

本文为AI 研习社编译的技术博客,原标题:
WaveNet: Google Assistant’s Voice Synthesizer
作者|Janvijay Singh
翻译| 酱番梨、王立鱼、莫青悠、Disillusion
校对、整理| 菠萝妹
一文带你读懂WaveNet:谷歌助手的声音合成器
有没有想过有可能使机器合成的人类声音几乎和人类本身的声音一样自然? WaveNet使其成为可能。
语音合成. 波音拼接合成. 参数合成. 深度学习.机器合成拟人化语音(文语转换)的想法已经存在很长时间了。在深度学习出现之前,存在两种主流的建立语音合成系统的方式,即波音拼接合成和参数合成。
在波音拼接合成的文语转换中,它的思路就是通过收集一个人的一长列句子的发声录音,将这些录音切割成语音单元,尝试着将那些和最近提供的文本相匹配的语音单元进行拼接缝合,从而生成这文本对应的发声语音。通过波音拼接合成产生的语音,对于那些文本已经存在于用于初始收集的录音之中的部分,文语转换后的语音听上去比较自然,但是那些初次遇见的文本,就会听上去有些异样。除此之外,修饰声音要求我们对整个新录音集进行操作。反之在参数合成的文语转换中,它的思路是通过参数物理模型(本质上来说就是一个函数)来模拟人类的声道并使用记录的声音来调整参数。通过参数合成文语转换生成的声音听上去没有通过音波结合文语转换生成的声音那么自然,但是这种方式更容易通过调整某些模型中的参数来修饰声音。
近日来,随着WavNet的面世,对我们来说以端对端(来自声音记录本身)的方式来生成未处理的声音样本成为可能,可以简单的修饰声音,更重要的是和现存的语音处理方式相比,得到的声音明显的更加自然。所有的一切都要感谢深度学习的出现。
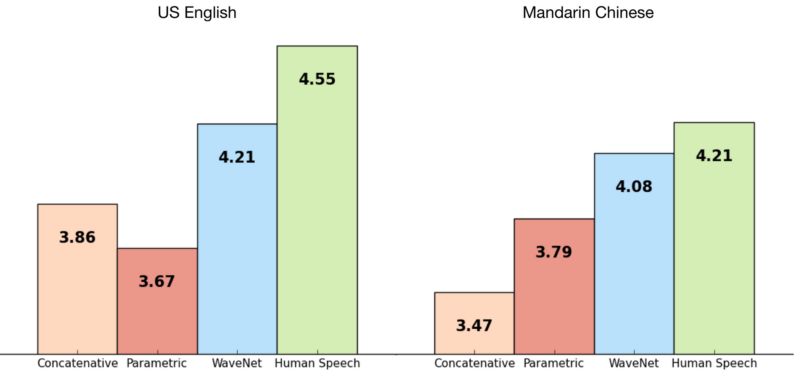
为什么WaveNet会让人如此的激动?为了能够描绘出WaveNet和现存的语音合成方法的区别,采用了主观5分平均意见分法(MOS)测试进行统计。在平均意见分测试中,提供给对象(人)从各个声音合成系统中合成的声音样本,并被要求以5分制来评估样本的自然度(1:很差2:较差3:一般4:好5:优秀)。
用于主观5分平均意见分法的声音样本分别从基于长短期记忆-循环神经网络(LSTM-RNN)的参数合成,基于隐马尔可夫模型(HMM)的语音单元集的波音拼接合成,和基于WaveNet的语音合成得到的。
从柱状图中可以清晰看到,WaveNet在5分制中得到了大概4.0分左右,很明显是优于其他的系统基线的,并且非常接近真实的人类声音。查阅了DeepMind’s blog 可以认识到在合成的语音的自然度方面这些方法的区别所在。除了能够输出合成的语音样本,WaveNet能够轻松的适应各种各样的语音特性,如:文本,发言者特性等,来生成满足我们需求的声音。这使它更加的令人感到激动。
WaveNet. 生成式模型.
