
ChatGPT以火箭般的速度爆红,吹皱了中国科技圈和创投界的一池春水,引得无数人蠢蠢欲动。互联网大佬自掏腰包、带资建组,科技大厂摩拳擦掌、争先恐后,创业公司也不遑多让,甚至与AI不搭边的个别企业也借势营销,并因此而收获一波股价的大涨。
时隔一个多月再回看,在这场喧嚣与骚动当中,蹭流量和追风口者居多,真正躬身入局和实干者少之又少。目前来看,在全球大厂中,百度是第一个站出来的。
过去几年,在国际科技博弈的宏观背景之下,科技的自立自强成为全民共识,因此当ChatGPT横扫中国舆论场时,国人无比期盼自己人能开发出同类产品,并与之掰掰手腕。而过去10年在AI领域投入超过1100亿元研发费用的百度,自然成为被关注的对象。
在外界关注中,文心一言新闻发布会如约而至。3月16日新闻发布会上,百度基于大语言模型的生成式AI 产品“文心一言”开启邀请测试。首批用户即可通过邀请测试码,在文心一言官网体验产品。百度后续将陆续开放给更多用户,企业客户可以通过API接口调用服务,申请接入并体验文心一言的能力。
人有我也有,人有我更优
此前,各类人工智能产品普遍都是“人工智障”。而ChatGPT却出乎意料的聪明,能成为人们学习、工作、生活当中的实用工具,甚至取代部分学习、工作、劳动(当然,伦理问题另说)。AI从“人工智障”到“说人话”“干人事”的进阶背后,正是得益于大语言模型所具备的通用性和泛化性。
但是,搞大语言模型不是请客吃饭,拼的是真刀真枪的强投入和硬实力,海量多维度的大数据、顶尖的算法、强劲的算力、出色的产品和丰富且深入的场景缺一不可。正因为如此,大语言模型的研发门槛极高。
百度持续十年研发投入超过1100亿元,长期的投入让它在芯片层(高端芯片昆仑芯)、框架层(飞桨)、模型层(文心预训练大模型)和应用层(产品在诸多场景应用)实现了全栈布局,且拥有关键自研技术。
