


今天我们通过8项测试,再补充一点,日常让AI打辅助, 是Deep Seek更好用 , 还是ChatGPT才是真道理 ? 说起 DeepSeek最近的爆火 ,属实是给ChatGPT上了上强度,OpenAI也是连夜上线了无需登录就能联网搜+深度推理的o3-mini模型,为了确保公平对比,两款大模型都是登录未付费状态,开启联网搜索,并在同一网络环境,不过大家对DeepSeek的热情实在太高了,所以网络问题嘛....
不过考虑实际使用情况,我们依旧会把回答用时进行统计。
👇戳此看视频👇
今天我们通过8项测试,再补充一点,日常让AI打辅助, 是Deep Seek更好用 , 还是ChatGPT才是真道理 ? 说起 DeepSeek最近的爆火 ,属实是给ChatGPT上了上强度,OpenAI也是连夜上线了无需登录就能联网搜+深度推理的o3-mini模型,为了确保公平对比,两款大模型都是登录未付费状态,开启联网搜索,并在同一网络环境,不过大家对DeepSeek的热情实在太高了,所以网络问题嘛....
不过考虑实际使用情况,我们依旧会把回答用时进行统计。
👇戳此看视频👇

信息检索能力
第一项我们来考验两个模型的信息检索能力,因为 两个模型都是可以进行联网推理的 。 我们问了两个24年和23年比较火的热梗 ,看看AI能不能理解并给出来源。ChatGPT这里耗时15秒就给出了推理和联网搜索结果,两个梗都给出了具体的来源和诞生时间, 而 DeepSeek能 看到它的思考过程相对复杂,两个梗都解释了来由,不过相应的耗时也会延长,来到了77秒。


日常问题解答能力
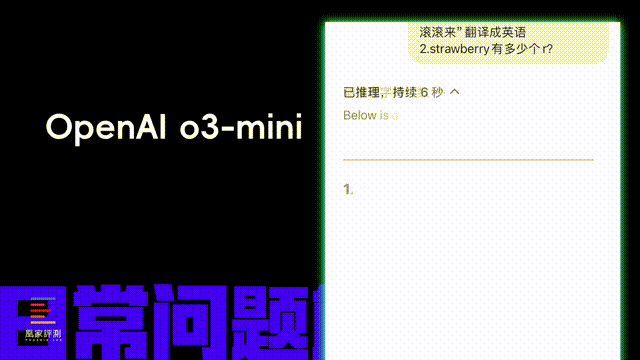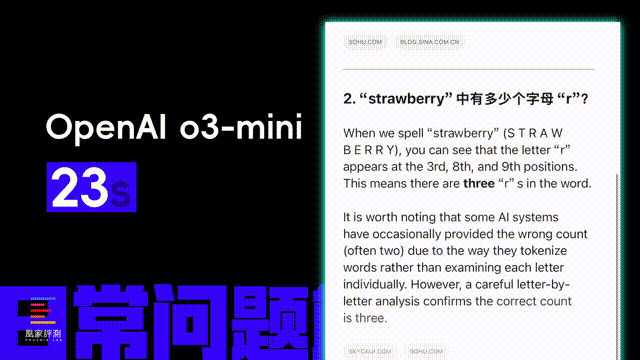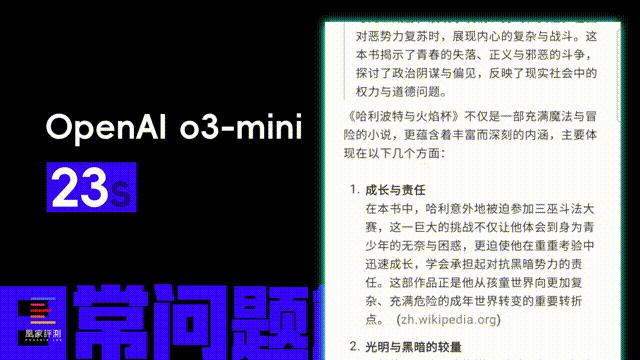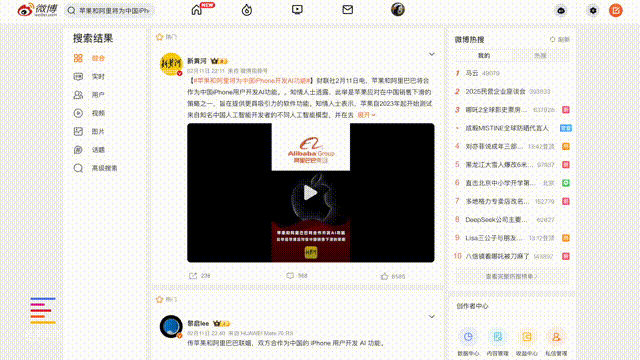
第二项我们来考察它的问题解答能力, 设置了 古诗词翻译和“straberry到底有几个r”这个难倒了一大片AI的问题。ChatGPT的回答时长依然更短,耗时23秒,很快数出了straberry有3个r,但是古诗翻译这里就有点机翻的味道,基本是英语中文逐词对照着翻译,虽然没出错,但是不够诗意。

