

在最近的一篇论文中,来自字节跳动、北京大学等机构的研究者提出了 Sa2VA。市面上第一个结合 SAM-2 和 LLaVA-like 的视频多模态大模型,结合了 SAM-2 和 LLaVA 的优势,实现了时空细粒度的理解。

GitHub 地址:https://github.com/magic-research/Sa2VA
具体来说,研究者设计了一套统一的指令微调格式 (Instruction Tuning Pipeline),整合了五种不同的任务,超过 20 个数据集一起进行联合训练。该模型在多个视频理解和图像理解,视频指代分割和图像指代分割的任务上均取得了领先的效果。

图 1 Sa2VA 的能力。(a) 给定一个视频, Sa2VA 能够分割所指的对象并理解整个场景。(b) Sa2VA 在单词指令追随训练的情况下,支持图像对话、视频对话、图像引用分割、视频引用分割以及物体描述生成。(c) 与现有的 MLLM(例如 GLaMM 和 OMG-LLaVA)相比,Sa2VA 在多图像、视频引用分割和对话上取得了较好的表现(相比于之前的方法,我们的 model 可以在多个不同的视频和图像多模态任务上取得领先效果。)。
研究背景和动机
近年来,多模态大语言模型有了很大的进展。多模态大语言模型现在支持图像对话、视频对话、图像分析等多种任务。这些模型整合不同模态的数据,展现了强大的泛化能力和应用潜力。在实际应用中,多模态大语言模型已经能够实现图像或视频级别的各种复杂任务。通过人类输入各种不同的指令,这些模型能够根据具体任务生成精准的响应。例如,在视频对话任务中,多模态大语言模型可以识别图像中的关键要素,回答有关物体、场景的问题。
在这些应用中,我们主要关注细粒度的图像和视频理解。也就是给出自然语言或者视觉的指令,让大语言模型输出用户关注的细粒度内容。这样人类就可以在视频播放的过程中和多模态大语言模型进行交互,而不是仅仅输出一般的结果。然而,现有的感知模型或者多模态大语言模型都没有办法很好的完成这个任务。感知模型缺乏开放世界的自然语言推理能力。例如 SAM-2 可以很好的从视觉提示出发对物体进行分割,但无法对物体就行描述。而多模态大语言模型往往缺乏感知能力,尤其是缺乏视频的分割能力。本工作旨在利用两者的优势构建一个统一的支持图像、视频细粒度感知以及对话、分析等任务的模型。
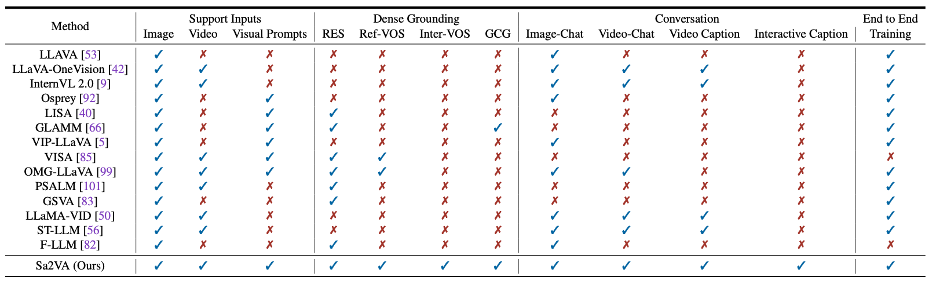
表格 1 Sa2VA 与之前模型的能力比较。Sa2VA 支持各种任务和模态。
在本工作中,我们提出了 Sa2VA,首次结合了 SAM-2 的感知能力和多模态大语言模型的推理能力来构建统一的模型,并使用新的训练数据来使得整个模型具有额外的能力。我们将各种任务整合成一个单次的指令追随训练。这些任务包括图像和视频 Referring Expression Segmentation (RES), Visual Question Answering (VQA), Grounded Conversation Generation (GCG) 等任务。我们的方法还支持视觉提示输入来指定物体。我们的核心观点是将所有的图像、视频、文字或指令输入统一成令牌而不分别进行设计。这种方式可以让 Sa2VA 支持上述所有任务的联合训练。通过单次的指令追随训练,我们的 Sa2VA 可以仅仅使用一种参数来来实现上述所有任务。