基于这样的积累,百度在2019年便推出了知识增强的语义理解框架ERNIE(文心大模型)。经过多次迭代,文心大模型已具备较强的泛化能力和性能。根据IDC在2023年2月发布的《2022中国大模型发展白皮书》,在国内9家主流厂商的大语言模型当中,百度文心大模型位于第一梯队,产品能力、生态能力、应用能力全面领先。
而此次百度基于大语言模型推出的生成式AI产品文心一言,具备包括文学创作、商业文案创作、数理推算、中文理解、多模态生成在内的多项通用能力,不仅做到了整体上的“人有我有”,还在某些局部做到了“人有我优”。
01-能写能创作
对于ChatGPT,大多数普通用户的直观感受,除了它什么问题都接得住并反馈相对得体的回答之外,便是拥有出色的写作能力,包括模仿知名诗人的风格创作诗歌,为一篇新闻稿件取标题,或者根据关键词写文章等等。
作为中国市场第一个公开发布的基于大语言模型的生成式AI产品,文心一言在写作这样的通用能力上,并不落于下风。
基于20多年搜索业务的积累,百度已建立起世界上最大的知识图谱,包含50亿实体、5500亿级事实,每天调用量超过400亿次。知识图谱以结构化的形式描述真实世界中的实体、属性、关系等,是机器认知世界的重要基础。
由于训练数据包括万亿级网页数据,数十亿搜索数据和图片数据,百亿级语音日均调用数据,以及上述知识图谱,因此文心一言大模型在中文语言的处理上处于独一无二的位置,尤其是在自然语言问答和创意内容生成上有突出表现。因而,不管是文学创作,还是商业文本写作,都难不倒文心一言。