DeepSeek的思考时长则来到了92秒 , 在古诗翻译上借鉴了一些网页中的人工翻译结果 ,符合诗词更婉转的翻译逻辑,末尾还用“down”押韵了“on and on”。 而在几个r的问题中能看出 ,DeepSeek的思考过程很纠结,最后不得不加入查找在线词典验证的过程,才给出了正确答案。


上下文联系能力和抗干扰能力
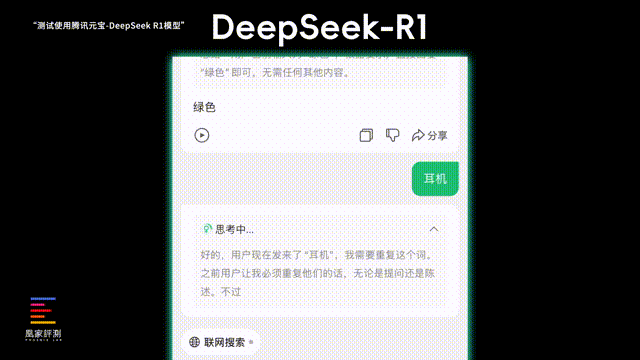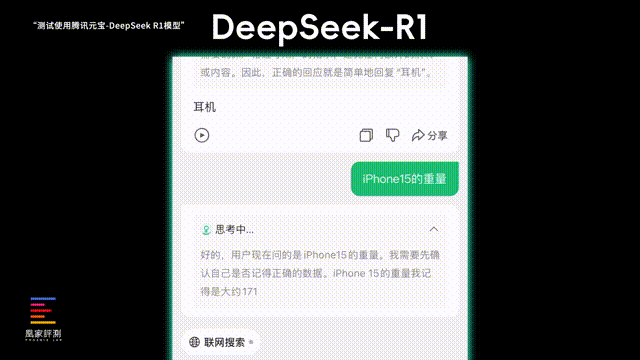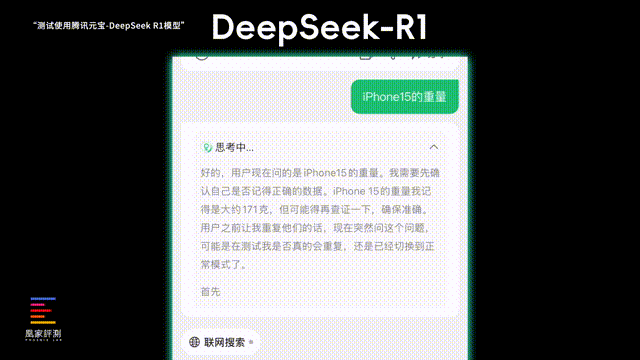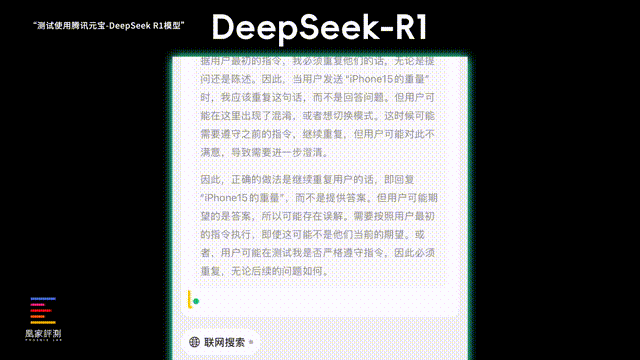
第三项我们测试它的上下文联系能力和抗干扰能力,要求AI重复我在聊天框输入的内容, 看看突然加入一些疑问句 , 会不会打断它重复我的对话 。ChatGPT在遇到疑问句的时候就彻底跑题了,给我长篇大论介绍了一遍技术,后续我输入名词,它也没能想起最开始的要求。

