

选自Facebook AI Blog
作者:Sonia Kim、Hongyu Li、Satish Chandra
机器之心编译
参与:路、一鸣、思源
如何基于文本查询快速获取代码示例,对于工程师而言是一个很影响效率的事儿。Facebook 最近提出了新型代码搜索工具——神经代码搜索(NCS)和 UNIF,分别基于无监督和监督的方式提供快速高效的代码检索。
当工程师能够轻松获取代码示例,指导其完成特定编程任务时,他们的工作效率会显著提高。例如,对于「如何以编程方式关闭或隐藏安卓软键盘?」这类问题,工程师可以从 Stack Overflow 等常用网站上获取可用信息。但是当问题涉及专有代码或 API(或者用不常用编程语言写的代码)时,工程师需要不同的解决方案,因为在常用论坛上可能找不到这方面的答案。
为了解决这个需求,Facebook 开发了一个代码搜索工具——神经代码搜索(Neural Code Search,NCS),该工具使用自然语言处理(NLP)和信息检索(IR)技术直接处理源代码文本。该工具接收自然语言作为查询(query),并返回从代码库中直接检索到的相关代码段。这里的前提是能够获取大型代码库,从而更有可能搜索到与开发者提出的查询相关的代码段。
Facebook 介绍了两种可用模型:
- NCS:结合自然语言处理和信息检索技术的无监督模型;
- UNIF:NCS 的扩展,当训练过程中有好的监督数据时,UNIF 使用监督神经网络模型来提升性能。
利用 Facebook AI 开源工具(包括 fastText、FAISS、PyTorch),NCS 和 UNIF 将自然语言查询和代码段表示为向量,然后训练一个网络,使语义相近的代码段和查询的向量表示在向量空间中彼此靠近。使用这些模型,我们能够从代码库中直接寻找代码段,从而高效解决工程师的问题。为了评估 NCS 和 UNIF,Facebook 使用了新创建的数据集(包含 Stack Overflow 上的公开查询和对应的代码段答案)。结果表明,这两个模型可以正确回答该数据集中的问题,如:
- 如何关闭/隐藏安卓软键盘?
- 如何在安卓中将位图转换为可画的?
- 如何删除一整个文件夹及其内容?
- 如何处理 back button?
NCS 的性能表明,相对简单的方法可以很好地处理源代码;UNIF 的性能表明,简单的监督学习方法可以在有可用标注数据时,提供显著的额外收益。当这些模型与其他 Facebook 构建系统(如 Aroma 和 Getafix)结合时,这个项目可以为工程师提供可扩展且不断增长的 ML 工具包,帮助他们更高效地写代码、管理代码。
NCS 如何使用嵌入向量
NCS 模型使用嵌入(连续向量表示)来捕捉程序语义(即代码段的意图)。当进行恰当计算时,这些嵌入能够将语义相近的实体在向量空间中拉近距离。
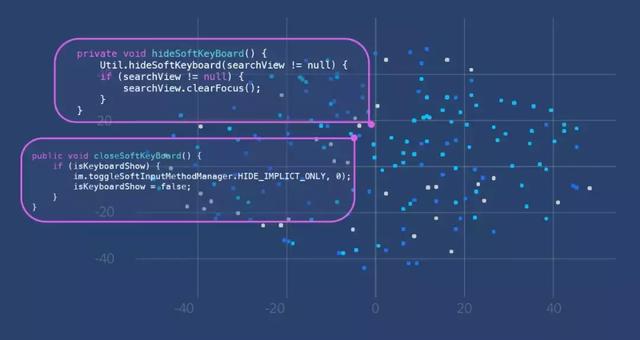
如下图示例所示,关于如何关闭/隐藏安卓软键盘有两个不同的方法。由于它们共享类似的语义,因此即使它们代码行不完全相同,它们在向量空间中的位置彼此接近。

上图表明语义相近的代码段在向量空间中距离较为接近。
Facebook 使用这个概念构建 NCS 模型。总体而言,在模型生成过程中,每个代码段以方法级粒度嵌入到向量空间中。一旦模型构建完成,给定的查询语句就会映射到同样的向量空间中,那么向量距离就可用于估计代码段与查询的相关程度。
下图展示了模型生成和搜索检索流程:

上图展示了 NCS 的整个模型生成和搜索检索过程。
模型生成
为了生成模型,NCS 必须抽取单词,构建词嵌入,然后构建文档嵌入。(这里「文档」指方法体(method body)。)
抽取单词