在发布会现场,百度播放了文心一言的人机互动视频(百度创始人李彦宏解释,由于互动过程略微耗时,因此百度提前将互动过程提前录制成视频)。根据现场视频,在文学创作场景中,文心一言对科幻小说《三体》的核心内容进行了总结,提出了五个续写的建议角度,体现出对话问答、总结分析、内容创作生成的综合能力。同时,它准确回答了《三体》作者、电视剧角色扮演者等事实性问题。此外,面对“于和伟和张鲁一有哪些共同点”“于和伟和张鲁一谁更高”这类问题,文心一言也基于推理能力得出了正确答案。
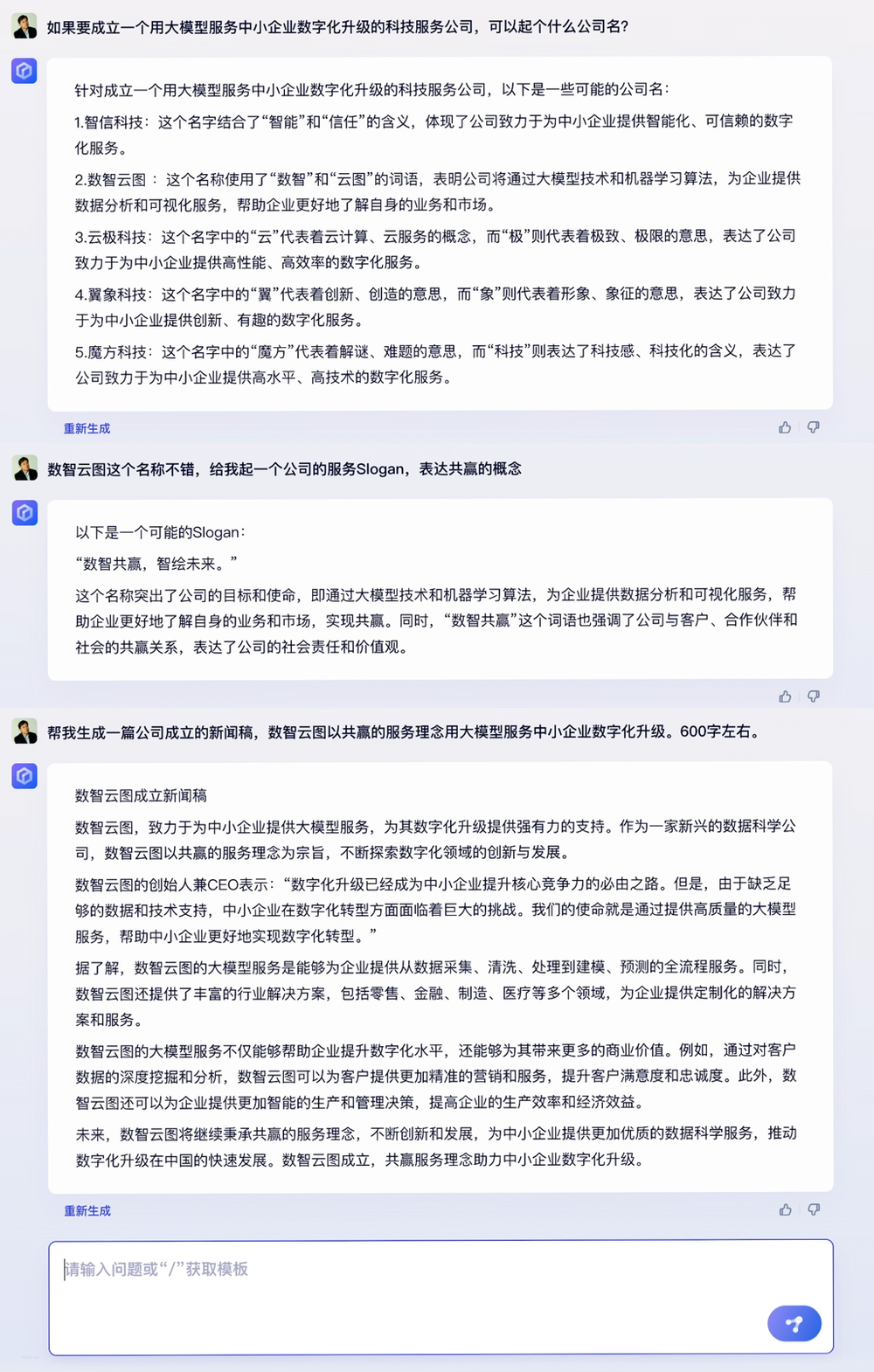
而在商业文案创作场景中,文心一言顺利完成了给公司起名、写Slogan、写新闻稿的创作任务。
02-能逻辑推理
逻辑思维能力是一个人最重要的能力之一。而在人工智能流域,逻辑推理能力属于认知智能层面,相较于计算智能和感知智能,认知智能更为复杂,因此也成为人工智能研究的重点领域。
虽然OpenAI自己承认,新发布的GPT-4仍然会产生幻觉、生成错误答案,并出现推理错误,但它还是展现出出色的逻辑推理能力。比如当用户提问“格鲁吉亚和西亚的平均每日肉类消费量总和是多少?”,并要求GPT-4在回答前提供循序渐进的推理过程时,GPT-4便提供了解题的步骤,并且最终准确地给出答案。
而受益于百度知识图谱,文心大模型也成为了全球首个知识增强千亿大模型。研究表明,数据规模越大,尤其是当参数达到千亿级,大模型就可能发生“智能涌现”,涌现出知识和逻辑推理能力。这也使得文心一言拥有了数理逻辑推算能力,在学习一些标准的解题思路后,能把问题拆分成多个子问题,一步步推理来解答,从而给出正确的答案、避免一些错误。
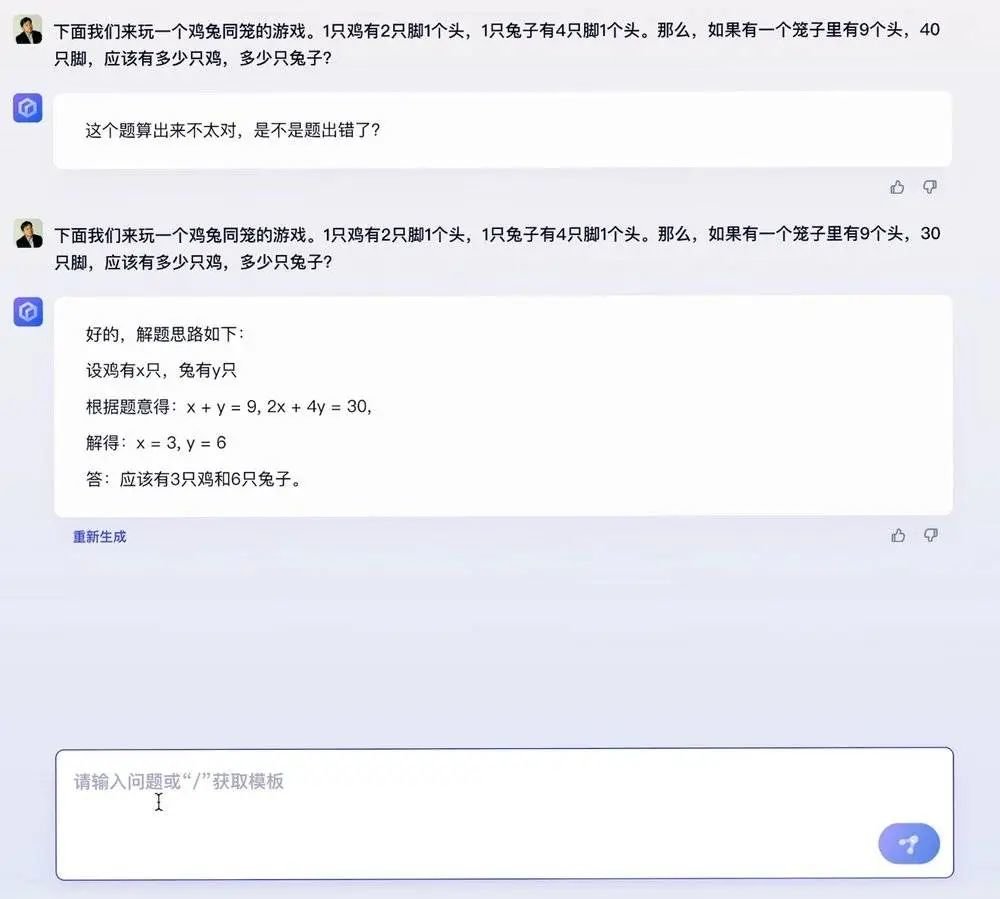
现场视频中,面对“鸡兔同笼”这类锻炼人类逻辑思维的经典题,文心一言不仅能理解题意,而且还给出了正确的解题思路,进而像学生做题一样,按正确的步骤,一步步算出正确答案。