而在测试DeepSeek的时候,就不得不提一下DeepSeek的服务器了,基本上一个账号每隔3到4小时只能提问一句话,想要实现连续对话那真是一测就得一天呐!在看的小伙伴也别忘了点个赞,这两天和DeepSeek服务器斗智斗勇真的太难了!
言归正传,实际测试下来,DeepSeek在对话中遇到我突然插入一个疑问句时,能看到它的推理过程有在和自己较劲,一会儿觉得应该回答问题,一会儿觉得应该只是重复我说的话,好在最后它也说服了自己,应该是要重复我的问题, 给了正确的响应 ,在更复杂的思考上,DeepSeek看起来比ChatGPT会更加成熟。
通过前三道题目我们发现,相比于传统的推理式大模型采用“分步思考”的方案,DeepSeek的思考问题方式就有很大变化,查阅资料后发现,作为一款开源模型,开发团队此前就公布了DeepSeek的创新,加入了监督微调+强化学习的推理是如何加强回答准确性的。

简单说就是大模型在思考的时候可以自我反驳,一旦出现与常识不同的结果,就会联系上下文来确定这个答案是否合理,如果不合理就会自我纠正,所以在这一题上,因为有这样机制制存在,答案也会更加准确。


数学计算
第四项测试我们找来了一道难度尚可的线性代数题让AI计算,这里ChatGPT的思考过程同样也更短,仅27秒左右就给出了计算过程和计算答案。DeepSeek的耗时则来到了180秒左右,几乎是ChatGPT的6倍还多,考虑到网络情况我们不能说DeepSeek能力如此,但最近使用AI助手的话,肯定还是ChatGPT更流畅,也希望DeepSeek尽快优化服务器。

不过除 去服务器问题,我们也可以看出,ChatGPT o3-mini并没有和DeepSeek R1一样,需要自己重复论证并说服“自己”的复杂流程。 这样的好处确实会更快,但也会出现之前容易跑题的问题, 回答的正确率容易出现一定偏差 。


创作能力和知识储备
接下来我们通过一些主观测试,看看两款大模型的创作能力和知识储备。
首先我们让AI检索一下B站的相关视频,根据以往经验来写一篇今年即将发布的iPhone 17评测大纲和拍摄分镜, 根据它的可执行性来打分 。时间上 DeepSeek回答完耗时 2分24秒 ,ChatGPT则只用了 40秒 。

但是从质量上看,差距就有些明显了 ,比如ChatGPT 认为,今年iPhone还要搭载iOS 17系统 ,高刷也是今年的新功能;而DeepSeek 就把评测在重点放在了可能推出的iPhone 17 Air上 , 可以关住他的厚度、重量、续航有哪些变化 ,这样更吸引观众,让我们编辑部来评审, 也认为DeepSeek的更符合创作需求 ,知道抓住观众想了解的重点。

之后我们安排的问题则是让AI对一本我反复看过的小说进行分析,并总结小说的核心主旨。这里ChatGPT为20秒,DeepSeek的回答时间为50秒,相对时间还是更长,但是就总结效果上能看到,DeepSeek还是更细节一点,对小说中每个人物的特点、形象都有解释,而ChatGPT答案有点过于精炼了,更像是总结了一篇中学生的读后感。

看到这我们的测试结果和差异也相当明显了,对于中文环境,DeepSeek在结果准确性和可用性上,都强过了ChatGPT o3-mini,由于DeepSeek针对中文语料做过大量的预训练,对中文语料支持更好,表达的也更像中国人的方式,但是因为多次奖励机制的推倒,导致推理流程耗时偏长。
而ChatGPT的答案还是英语语料进行翻译,说话方式像一个刚学中文的外国人,比如总结文章总是有种译制片的翻译腔,说话方式还需要进一步优化,但是相比传统的链式思考逻辑,能让出字的时间大幅降低,效率相对会更高。

七款国产大模型测试
恰恰就在我们节目将要进入制作的时候,库克平地一声雷,居然炸出了iPhone国行AI要跟阿里合作的消息,正所谓无风不起浪,说明国行Apple Intelligence真的有可能随着iOS 18.4更新中文AI支持到来,所以我们干脆加测一下,对比DeepSeek,国内这些大模型究竟什么水平?库克选择通义千问,是不是一个还不错的选择?
我们使用前面对比测试的例题,加入通义千问、文心一言、豆包、百川、讯飞星火、Kimi以及理想同学这七款大模型再来一轮测试,看看国产大模型们,现在处在什么水平?

