

字幕组双语原文:抗拼写错误的词向量
英语原文:New Model for Word Embeddings which are Resilient to Misspellings (MOE)
翻译:雷锋字幕组(wiige)
传统的词嵌入擅长处理大部分自然语言处理(NLP)领域的下游问题,比如文档分类和命名实体识别(NER)。然而它的一个缺点是无法处理未登录词(OOV)。
Facebook通过引入错字遗忘(词)嵌入(MOE)克服了这一缺陷。MOE通过扩展fastText架构来处理未登录词。因此介绍MOE之前,先介绍一下fastText的训练方法和架构。
负采样Skip-gram(SGNS)
fastText扩展了word2vec的架构,使用负采样skip-gram来训练词嵌入。Skip-gram使用当前词来预测周围的词,得到文本表示(即嵌入 )。负采样是一种挑出假例(false case)来训练模型的方法。你可以查看这些文章(skip-gram和负采样)了解更详细的内容。
下图显示了两种训练word2vec词向量的方法。连续词袋(BOW)利用上下文来预测当前词,而Skip-gram则利用当前词来预测上下文。
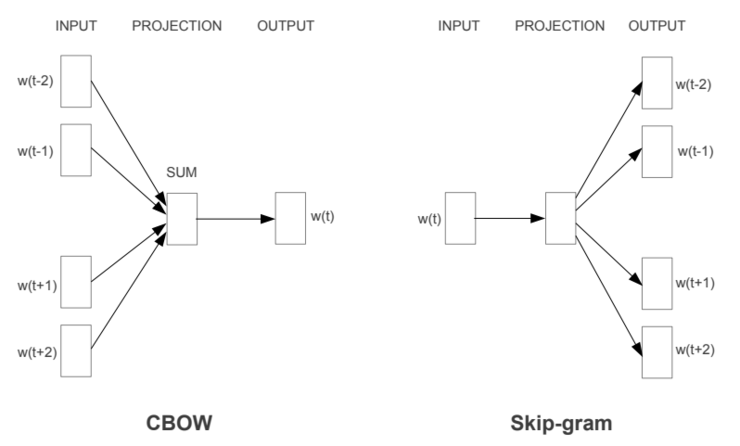
矢量空间中词表征的效用估计(Tomas et al.,2013)
fastText
fastText几乎全盘沿用了SGNS的思想。fastText特征之一是子字(subword), 一般用N-gram方法将单词分割成子字。例如,n-gram字符数是3到5之间。这样就可以将banana拆分为ban、ana、nan、bana、anan、nana、banan、anana。这样,香蕉(banana)的词嵌入就是这些子词的嵌入之和。
fastText的训练目标是对标签进行分类。模型输入是n-gram特征(即x1,x2, ......, xN)。这些特征将在隐藏层中被平均化最后送入输出层。

fastText的架构 (Joulin et al., 2016)
错字遗忘(词)嵌入 (MOE)
MOE通过引入拼写校正损失进一步扩展了fastText。引入拼写校正损失的目的是将错误拼写的词嵌入映射到其接近的正确拼写的词嵌入上。拼写校正损失函数是一个典型的logistic函数, 它是正确词子字输入向量和与错误词的子字输入向量和的点积。
下面展示了bird(正确单词)和bwrd(拼写错误的单词)的词嵌入是非常接近的。

MOE(facebook)的表示方法
Take Away
子词是处理拼写错误和未登录词的有力方法。MOE使用字符n-gram来建立子字词典,而其他的先进NLP模型(如BERT,GPT-2)则使用统计方式(如WordPiece,Byte Pair Encoding)来建立子词典。
在许多NLP系统中,能够处理未登录词是一个关键的优势。比如聊天机器人每当拼写错误或新词时,都必须为之处理大量的新OOV词。
雷锋字幕组是由AI爱好者组成的志愿者翻译团队;团队成员有大数据专家、算法工程师、图像处理工程师、产品经理、产品运营、IT咨询人、在校师生;志愿者们来自IBM、AVL、Adobe、阿里、百度等知名企业,北大、清华、港大、中科院、南卡罗莱纳大学、早稻田大学等海内外高校研究所。