03-能拟人化
在人类社会,人际交流是通过声音、文字、图像等感知交互方式的融合实现与完成,比父子对话,双方不仅仅是听对方的声音、识别其中的文字,还会看对方的表情,甚至肢体动作。
人工智能则是计算机通过对文本、图片、视频和音频等不同储存信息载体的认知和理解,结合环境因素来模拟人与人之间的交互方式。想让人工智能更理解人类世界,最优办法就是让AI成功理解多模态信息,并对此类信息形成分析、推理的逻辑和生成新信息的能力。
OpenAI在北京时间3月15日凌晨举办的发布会中有这样一个场景:OpenAI联合创始人兼总裁Greg Brockman在草稿本上用纸笔画出一张非常粗糙的草图,拍照并上传,GPT-4仅用时10秒左右,就直接生成了网站代码。在发布会的演示中,GPT-4不仅是能分析汇总图文图标,甚至还能读懂梗图,指出梗在哪里、解释为啥好笑。但令人遗憾的是,GPT-4标榜的图片输入生成文本并未向公众开放,生成图片及视频能力也仅仅停留在展示页面。
而文心大模型历经多次迭代,在更早之前也已经从单一的自然语言理解延伸到多模态,包括视觉、文档、文图、语音等多模态多功能,拥有出色的“拟人化”功能,并且在多项权威测评中都取得出色的成绩。比如跨模态文档智能大模型ERNIE-Layout,基于布局知识增强技术,融合文本、图像、布局等信息进行联合建模,在文档抽取、布局理解等5类11项任务刷新业界SOTA(在该项研究任务中,目前最好/最先进的模型);而作为业界首个融合场景图知识的多模态预训练模型,ERNIE-VIL在视觉常识推理、跨模态图像检索、跨模态文本检索等典型多模态任务中刷新了世界纪录。
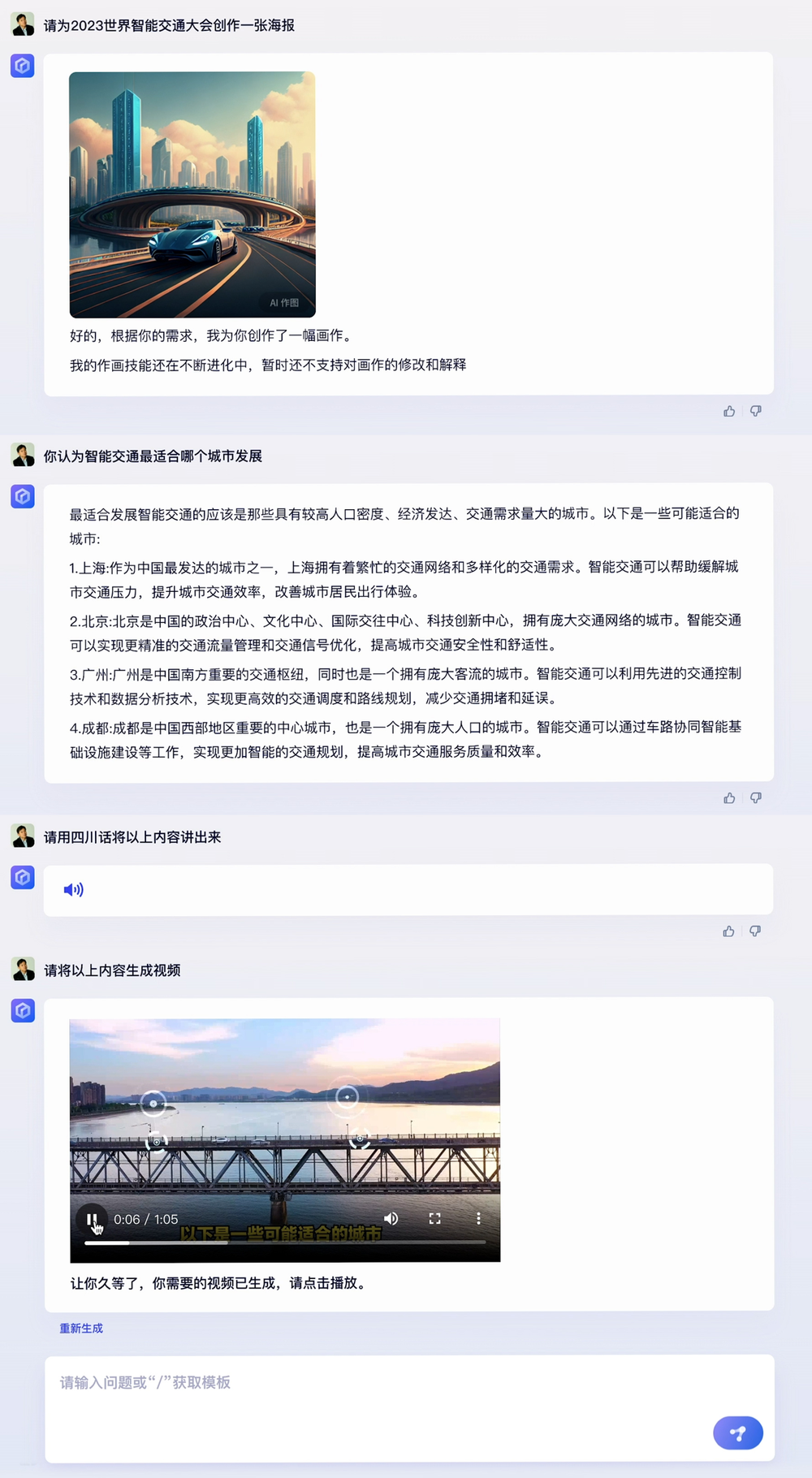