NCS 从源代码中抽取单词,并执行分词,生成词的线性序列。
为了生成能表示方法体的向量,Facebook 将源代码看作文本,从以下句法类中抽取单词:方法名称、方法调用、枚举值、字符串文本和注释。然后基于标准英语规范(如空格、标点)和代码相关标点(如下划线命名法和驼峰命名法)执行分词。例如上图中,对于方法体(或方法名)「pxToDp」,源代码可作为以下单词的集合:「converts pixel in dp px to dp get resources get display metrics」。
对于代码库中的每个方法体,我们都可以用这种方法对源代码执行分词,并为每个词学习一个嵌入。之后,从每个方法体中抽取的单词列表类似一个自然语言文档。
构建词嵌入
Facebook 使用 fastText 为词汇语料库中的所有单词构建词嵌入。fastText 使用一个两层神经网络计算向量表示,该网络可以在大型语料库上以无监督方式训练。具体来讲,Facebook 使用 skip-gram 模型,利用目标 token 的嵌入来预测固定窗口大小中的上下文 token 的嵌入。如上例所示,给出 token「dp」的嵌入、窗口大小为 2,skip-gram 模型学习预测 token「pixel,」、「in,」、「px,」、「to.」的嵌入。其目标是学习嵌入矩阵

,其中 |V_c| 表示语料库大小,d 表示词嵌入的维度,T 的第 k 行表示 V_c 中第 k 个单词的嵌入。
在该矩阵中,如果两个向量表示对应的单词经常出现在相似语境,则这两个向量表示距离较近。Facebook 使用该命题的逆命题帮助定义语义关系:向量距离接近的单词应该语义相关性较高。这在自然语言处理中叫作「分布假设」(distributional hypothesis),源文本同样适用于这一概念。
构建文档嵌入向量
下一步是利用方法体中的单词将其总体意图表达出来。为此,研究人员计算了方法体中所有词语的词嵌入向量的加权平均值。这被称为是文档嵌入。

公式中,d 表示方法体的词语集合,v_w 是词 w 的词嵌入,使用 fastText 处理。C 是包含所有文档的语料,u 是归一化函数。
研究人员使用词频-逆文档频率(TF-IDF),为给定文档中的给定词语分配权重。这一步骤旨在强调文档中最为重要的词语,即如果一个词在文档中出现频率很高,则它的权重很高,但如果它在语料库中的多个文档中都有出现,则该词汇会受到惩罚。
在这一步之后,研究人员给语料库中每个方法体的文档向量表示一个索引数字。模型生成就完成了。
搜索检索
搜索查询可以用自然语言表达,例如「关闭/隐藏软键盘」或「如何建立一个没有标题的对话框」。研究人员使用同样的方式对查询和源代码执行分词,且使用同样的 fastText 词嵌入矩阵 T。研究人员简单地计算了词向量表示的平均值,建立一个查询语句的文档嵌入,词表外的词被舍弃。研究使用标准的相似度搜索算法 FAISS,用于寻找和查询的余弦相似度最接近的文档向量,并返回 top n 个结果。(此外还有一些训练后排序,详情参见:https://dl.acm.org/citation.cfm?id=3211353)

两个方法体和查询被映射在相同的向量空间中,且位置较为接近。这说明查询和这两个方法体在语义上相似,且相关。
实验结果
研究人员使用 Stack Overflow 问题测试 NCS 的性能。使用标题作为查询,以及答案中的一个代码段作为理想的代码回答。给定一个查询,研究人员评价模型能否在 top 1、5 或 10 个回答上从 GitHub 仓库集合中抽取正确的代码段。研究人员还提供了平均排序倒数(MRR)分数,用于衡量 NCS 能否在第 n 个结果返回正确的答案。
在 287 个问题中,NCS 能在 top 10 个结果内正确回答 175 个问题,大约是整体数据集的 60%。研究人员同时对比了 NCS 和其他传统信息检索算法的表现,如 BM25。如下图所示,NCS 的性能优于 BM25。