生成式模型。这是指什么呢?给出的一般的未标记的数据点,一个生成式模型会尝试去学习什么样的概率分布可以生成这些数据点,目的是为了通过利用学习分布来产生新的数据点(与输入数据点相似)。生成式模型可以通过不同的方式对概率分布建模,隐式(具有可处理或近似密度)或者显式。当我们说一个生成式模型是显式建模模型的话,意味着我们明确的定义概率分布并尝试去适配每一个输入的未标记数据点。与它形成对比,一个隐式生成式模型学习一个概率分布,可以直接取样新数据点而不需要明确的定义。GANs(生成对抗网络),目前深度学习领域的圣杯,就属于隐式生成式模型。然而,WaveNet和它的表亲Pixel CNNs/RNNs(像素卷积神经网络模型/递归神经网络模型) 都属于显示生成式模型。
WaveNet如何明确的建立概率分布模型?WaveNet试图对一个数据流X的联合概率分布建立模型,对数据流X中的每一个元素Xt的条件概率求乘积。因此对于一段未处理音波X = {X1, X2, X3 … XT},构建的联合概率函数如下:
每一个样本Xt 因此而受限于所有的先前时间步长的样品。在一个时间步长上的观察结果取决于先前时间步长的观察结果(这就是我们试图使用每一个条件分布项去构建的模型),这看上去难道不像是一个时间序列预测模型吗?事实上,WaveNet是一个自动回归模型。
我们要如何去对这些条件分布项进行建模呢?RNs(递归神经网络模型)或者LSTMs(长短记忆网络模型)作为强有力的非线性时序模型是最显而易见的选择。事实上,像素递归神经网络使用同样的思路来生成与输入的图像相似的合成图像。我们可以使用这种思路来生成合成语音吗?语音是从至少16KHZ的频率取样,这意味着,每秒的音频至少有16000个样本。RNNs(递归神经网络)或者LSTMs(长短记忆网络)还未曾对如此长(大约10000时间步长序列)的时间依赖性进行建模,他们目前能建模的最长时间依赖性是100时间步长序列,因此这两种模型并不能很好的适用于语音合成。我们能否适用CNN(卷积神经网络)来处理呢?等一下,CNNs(卷积神经网络模型)?如何做到呢?相似的思路已经被使用于像素卷积神经网络模型中了。
卷积神经网络模型. 因果卷积. 膨胀卷积.为什么我们要尝试使用CNNs(卷积神经网络模型)?CNNs(卷积神经网络模型)训练速度与RNNs(递归神经网络模型)或者LSTMs(长短记忆网络模型)相比是典型地更快速,尤其是应用于长的一维序列,因为与每一个掩模或过滤器的卷积位置相关的操作可以以一个并行,独立的方式进行。更快的训练速度。听上去很棒!自回归(一个时间步长的输出是只依赖于先前时间步长的输出而与未来时间步长的输出无关)的性能如何呢?因果卷积在此转化成行动。一维因果卷积可以轻易的通过左填充输入的一维序列来执行,在这里通过为卷积补充适量的0来得到一个可用的卷机。与RNNs(递归神经网络模型)和LSTMs(长短记忆网络模型)相比,因果卷积可以允许我们去对长的多的时间依赖性(也允许我们指定回看长度)进行建模。
因果卷积确保模型不会违反我们对数据构建的模型的规则
很好!我们已经可以轻易地处理自回归违规的问题。但是关于管理几千个样本序列的回看长度的问题呢(例如我们的模型在当前时间步长上画一个关于输出的卷机之前,回看至少一秒的音频)? 能想到的最简单实现的方式就是将过滤器的规格增加到足够可以回看适当长度,但是这种方式真的有效吗? 我认为这种做法会使模型减少非线性,这会导致模型难以学习复杂的暂时依赖性,从而限制了模型的性能。你想到的下一个想法可能是增加神经网络的层数。这种方法可能有效。但是计算上是不可能的,因为对输出中的一个时间步长内的接受域大小或者回看长度,随模型中的隐藏层数线性增长,而对于我们计算上来说是不希望有一个有着几千个隐藏层的模型。现在我们要考虑的是限制隐藏层的数量、过滤器的大小和增加回看长度?我们将如何做到呢?膨胀卷积将会帮助我们。
膨胀卷积尝试通过将过滤器应用在超过它本身长度的区域上和按特定步骤跳过输入值的方式,来增加回看长度或者接受域大小。 这等同于一个卷积使用通过0来扩充原过滤器得到更大的过滤器但是显然这种方式更加有效。在WaveNet中,多重膨胀卷积层一个个叠放来通过极少的层来获得极大的接受域。
膨胀因果卷积层堆:加倍每层的膨胀因子会使接受域以O(2^n)倍增。
Softmax(柔性最大传输函数)分布. Mu-law 压缩.为了对条件概率见面,WaveNet采用softmax分布(分类分布)来替代其他的混合模型,分类分布没有对它的形状进行假设,因此而更加灵活,更容易对任意分布建模。 未处理音频被作为16位整数值(-32,768...32,767)存储,使用一个softmax层输出概率分布需要我们的模型在一个时间步长上输出65,5535个数值。这会拉慢模型表现吗?这确实会。我们可以做什么来改善呢?减少位深度会起到作用。如果我们使用线性位深度减少(除以256)对低振幅样本的影响会比对高振幅样本的影响更大。 考虑一个初始值是32767的16位样本,可取的最大正数值。转化为8位,样本值变为127(32767/256 = 127余255),舍入误差是255/32768。 这是一个小于1%的量化误差。但是将这个误差与最小量级的16位样本,那些取值在0与255之间的样本,获得的量化误差相比较。当最小量级的16位样本简化成8位的时候,转化后的值会接近于0,误差是100%。所以使用线性位深度缩减方法舍入,对低振幅样本的影响会比对高振幅样本的影响更大。 如果我们可以重新分配样本数值,更多的量化等级在较低的振幅,少量的量化等级在较高的振幅,就可以减少量化误差。这就是在WaveNet中使用Mu-law分布(非线性量化)来代替使用简单的线性量化的原因。
执行Mu-law压缩的表达式比使用线性量化的可以等到更优的重构输出(更接近与原音频) 。
在上面的表达式中,−1 < Xt < 1(音频的样本在不同的时间不长重新取样,从-32,768...32,767转为-1...1), µ = 255。这将使模型在每个时间步长中只输出256个值而不是65,535个值,提高了训练和推论的速度。
选通激活函数. 跳跃连接和残差连接.