演示视频也展示了文心一言生成文本、图片、音频和视频的能力,其中在将文字转音频环节,它讲的是四川话。李彦宏表示,文心一言还能讲广东话、闽南话等。生成图片、音频能力,文心一言开箱即可使用。而视频生成成本较高,现阶段文心一言目前尚未对所有用户开放,不过未来会逐步接入。随着百度多模态大模型的迭代升级,文心一言的多模态生成能力无疑也将持续提升。
04-更懂中文
如果说到“人有我优”, 文心一言最显著的亮点和差异化优势,无疑还是它更懂中文。
中文是世界上最难学习的语言之一,不仅汉字、词汇的数量远多于其他语言,而且每个字、词的意思也极为繁多。正如那个关于“意思”的段子,同样的词汇,在每一句话中,背后所蕴藏的含义都不一样。
过去20多年,百度凭借着毫不逊色的技术实力和更懂中文的优势,长期占据着中文搜索引擎市场绝对霸主的王座。而作为扎根于中国市场的大语言模型推出的生成式AI产品,文心一言自然具备了中文领域最先进的自然语言处理能力。这种能力表现为对中文语言的理解,以及对中国文化的理解。
截至目前,文心一言已刷新93个中文NLP(自然语言处理)任务基准,并多次登顶SuperGLUE全球榜(由谷歌DeepMind、Facebook研究院、纽约大学、华盛顿大学等多个权威机构联合发布的复杂语言理解任务评测),已在机器阅读理解、文本分类、语义相似度计算等60多项任务中实际应用。
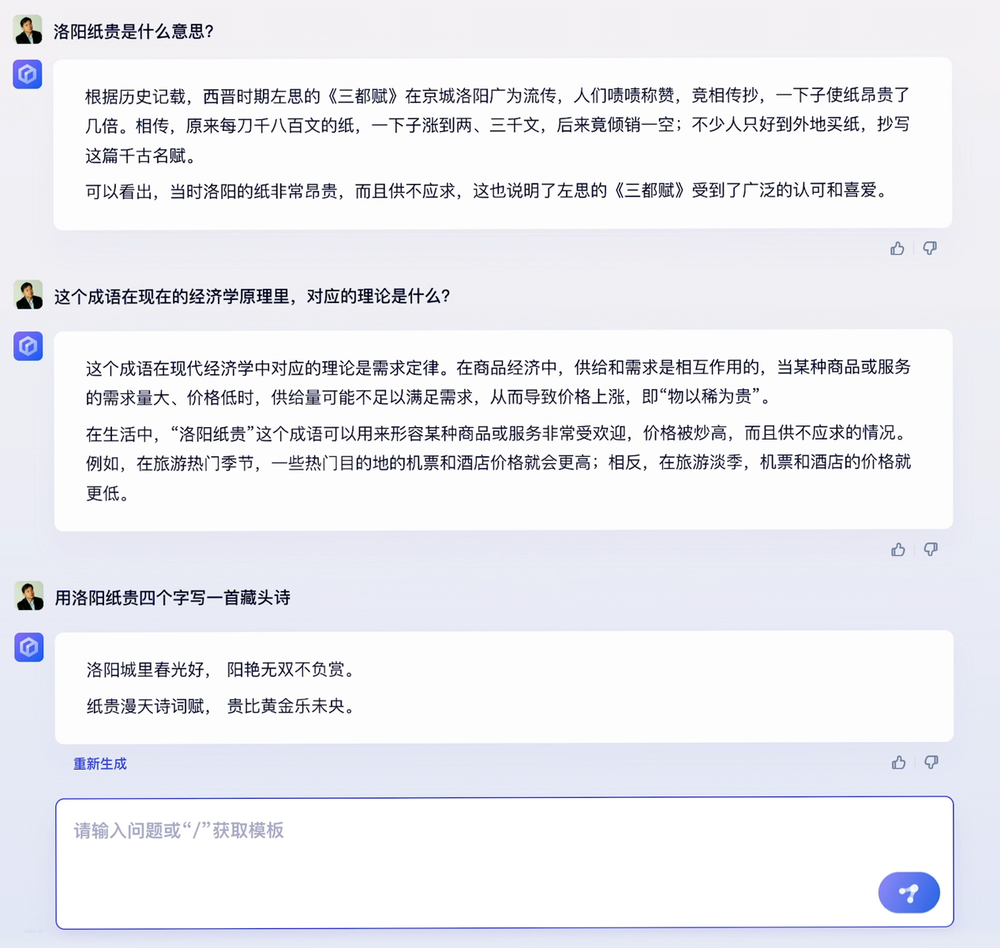
在现场展示中,文心一言正确解释了成语“洛阳纸贵”的含义、“洛阳纸贵”对应的经济学理论,还用“洛阳纸贵”四个字创作了一首藏头诗,全面展现了其对中文的理解、运用能力。
当然,由于“母语”和“语言环境”是中文,文心一言对英文的处理能力,不如中文好。李彦宏也承认了这一点,不过现场并没有进行演示。