下面是 NCS 回答很好的一个问题示例:「从 app 中打开安卓市场」,NCS 返回的第一个答案如下所示:
private void showMarketAppIn() {
try {
startActivity(new Intent(Intent.ACTION_VIEW, Uri.parse("market://details?id=" + BuildConfig.APPLICATION_ID)));
} catch (ActivityNotFoundException e) {
startActivity(new Intent(Intent.ACTION_VIEW, Uri.parse("http://play.google.com/store/apps/details?id="
+ BuildConfig.APPLICATION_ID)));
}}
UNIF:监督式方法
NCS 的关键在于词嵌入。由于 NCS 是无监督模型,它有很多优势。首先,它可以直接从搜索语料中学习,训练很快、很简单。NCS 假设查询中的词和源代码中抽取的词有着相同的域,因为查询和代码段被映射在相同的向量空间中。然而,事实不一定总是这样。
例如,「Get free space on internal memory」里,没有一个词出现在以下代码段中。研究人员想实现的是将查询词「free space」映射到下列代码中的单词「available」。
File path = Environment.getDataDirectory();
StatFs stat = new StatFs(path.getPath());
long blockSize = stat.getBlockSize();
long availableBlocks = stat.getAvailableBlocks();
return Formatter.formatFileSize(this, availableBlocks * blockSize);
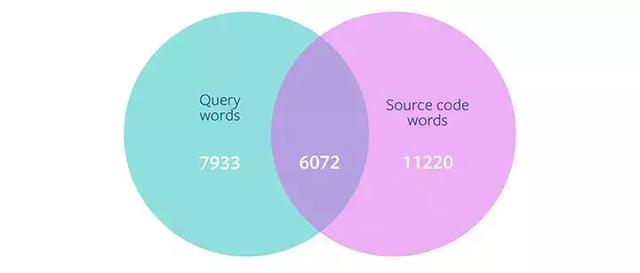
基于包含 14005 个 Stack Overflow 帖子的数据集,Facebook 研究人员分析了查询词和源代码中词语的重叠情况。他们发现,查询中有 13,972 个唯一字,其中只有不到一半(6072 个词)在源代码中出现了。这说明,如果一个查询包含源代码没有的词,则 NCS 模型无法有效地检索正确的方法。这一结果促使研究人员进一步探索监督学习模型,以将查询词映射到源代码中。
Facebook 研究人员决定尝试 UNIF。这是一个监督模型,基于 NCS 进行了微小的扩展,用于连接自然语言和源代码。在这个模型中,研究人员使用监督学习训练词嵌入矩阵 T,生成两个嵌入矩阵 T_c 和 T_q,分别对应代码 token 和查询 token。此外,研究人员还用基于注意力的权重机制替换了代码 token 嵌入向量的 TF-IDF 权重机制。
UNIF 模型工作原理
研究人员在与训练 NCS 同样的 (c, q) 数据点集合中训练 UNIF,c、q 分别表示代码 token 和查询 token。模型架构表示如下:
T_q ∈ R^|V_q|×d 和 T_c ∈ R^|Vc |×d 是两个嵌入矩阵,分别映射每个自然语言描述单词和代码 token 到向量,向量长度为 d(V_q 是自然语言查询语料,V_c 是代码语料)。这两个矩阵使用同样的初始权重 T 初始化,并分别在训练中进行修改(对应 fastText)。
为了将离散的代码 token 向量结合为一个文档向量,研究人员使用注意力机制计算加权平均值。注意力权重 a_c ∈ R^d,是一个 d 维向量,从训练中学得,并代替了原有的 TF-IDF 权重。给定一个代码词袋嵌入向量 {e_1, ....., e_n},每个 e_i 的注意力权重 a_i 如下:

文档向量通过和注意力权重相乘后的词嵌入向量相加得到:

为了创建查询文档向量 e_q,研究人员求得每个查询词嵌入向量的平均,这和 NCS 的方法相同。在训练过程中,模型从标准的反向传播中学习参数 T_q、T_c、a_c。

UNIF 网络结构图示。
检索工作和 NCS 一致。给定一个查询,利用上述方法将其表示为文档向量,然后使用 FAISS 寻找和查询的余弦相似度最相近的文档向量。(原则上,UNIF 可以从后处理排序中获益,正如 NCS 那样。)
UNIF 和 NCS 的效果对比
研究人员对比了 NCS 和 UNIF 在 Stack Overflow 评测数据集上的表现。评价方法是模型能否用 top1、top5、top10 结果正确地解答此查询,评价使用 MRR 分数。下表说明,相比 NCS,UNIF 显著提高了回答问题的数量。

如此惊人的搜索性能说明,如果提供合适的训练语料,监督模型可以完成这项任务。例如,搜索查询是「如何退出应用并展示主菜单?」,NCS 会返回:
public void showHomeScreenDialog(View view) {
Intent nextScreen = new Intent(getApplicationContext(), HomeScreenActivity.class);
startActivity(nextScreen);}
而 UNIF 提供了更相关的代码:
public void clickExit(MenuItem item) {
Intent intent=new Intent(Intent.ACTION_MAIN);
intent.addCategory(Intent.CATEGORY_HOME);
intent.setFlags(Intent.FLAG_ACTIVITY_NEW_TASK);
metr.stop();
startActivity(intent);
finish();}
另一个例子是提问:「如何获得 ActionBar 的高度?」,NCS 模型会返回:
public int getActionBarHeight() {
return mActionBarHeight;
}
UNIF 返回相关的代码:
public static int getActionBarHeightPixel(Context context) {
TypedValue tv = new TypedValue();
if (context.getTheme().resolveAttribute(android.R.attr.actionBarSize, tv, true)) {
return TypedValue.complexToDimensionPixelSize(tv.data,
context.getResources().getDisplayMetrics());
} else if (context.getTheme().resolveAttribute(R.attr.actionBarSize, tv, true)) {
return TypedValue.complexToDimensionPixelSize(tv.data,
context.getResources().getDisplayMetrics());
} else {
return 0;
}}
更多关于 UNIF 的性能情况,可以参考论文:https://arxiv.org/abs/1905.03813。