

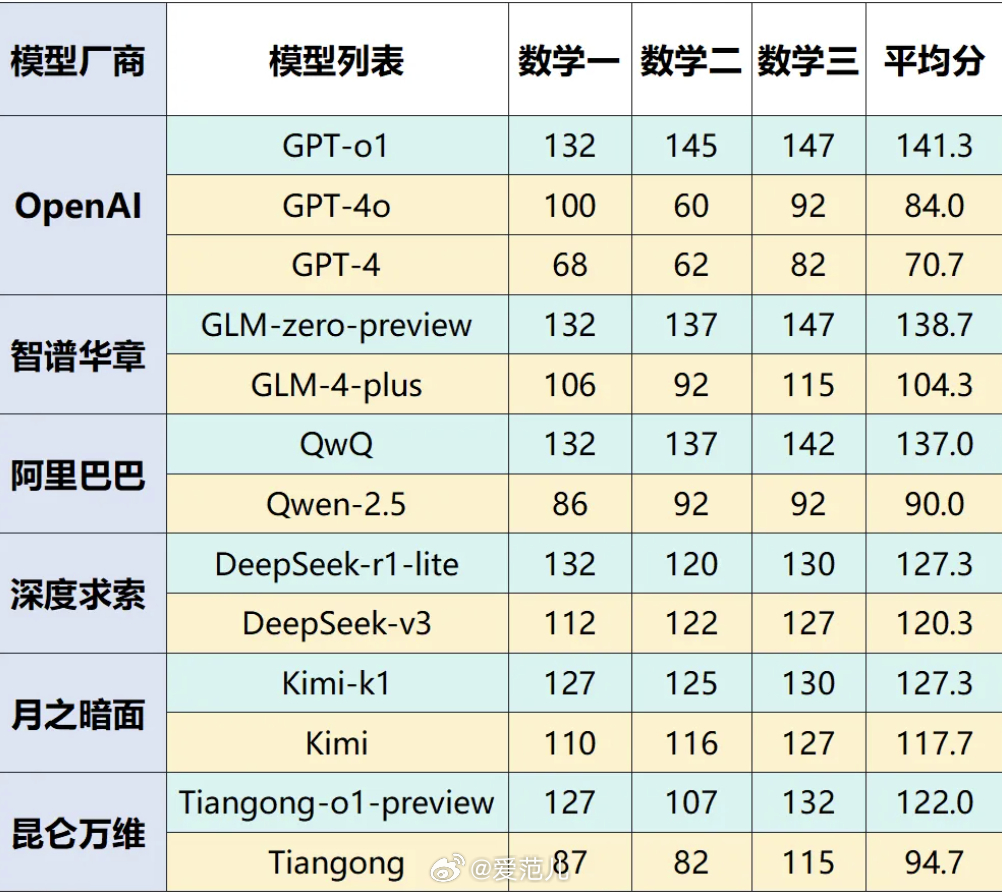
机构:GPT-o1 在深度思考模型测试中成绩领先
1 月 13 日,THU 基础模型公众号发布推文,公开了对各家旗舰基础模型进行测试的结果。
官方表示,为了全面评估这些模型在数学推理方面的能力,他们结合2025年考研数学(一、二、三)的试题,对各家深度推理模型进行了严格的评测。
此外,为了确保评测的全面性,他们对各家的旗舰基础模型进行了也同样的测试。此次测试,他们从六家厂商中,选择了 13 个模型。
测试结果显示,GPT-o1 仍然处于领先的地位,是唯一一个达到 140 分以上的模型,相较于排名末位的 GPT-4,分数优势高达 70 分。位于第二梯队(130 分以上)的模型有 GLM-zero-preview和 QwQ,分别斩获 138.7 分和 137.0 分;DeepSeek-r1-lite、Kimi-k1、Tiangong-o1-preview、DeepSeek-v3 则处于第三梯队(120 分以上)。
另外,官方表示,在缺乏深度思考能力辅助的情况下,仅凭逻辑推理能力,DeepSeek-v3 作为基础模型,已经能够跻身第三梯队,这说明基础模型和深度思考模型之间的能力并非界限分明。