
在介绍学习情况前,先通报一个不幸的消息,一建安装考试挂了两科(法规和实务),心情格外沉重。以现在一建出题的规律而言,专业性大幅度提高。非专业人员考试成功的概率,进一步下降。但上了贼船也只有继续考到底。下面说说今天的正题——scrapy框架:
一、scrapy框架
1、在网上找了个别人的框架图,觉得不错,拿过来用用。
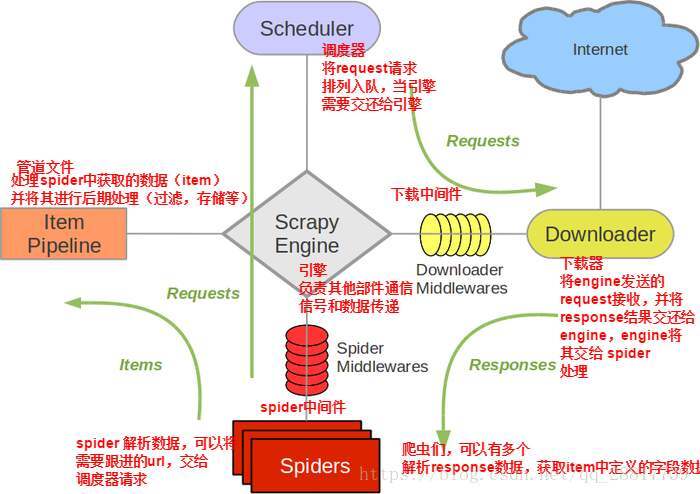
2、scrapy框架文件结构
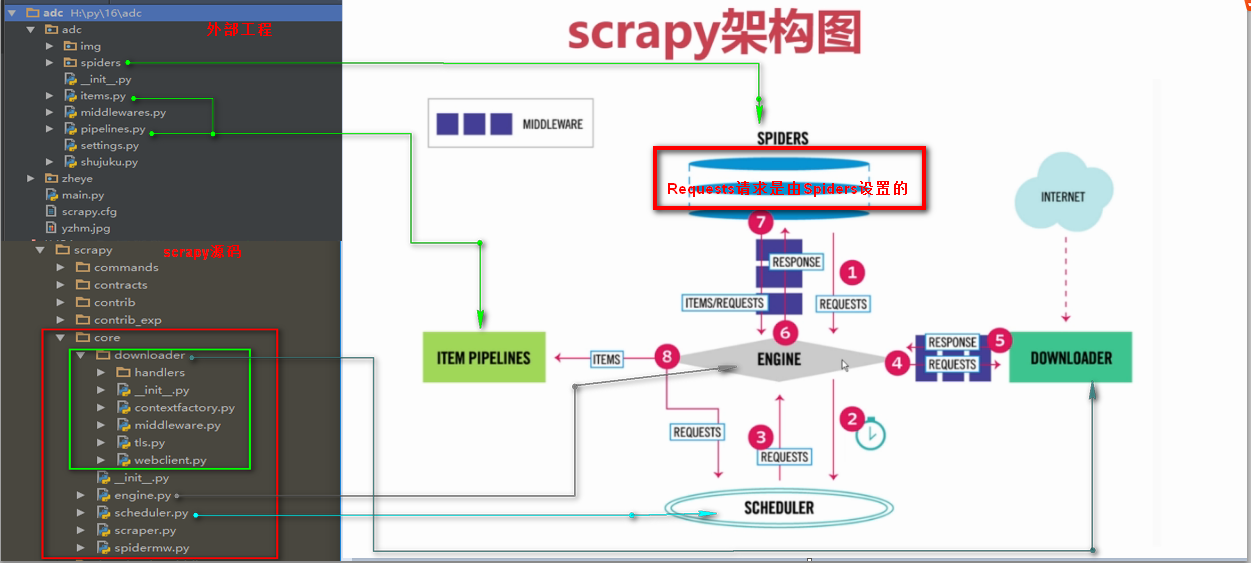
scrapy.cfg: 项目的配置文件
items.py: 项目中的item文件.(这是创建容器的地方,爬取的信息分别放到不同容器里)
pipelines.py: 项目中的pipelines文件.
middlewares.py:中间件文件,博大精深,后面会做点介绍。
spider.py:爬虫代码文件。
setting.py:配置文件。
二、环境安装
在anaconda环境管理中,找到scrapy安装包,点击APPLY就可以安装。
如果,怎么顺利,就不需要讨论了。 anaconda因为版权的问题,无法使用清华、中科大等国内镜像。
解决方法:
1、找到用户文件夹下的.condarc文件,用记事本打开,删掉原来的内容,录入以下内容:
channels:
- defaults
ssl_verify: true
2、打开SS工具,选择国外的代理,就可以下载成功。

三、创建一个项目
1、打开 anaconda prompt命令行输入:scrapy startproject binger,binger是我的项目名。许多博主都是这样写的,但我做了点改变,将binger建立到其他盘符以下,以应对我C盘告警的危险。