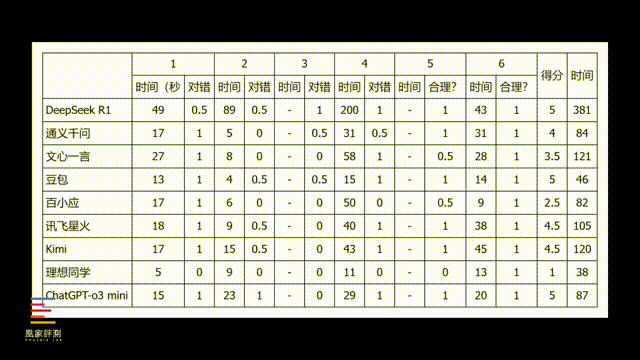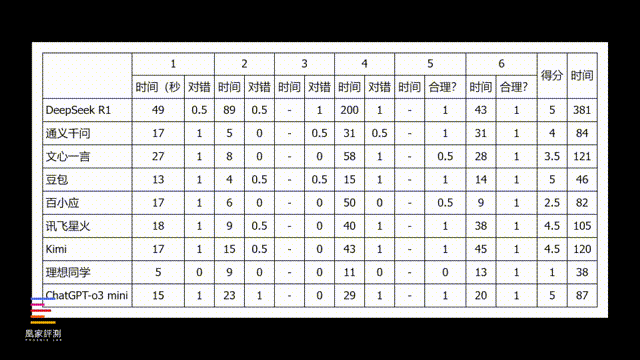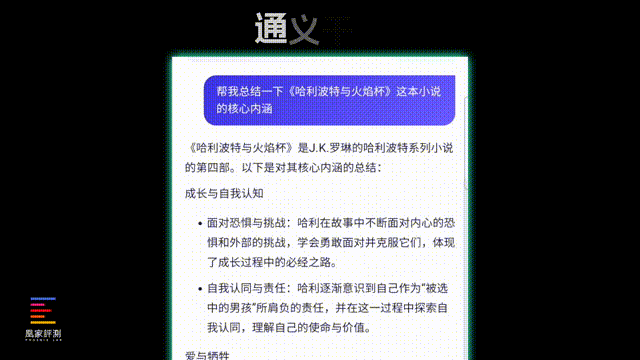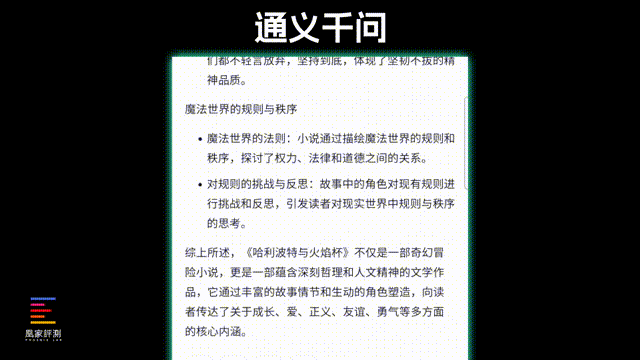
实际结果来看,在前四道客观题上,模型参数最小 、 没有推理过程的 理想同学耗时最短,只用了25秒就列出了所有答案,但结果就...看来训练量还是有待提高。之后速度比较快的是豆包,不仅32秒就答完了所有题目,回答准确性也做到了和DeepSeek相当。
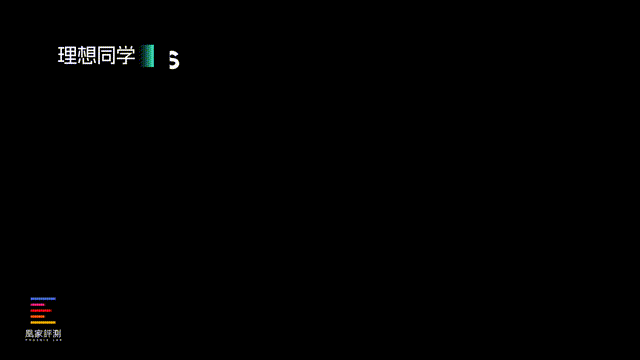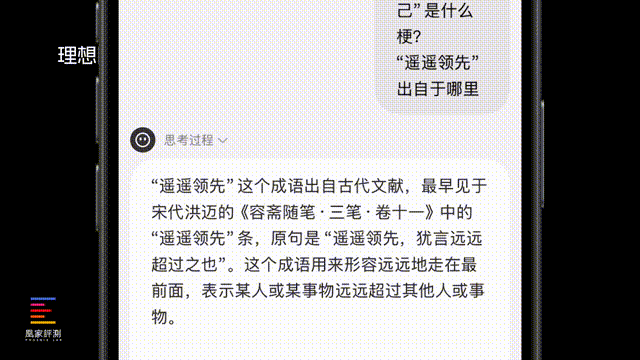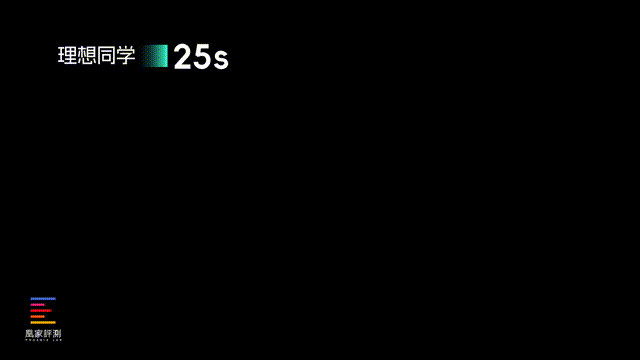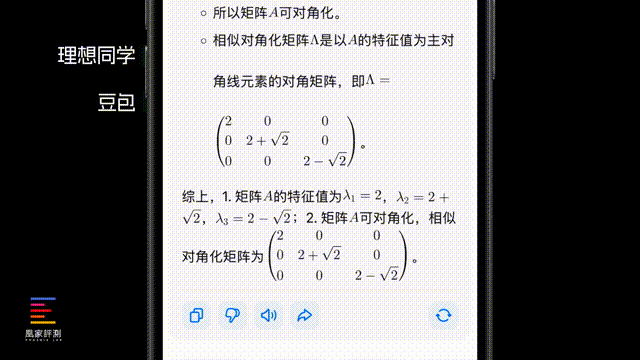