方法设计
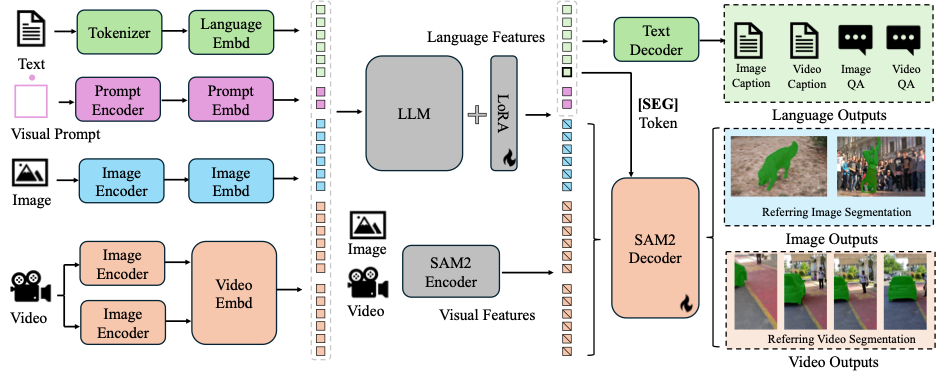
图 2 Sa2VA 的模型结构。Sa2VA 首先将输入的文本、视觉提示、图像和视频编码为令牌嵌入。然后通过大型语言模型 (LLM) 处理这些令牌。输出的文本令牌用于生成 [SEG] 令牌和相关的语言输出。SAM-2 解码器从 SAM-2 编码器接收图像和视频特征以及 [SEG] 令牌,以生成相应的图像和视频分割结果。
Sa2VA 模型具体实现
Sa2VA 主要包括两部分,第一部分是多模态大语言模型,第二部分是 SAM-2 模型。
Sa2VA 的多模态大语言模型部分使用了已经经过预训练的模型。主要包括一个视觉编码器,来对图片、视频或部分图片进行编码获得视觉特征。通过一个投影层,可以将视觉特征转换成维度和大语言模型一致的视觉令牌。这些视觉令牌和输入的自然语言令牌一起作为大语言模型的输入来进行推理。整个过程使用了和 LLaVA、Qwen 等多模态大语言模型类似的处理多模态数据的方法。
Sa2VA 使用了多模态大语言模型和分割模型分离的设计,将预训练后的 SAM-2 模型和多模态大语言模型放在一起分别处理不同的特征,而不是将 SAM-2 模型的输出送入多模态大语言模型。这种设计主要有三方面的考虑。第一,我们想让整个模型尽可能的简单,而非引入过多的计算开销。第二,如果将 SAM-2 模型的输出送入多模态语言大模型,将会引入更多的多模态大语言模型的输入令牌,意味着更多的训练开销。第三,分离的设计可以更方便的使用不同种类的基础模型,进而使得基础模型的进展可以更方便的迁移到本工作。
Sa2VA 通过微调 “[SEG]” 令牌的方式来连接多模态大语言模型和 SAM-2 模型。“[SEG]” 令牌对应的隐藏状态将作为 SAM-2 模型的一种新的提示词。这种新的提示词拥有对于时间和空间的理解。在 SAM-2 模型的解码器中,“[SEG]” 令牌对应的时空提示词可以用来生成对应的图像或者视频的分割结果。在训练的过程中 SAM-2 模型的解码器可以被微调来理解 “[SEG]” 令牌对应的提示词。与此同时,梯度也会通过 “[SEG]” 令牌对应的隐藏状态传递到大语言模型中来使得大语言模型拥有生成时空提示词的能力。
对于指代视频物体分割任务,Sa2VA 使用一个简单的框架来通过 SAM-2 的能力取得较强的跟踪和分割能力。整个过程从提取关键帧开始。我们提取整个视频中的前五帧作为关键帧。这些关键帧对应的视觉令牌作为多模态大语言模型的输入来生成 “[SEG]” 令牌。“[SEG]” 令牌对应的提示词可以直接用来生成关键帧的分割结果。使用这些分割结果,结合 SAM-2 模型中经过预训练的记忆编码器一起来生成剩余帧的分割结果。
Sa2VA 模型的训练方法
Sa2VA 将不同的任务统一成相同的表示以进行建模。