2、启动这个项目的命令:
scrapy crawl mybinger
scrapy crawl mybinger -o ee.json(将爬取结果输出到ee.json,这个东西应该有用,可以考虑以后和KETTLE结合起来)
需要说明的情况:
遇到提示unknow command :crawl时,发现scrapy的命令参数中就没有crawl。这不是你环境有问题,而是你没有找到正确的路径,一定要到有settings.py文件的路径下,执行以上命令。

四、初步使用scrapy
1、需求描述
爬取体彩大乐透的彩票数据。(开奖时间和中奖号码)
连接:https://chart.lottery.gov.cn/chart_tc2/chart.shtml?LotID=23529&ChartID=3&_StatType=1&MinIssue=&MaxIssue=&IssueTop=30&ChartType=0¶m=0&tab=3
这个页面是个动态页面,中间的图表是利用JS代码生成的。无法直接抓取。

2、需要的辅助工具
1)selenium
selenium的下载属于难度颇大的事情,pip在线安装基本上放弃,挂SS去下载都经常断掉。我使用的是selenium-3.141.0-py2.py3-none-any.whl和urllib3-1.25.7-py2.py3-none-any.whl。并且下载了chromedriver.exe放在项目文件中。
2)Chrome浏览器
Chrome浏览器可以对页面元素的xpath进行查询。经测试其xpath规则与scrapy的xpath规则相当融合。

只需要在复制出来的“//*[@id="content"]/tr[3]/td[3]”上,加上“/text()”,就是元素的值,不加会有一对标签。
3、代码实现
1)利用DOWNLOADER_MIDDLEWARES对网页预处理
DOWNLOADER_MIDDLEWARES就是在middlewares.py中定义的一个类,说来奇怪,在 middlewares.py中默认定义中没有,却有个SPIDER_MIDDLEWARES类。我当时就被这两个类搞糊涂了。误在SPIDER_MIDDLEWARES中重新定义了process_start_requests,导致系统老是报错“'HtmlResponse' object has no attribute 'dont_filter'”。为了解决这个问题,我是反复查阅各个网站,还遇到一个,要我参加培训班,才告诉我为什么的主。
要使用DOWNLOADER_MIDDLEWARES,就需要在“settings.py”中定义以下内容:
DOWNLOADER_MIDDLEWARES = {
'binger.middlewares.BingerloaderMiddleware': 543,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,}
middlewares.py实现代码:
from scrapy import signals
import scrapy
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
class BingerloaderMiddleware(object):
@classmethod
def process_request(self, request, spider):
f = open('f:/log.txt', 'a', encoding='utf-8')
f.write('process_request')
chrome_options = Options()
chrome_options.add_argument('--headless') # 使用无头谷歌浏览器模式
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--no-sandbox')
# 指定谷歌浏览器路径
self.driver = webdriver.Chrome(chrome_options=chrome_options,executable_path='F://scrapy_file//chromedriver.exe')
f.write("URL:"+request.url+"")
self.driver.get(request.url)
time.sleep(2)
html = self.driver.page_source
#f.write('Context:')
#f.write(html+"")
self.driver.quit()
f.close()
return scrapy.http.HtmlResponse(url=request.url,body=html.encode('utf-8'), encoding='utf-8',request=request)
2)爬取数据(spider.py)
import scrapy
from binger.items import BingerItem
class BingerSpider(scrapy.Spider):
name = "mybinger"
allowed_domains = ["www.lottery.gov.cn"]
start_urls = ['https://chart.lottery.gov.cn/chart_tc2/chart.shtml?LotID=23529&ChartID=3&_StatType=1&MinIssue=&MaxIssue=&IssueTop=30&ChartType=0¶m=0&tab=3']
def parse(self, response):
item = BingerItem()
f = open('f:/log.txt', 'a', encoding='utf-8')
row = 3
date = []
boll = []
for row in range(3,37):
path1 = '//*[@id="content"]/tr[' + str(row) + ']/td[1]/text()'
path2 = '//*[@id="content"]/tr[' + str(row) + ']/td[3]/text()'
f.write(path1+"")
f.write(path2+"")
t1 = str(response.xpath(path1).extract())
t2 = str(response.xpath(path2).extract())
date.append(t1)
boll.append(t2)
f.write(t1+"")
f.write(t2+"")
item['date'] = date
item['boll'] = boll
f.write("抓取完成")
f.close()
return item
3)容器定义(items.py)
import scrapy
class BingerItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
boll = scrapy.Field()
date = scrapy.Field()
pass
4)数据持久化pipelines.py
import json
class BingerPipeline(object):
def __init__(self):
self.file = codecs.open('f:/test.txt', "a", encoding="utf-8")
def process_item(self, item, spider):
boll = item["boll"]
date = item["date"]
line ='输出:'+ ''.join(date) + ',' +''.join(boll)+""
self.file.write(line)
f = open('f:/log.txt', 'a', encoding='utf-8')
f.write("持久化处理完成")
f.close()
return item
def close_spider(self, spider):
self.file.close()