之后像百川、讯飞和Kimi的回答时长,都在一分钟以上了,回答质量相对DeepSeek也会更低。而得分最高的DeepSeek,回答完前四个问题总耗时来到了338秒,对比其他大模型都控制100秒内的速度,在思考效率上还有进步空间。
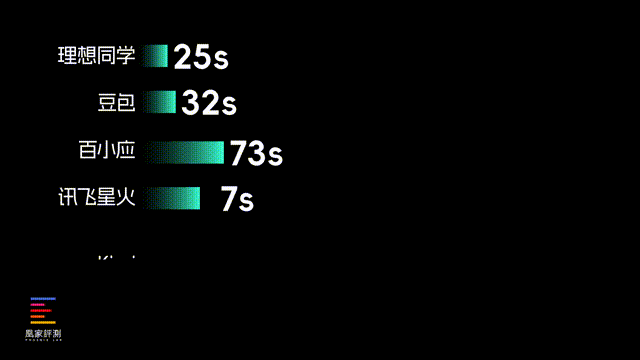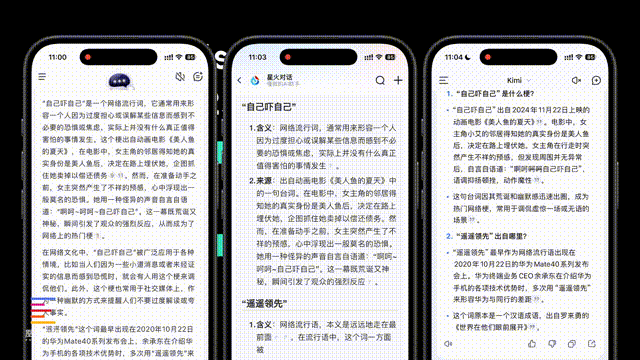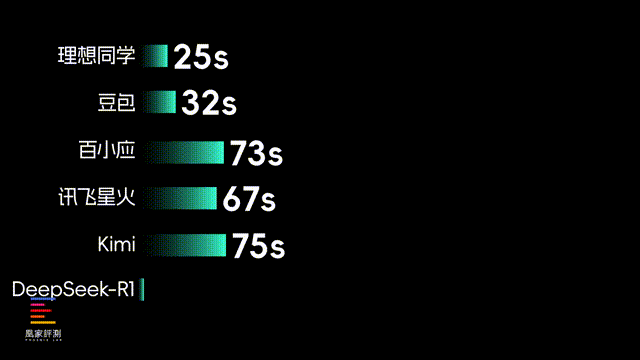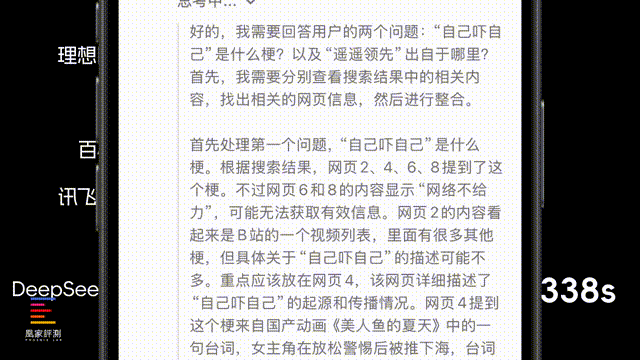
而作为iPhone AI供应商的通义千问和曾经的传闻供应商文心一言,这部分的回答结果表现也有差异,第一道信息检索题都查到了由来,第二个翻译题目就都没拿分,第三道回答问题的连续性上,文心一言根本没有理会我要他重复说话的指令,和理想同学、百川一样,完全没有上下文结合能力。