非线性激活函数对于任何一个学习输出与输入之间的复杂关系的深度学习模型来说都是要素之一。RELU(线性单元)最初在WaveNet中被使用,但是在执行实验后发现,对于WaveNet来说,使用一个非线性的tan-hyperbolic(tanh)函数选通sigmoid (S型)函数的激活函数效果更好。
在WaveNet中使用的选通激活函数表达式
在上面的表达式中,W 表示可许阿西过滤器,* 表示卷积算子,⊙表示同或数学运算符。残差连接,不断叠加底层和它上层的输出,跳跃连接,直接将底层输出叠加到输出层,这两者已经证实在减少神经网络与训练深层网络的收敛时间方面是有效的。因此,如下图所示,残差连接已经在WaveNet的架构中被使用。
WaveNet架构:选通激活函数,跳跃连接,残差连接
调节. 本地. 全局.
现在还没有讲到,我们如何根据演讲者身份,相应文本等各种功能来调节输出语音。WaveNet的输出语音可以通过两种方式进行调节:(1)全局调节,(2)单个特征偏置输出所有时间步骤,如说话者的身份或局部调节,具有多个特征,实际上是不同的时间序列特征,其在不同时间步骤偏置输出,如语音的基础文本。如果我们更正式地表达这一点,那么这将意味着在实际模型中在条件分布术语(本地条件中的Ht和全局调节中的H)中引入新参数。
在引入条件输入之后修改条件分布项
在本地调节中,调节输入的时间序列可能具有比音频更短的长度,并且对于局部调节,要求两个时间序列必须具有相同的长度。为了匹配长度,我们可以使用转置的CNN(一种可学习的上采样方案)或其他上采样方案来增加调节输入的长度
引入偏差项h后的表达式
在上面的表达式中,V是可学习的线性投影,其基本上用于两个目的变换h以校正尺寸并学习偏置输出的正确权重。
很棒的模型. 快速的训练. 缓慢的推理?
WaveNet的架构,无论我们到目前为止讨论了什么,都很好地捕获了复杂的时间依赖性和条件。除此之外,高度并行化使训练变得非常迅速。但是推理呢?由于时间步长的输出依赖于前一个时间步长的输出,所以对新音频的采样本质上是连续的。产生1秒的输出大约需要1分钟的GPU时间。如果谷歌将这个模型部署到他们的助手上,那么对于像“嘿谷歌!天气怎么样?”这样简单的问题也得花上几个小时来思考。那么他们是如何缩短推理时间的呢?IAF就是答案。
规范化流程IAF
什么是规范化流程?规范化流程是一系列转换的过程,可以学习从从简单概率密度(如高斯)到丰富的复杂分布的映射(双射)。设想一下,如果你从概率分布q(z)和概率分布q(x)中采样中得到足够多的点,那么这个规范化流程可以用来学习转换过程,也就是从q(x)采样的点映射到其在分布q中的相应映射(Z)的过程。这个过程如何完成的?让我们先考虑有一个转换f,f是一个一个可逆和平滑的映射。如果我们使用此映射来转换具有分布q(z)的随机变量z,那么,我们得到的随机变量z'= f(z)具有分布q(z'):
为了向你更加直观地介绍,我们是如何为变换后的随机变量的分布得出这个表达式,请查看Eric Jang的这篇博客文章。一个转换是否足够?实际上,我们可以通过组合几个简单的变换,并连续应用上述表达式来构造任意复杂的密度。通过将分布q0通过K变换链fk连续变换随机变量z0而获得的密度qK(z)是:
这些变换中的每一个都可以使用矩阵乘法(具有可学习的值)轻松建模,然后是非线性,例如ReLU。然后,通过优化在变换的概率分布qK(z)下从q(x)采样的点的似然性(对数似然),使用任何您喜欢的优化算法来更新变换的可学习参数。这将使分布qK(z)与q(x)非常相似,从而学习从q(z)到q(x)的适当映射。
经过一系列可逆变换的分布流
规范化流程的想法如何帮助我们快速推理?请记住,WaveNet是一个生成模型,它除了尝试学习可能产生训练数据的概率分布之外,什么都不做。因为它是一个明确定义的生成模型(具有易处理的密度),我们可以很容易地学习一个可以映射简单点的转换,像Gaussian这样的分布到WaveNet学习的复杂分类分布。如果学习到的具有快速推理方案的规范化流程,我们可以轻松地对WaveNet中的慢推理问题进行排序。 IAF(反向自回归流)可以很好地适应这种想法。 在IAF中,我们的想法是首先从z~Logistic(0,I)中抽取随机样本,然后将以下变换应用于绘制的样本。