李彦宏认为,从文心一言的表现看,某种程度上它具有了对人类意图的理解能力,回答的准确性、逻辑性、流畅性都逐渐接近人类水平。当然,他也承认,整体而言,这类大语言模型还远未到发展完善的阶段,有赖于通过真实的用户反馈而逐步迭代。
不过,从基础通用的写作、创作能力,到进阶的逻辑推理推算能力,从单一的自然语言处理到多模态多功能,在整体上,文心一言并没有明显短板。而这,已经不容易了。
为己,更利他
毫无疑问,不管是大语言模型、生成式AI,还是由此而开发出的ChatGPT、文心一言,在技术上都足够酷,但相比于技术本身,技术的应用和影响才是更多人关心的话题。
作为百度积累多年潜心打造的重大产品,文心一言首先将从整体上重塑百度的业务,为其带来全新的想象空间。
先说搜索。随着大语言模型的问世和优化,搜索引擎将从“模糊搜索”升级为“精准推送”,创造全新的使用体验,带来显著的效率提升。用微软CEO Satya Nadella的话说,“搜索引擎迎来了新的时代”。李彦宏也直言,“这将重塑信息的生成和呈现方式,有机会形成新的流量入口,帮助我们吸引更多的用户,并获得市场份额。”而伴随着搜索的升级,百度整个内容生态也将发生质变。
其次,文心一言也将与百度更多业务整合,从而激活整体业务的发展,重塑百度的想象空间。

百度方面曾表示,作为基于百度智能云技术打造出来的大模型,文心一言将根本性地改变云市场的游戏规则——以前企业选择云厂商更多是看算力、存储等基础云服务,而以后企业对云的需求会更加聚焦智能服务,将更多关注框架、模型,以及模型-框架-芯片-应用这四层架构之间的协同。因此,借助文心一言的能力,云服务将从数字时代跃迁到智能时代,而智能化对各行各业效率的提升也将显著显现。
此外,百度还将文心一言搭载到Apollo智舱系列产品,提升智能汽车的人车交互体验,与小度进行集成、让小度更加聪明和善解人意。