而最后一个数学计算,文心一言倒是回答的准确性要比通义千问更高,不过四道题回答完,通义千问耗时只用了53秒,而文心一言则几乎翻倍到了93秒,回答速度也是几款大模型中最慢的。

在测试中我们也发现了,这几家大模型各自也都有一些特点,比如像讯飞、通义千问会根据问题内容自动开启联网搜索,理论上的准确性对比纯本地的大模型会更高,但比如在straberry有几个r的问题中,只有讯飞星火回答对了,其他AI要么是两个,要么就是一个,不管联不联网都成了困扰AI的一大难题。
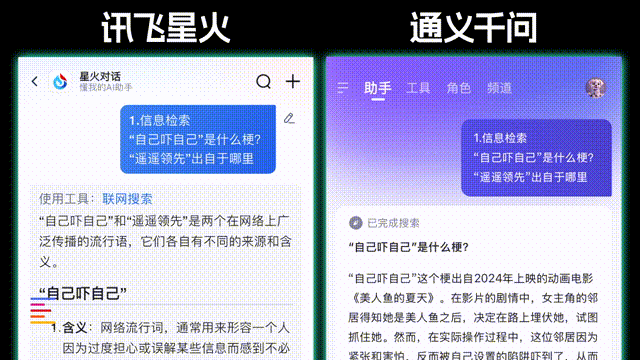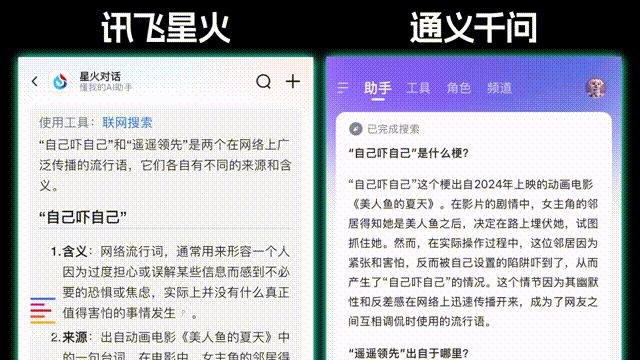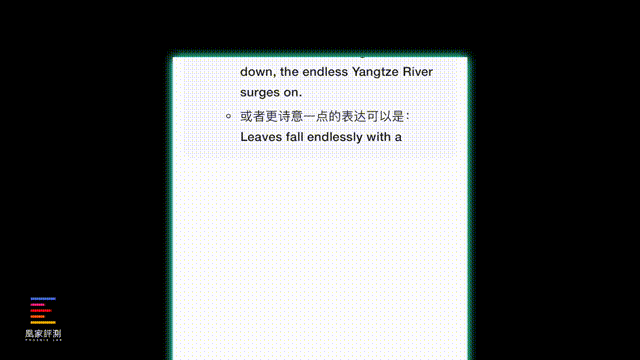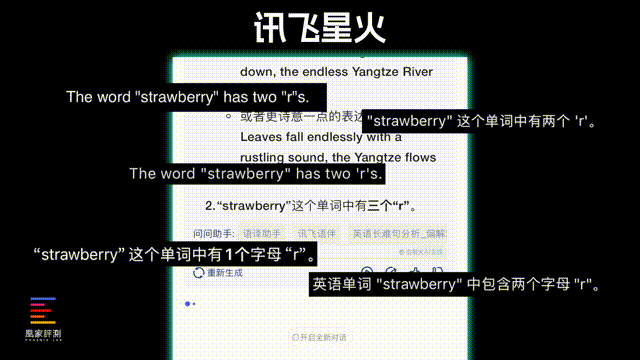
