


3月16日,百度正式发布了类似“ChatGPT”的生成式AI产品——文心一言,号称具有文学创作、商业文案创作、多模态生成、数理逻辑推算、中文理解等能力。
近日有网友在对百度的生成式AI——文心一言的文生图功能测试后,认为其可能只是一个套壳的AI模型,因为其反馈逻辑是先将用户的中文指令翻译成英文然后再根据英文理解的中文意思进行生成。
比如下面几个例子:
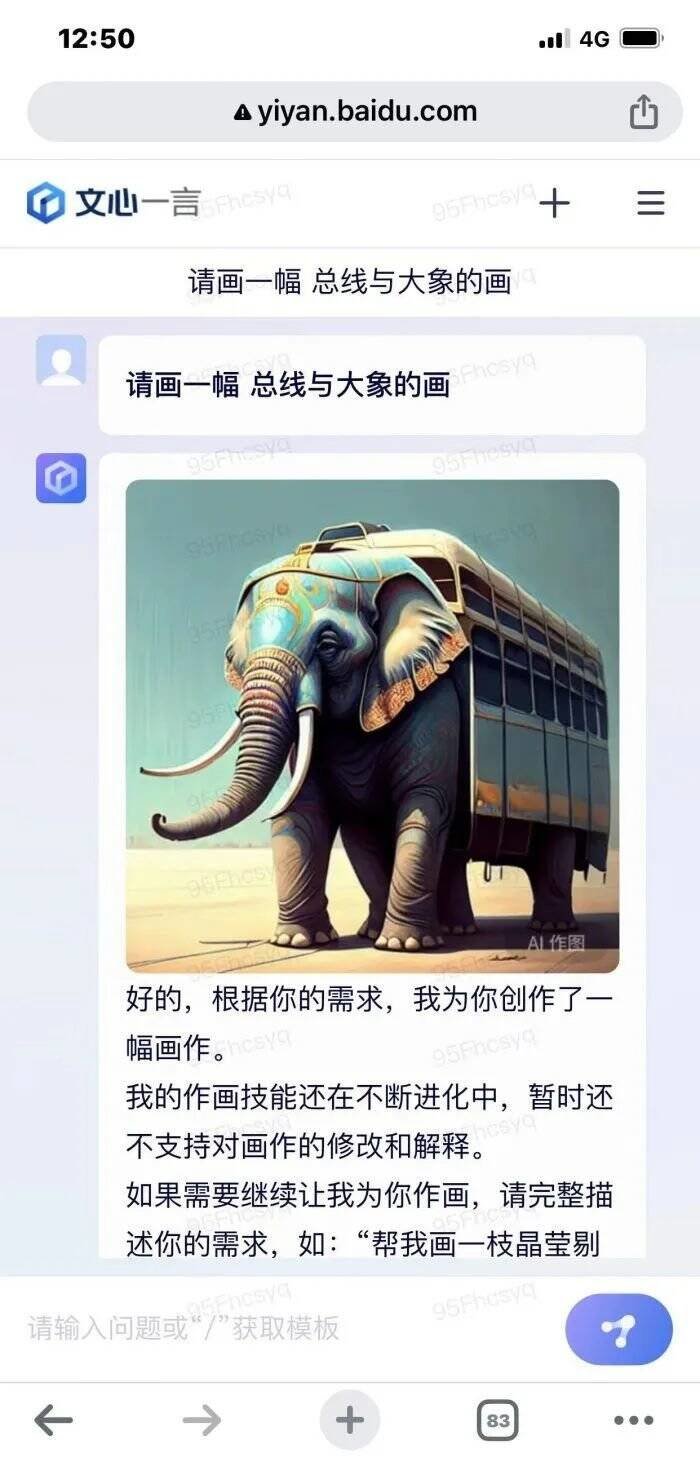
1、指令为“画一幅总线与大象的画”:生成的却是公共汽车与大象。因为“总线”对应的英文是“Bus”,而Bus的中文意思通常为公共汽车。
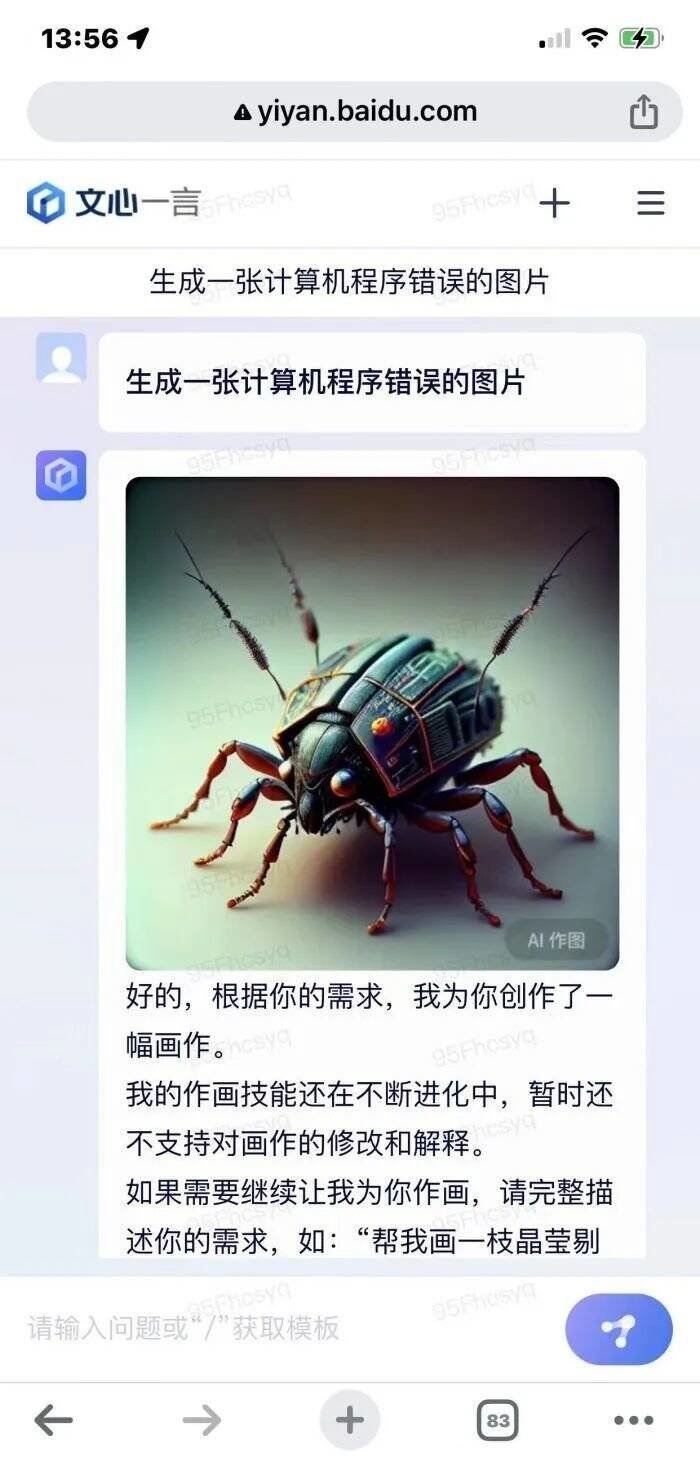
2、指令为“生成一张计算机程序错误的图片”:生成的是虫子的图片。因为计算机程序错误,用英文来说,就是有Bug,而Bug的中文意思当中就有“虫子”的意思。
因此,有网友认为,百度的文心一言可能是用了国外的开源AI模型为基础进行的二次加工后的套壳产品。
另有网友表示,百度文心一言用国外开源的人工智能Stable Diffusion生成图片,然后将其返给用户。
不过也有业内人士分析称,出现这种问题可能是因为百度使用了一些网上公开的数据集(训练的图片库),图片基本都是的打的英文的标签,如果从头来做中文标签不仅成本巨大且耗时巨大,但是这并不能证明文心一言是套壳。
对于网络上的质疑,3月23日,百度进行了回应。
百度称,文心一言完全是百度自研的大语言模型,文生图能力来自文心跨模态大模型ERNIE-ViLG,“在大模型训练中,我们使用的是互联网公开数据,符合行业惯例。大家也会从接下来文生图能力的快速调优迭代,看到百度的自研实力。”
百度表示:“文心一言正在大家的使用过程中不断学习和成长,请大家给自研技术和产品一点信心和时间,不传谣信谣,也希望文心一言能够给大家带来更多欢乐。”