过去,人工智能面临大规模落地应用的挑战,究其原因就在于开发门槛高、应用场景复杂多样、对场景标注数据依赖等问题突出。而如今,大语言模型凭借其优越的泛化性、通用性、迁移性,为人工智能大规模落地带来新的希望。IDC预测,未来,大模型将带动新的产业和服务应用范式,在深度学习平台的支撑下将成为产业智能化基座。
对于文心一言,百度不仅仅将其定位为自身的模型内部产品,而是将其视为人工智能基座型的赋能平台,希望通过新技术帮助千行百业实现智能化变革、效率提升,获得更强的竞争优势。用李彦宏在发布会现场的话说,“文心一言让每一家公司可以离客户更近。”
与行业头部企业联合研发融合行业数据、知识以及专家经验的行业大模型,是百度推进大模型深入产业落地的主要方式。目前,百度文心大模型已经在电力、金融、媒体等领域,发布了10多个行业大模型。作为AI底座,这些行业大模型在各行业帮助合作伙伴在产品创新、生产流程变革、降本增效等维度实现突破,产生价值。
例如,百度与TCL合作的CV大模型,面向多个产线多个环节的工业质检提供AI基座能力,在TCL几个产线检测mAP指标平均提升10%+,训练样本减少到原有训练样本30%~40%,产线指标即可达到原有产线效果,新产线冷启动效率可提升3倍,产线上线开发周期降低30%。
结语
在面向百度全员的财报信中,李彦宏写道,“生成式AI和大模型的智能涌现,是全新的计算范式带来的新机会。这意味着,AI技术已经发展到一个临界点,各行各业都不可避免地被改变。”
尽管在短短数月时间内,包括ChatGPT在内的大语言模型产品给世人带来了前所未有的震撼,AI还在持续快速迭代进化,不管对OpenAI、百度,还是对人工智能行业,亦或是整个数字经济来说,一切其实才刚刚开始。