(a)对于指代图像物体分割,给定一段文本描述和图像,模型将图像转换为视觉令牌,将文本转换为文本令牌,模型最终输出分割结果。(b)对于指代视频物体分割任务,给定一段文本描述和对应的视频,模型将视频中的关键帧转换为视觉令牌,将文本转换为文本令牌,模型最终输出每一帧的分割结果。(c)对于视频和图像对话以及关联式图像文字描述生成,模型将图像或视频转换为视觉令牌,并将用户输入的文字转换为文本令牌,模型最终输出回答文本。对于关联式描述生成,模型还将输出和回答文本关联的分割结果。(d) 对于视觉提示理解任务,除了文本令牌和视觉令牌之外,模型进一步将视觉提示转换为视觉提示令牌。模型最终输出回答文本,以及对应的分割结果。
在有了对于不同任务的统一表示之后,借助于多模态大语言模型的灵活性,就可以将上述任务统一成一个单次的指令微调。多模态大语言模型将视觉将文本令牌、图像或视频的视觉令牌以及视觉提示令牌一起作为输入,就可以生成文本输出。在文本输出中的 “[SEG]” 令牌对应的提示词就可以使用 SAM-2 模型输出对应的分割结果。
Sa2VA 在多个数据集上面进行联合训练。并对不同的任务使用不同的损失函数进行监督。对于 VQA 任务,我们使用和之前多模态大语言模型相同的文本回归损失函数。对于分割任务,我们使用逐像素的交叉熵损失函数和 DICE 损失函数。由于已经使用了预训练之后的多模态大语言模型,Sa2VA 无需进行像之前工作一样的预训练阶段。
Ref-SAM-v Benchmark
此外,本文还提出了一个新的 Benchmark, Ref-SAM-2v 以及对应的训练数据集。
对于掩码数据,我们是基于 SAM2 的中的开源掩码标注,利用现有的领先的多模态大模型,去对每个跟踪后的掩码做目标级别的描述信息生成。具体的数据集生成过程,可以参考我们的论文。
此外,我们的测试 benchmark 相比于之前的 Ref-VOS 数据,更具有挑战性。具体的数值结果可以参考我们的论文。
数值结果对比
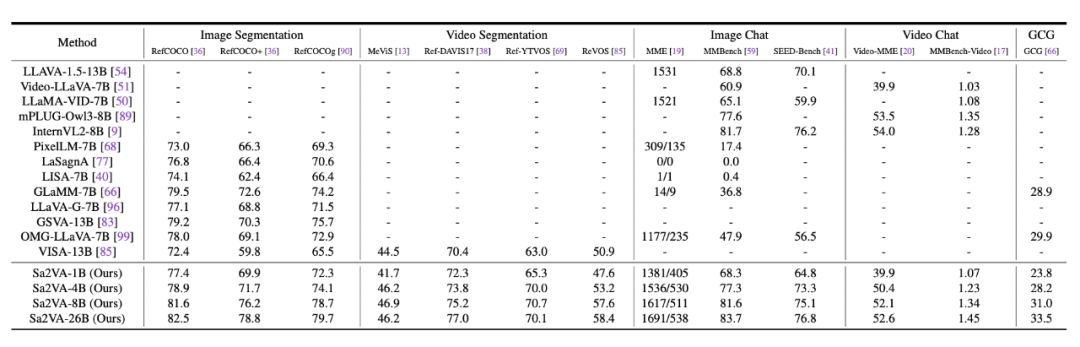
从这个表格中,可以看到,我们的方法可以在 5 个不同的任务上取得领先的结果 (13 个公开数据集)。
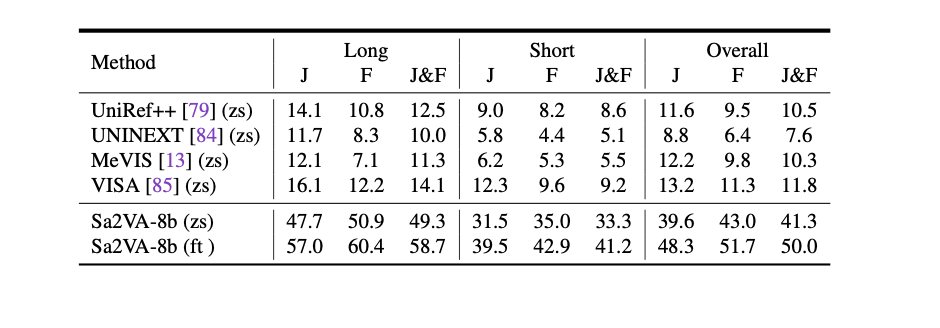
我们的方法在我们提出的 Ref-SAM-v 上也取得领先的结果,并大幅度领先现有的工作(zs 代表 zero-shot 测试)。
可视化结果展示
Sa2VA 可以实现多种任务,包括图像和视频的 caption 生成、对话、指代对象分割、GCG、视觉指代物体 caption 等,下面是一些效果展示:
GCG 任务:

图像指代分割:

视觉指令输入的理解:

视频指代分割:

开集结果测试
同时 Sa2VA 还可以很好的扩展到开放场景中,下面是一些开放场景下的电影或网络视频的效果展示。
左边是输入视频,右边是具体的结果,下侧是文字相关的回答。
1、朴彩英 APT APT MV video
Question:Please segment the person wearing sunglasses.