zt上的简单缩放和移位变换,其中缩放因子(s)和移位因子(μ)通过使用可学习参数(θ)和来自先前时间步长的输入样本z中的值来计算
为了输出时间步长xt的正确分布,逆自回归流基于噪声输入z1到zt-1的序列,可以隐含地推断它之前的time-step x1到xt-1的序列。噪声输入序列可以在给定zt的情况下并行输出所有xt。下面的图片会让事情变得更加清晰(注意改变记谱法)。
在逆自回归流中,可以并行计算不同时间步的输出,因为时间步的输出不依赖于先前时间步的输出
太棒啦! IAF具有快速推理方案(甚至可以并行计算条件概率),但它们训练较慢。为什么比较慢呢?因为如果你给我们一个新的数据点并要求评估密度,我们需要恢复u,这个过程固有的顺序很慢。 Parallel WaveNet利用这一事实,提出了使用简单的WaveNet(教师WaveNet)培训IAF(学生WaveNet)的概念。
并行. 更快. WaveNet.
与WaveNet差不多,我们的想法是利用IAF具有快速推理方案的特性。因此,在第一阶段,我们训练出一个简单的WaveNet模型(我们称之为教师培训)。在第二阶段,我们冻结教师WaveNet的权重,并利用它来训练IAF(Student Distillation)。我们的想法是先从z~Logistic(0,I)中抽取一个随机样本,然后以并行方式传递给IAF。这将为我们提供转换分布和相关条件概率的要点。我们的想法是通过简单的教师WaveNet将这一点转换为转换后的分布,这将产生关于已经训练过的教师WaveNet的条件概率。然后我们尝试最小化从任一模型接收的条件概率之间的KL-差异。这将允许IAF(学生WaveNet)学习与其教师几乎相似的概率分布,并且结果验证了这一事实,因为从教师和学生WaveNet收到的输出之间的5级MOS分数几乎可以忽略不计。
Parallel WaveNet的培训程序
部署的速度是否足够快?是的。实际上,它能够以比实时快20倍的速度生成语音样本。但是仍然存在一个问题,每当我们需要重新训练我们的模型时,我们首先会训练WaveNet教师然后训练学生WaveNet。此外,学生WaveNet的表现在很大程度上取决于教师WaveNet的培训情况。但总的来说,进行部署是件好事。
“理论是廉价的,请给我代码。(实践出真知)”
在网上有许多的关于简单的WaveNet的实践可以使用,但是关于并行实践目前还没有找到。
1.Keras实践
2.PyTorch实践
3.TensorFlow实践(这是目前网上可被使用的实践中被引用借鉴最多的)
参考文献:
Audio Companding.
Convolutional Layers in NLP tasks.
Dilated Convolutions.
Normalising Flows: Tutorial by Eric Jang - Part 1, Part 2. Variational Inference with Normalizing Flows (Paper).
Deep Voice: Real-time Neural Text-to-Speech (Paper): Appendix is pretty useful to understand WaveNet.
WaveNet: A generative model for raw audio (Paper).
Parallel WaveNet: Fast High-Fidelity Speech Synthesis (Paper).
PixelCNN, Wavenet & Variational Autoencoders — Santiago Pascual — UPC 2017.
一文带你读懂 WaveNet:谷歌助手的声音合成器
本文为 AI 研习社编译的技术博客,原标题 : WaveNet: Google Assistant’















打开APP阅读更多精彩内容