
与之前的版本相比,PyTorch 1.1 具备以下特性:
- 提供 TensorBoard 的官方支持;
- 升级了即时编译(JIT)编译器;
- 提供新的 API;
- 不再支持 CUDA 8.0。
提供 TensorBoard 的官方支持
TensorBoard 是 Tensorflow 中的一个在浏览器内直接可视化机器学习模型的工具。作为一个用于检查和理解训练脚本、张量和图的 web 应用程序套件,用户可利用 TensorBoard 进行第一级和原生可视化支持以及模型调试。PyTorch 中没有这样的工具,之前有一些方法可以让开发者们在 PyTorch 中使用 TensorBoard,但 PyTorch 一直没有提供官方支持。
现在,PyTorch 1.1 开始官方支持 TensorBoard,只要写入一个简单的「from torch.utils.tensorboard import SummaryWriter」命令即可。直方图、嵌入、图像、文本、图等可在训练中实现可视化。不过,PyTorch 对 TensorBoard 的官方支持目前还处于试验阶段。文档浏览地址:https://pytorch.org/docs/stable/tensorboard.html。
升级了即时编译(JIT)编译器
PyTorch 发明者 Soumith Chintala 认为,JIT 编译器促成了深度学习框架的里程碑式性能改进。PyTorch1.1 升级了用于优化计算图的 JIT 编译器。
Chintala 说道:「一直以来,我们都与英伟达紧密合作,基本上将所有优化都添加到 JIT 编译器中……新版 JIT 编译器实际上接近 cuDNN 的速度,这意味着用户的工作效率会提高很多。」
Chintala 称:「JIT 编译器初版在 PyTorch1.0 中即可使用,但其工作速度并没有比 PyTorch 的基本模式快多少。新的 JIT 编译器是研究者和自动驾驶模型构建者非常需要的一种工具。」JIT 编译器还将为 PyTorch 带来更多的 Python 编程语言概念。
现在,JIT 编译器能够在运行时确定如何生成最有效率的代码。Chintala 希望 JIT 编译器可以为自定义 RNN 模型提供更佳的性能。
提供新的 API
PyTorch1.1 具有新的 API,支持布尔张量以及自定义循环神经网络。
不再支持 CUDA 8.0。
CUDA 8.0 与 PyTorch 1.0 搭配使用效果较好,但 PyTorch 1.1 将不再支持 CUDA 8.0。
主要性能提升
- nn.BatchNorm CPU 推理速度增加 19 倍
- nn.AdaptiveAvgPool:将常见情况下 size 为 1 的输出加速 30 倍
- nn.Embedding Bag:CPU 性能提高了 4 倍
- Tensor.copy_:将更大的张量复制加速 2-3 倍。
- torch.nonzero:比 CPU 上的 numpy 快 2 倍
- 改进用于 Pascal 和新 GPU 的缓存分配器;Mask-RCNN 上的内存使用率提升了 10-20%
- reducation functions:将一些大张量加速 50-80%
- [JIT] 图融合器:在广播的情况下更好地融合反向图
- [JIT] 图融合器:用于推理的 batch_norm 融合
- [JIT] 图融合器:用于推理的 layer_norm 融合
参考链接:
- https://github.com/pytorch/pytorch/releases/tag/v1.1.0
- https://venturebeat.com/2019/05/01/facebook-launches-pytorch-1-1-with-tensorboard-support/