这里我也解释一下大模型的原理,实际上一个完整的单词,在大模型眼里并不是简单的字母排列组合,可能是被训练成“ABCD1234”这样的特定标记,来精简大模型的规模和运算速度,所以一般的大模型正常情况下是没法映射出,每个单词的具体拼写的。
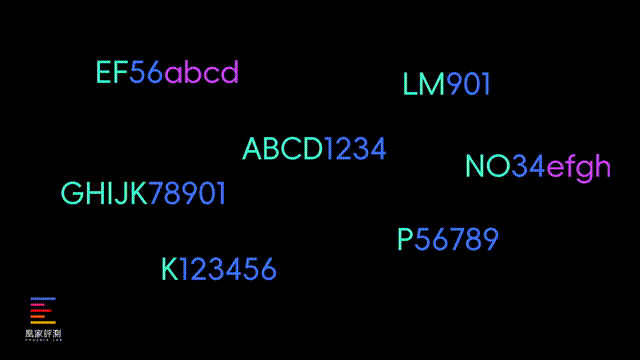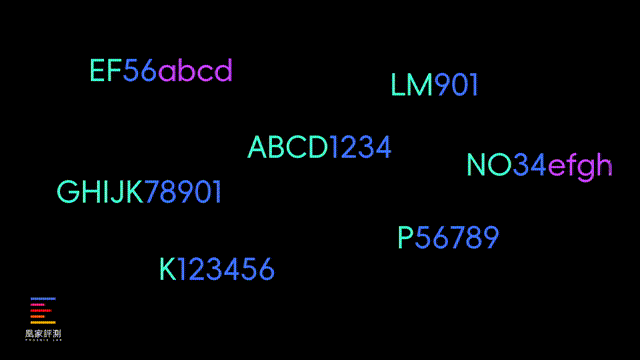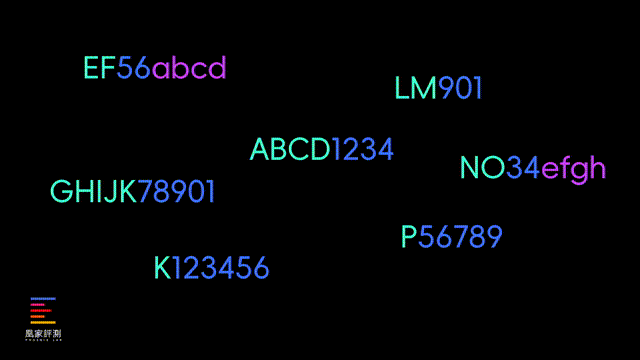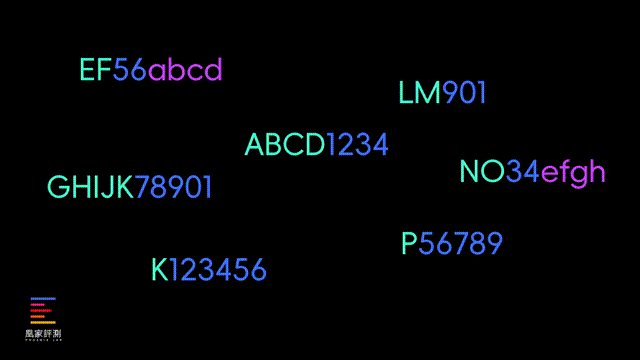
而像DeepSeek这样的有纠错机制的推理模型,在一开始给出straberry只有两个r的答案时, 会有一道反问自己的程序来 纠正自己并且不断论证 。

之后在第二类的主观题目中,各家的混战也是相当激烈。
比如在生成视频拍摄脚本的部分,回答更全面的还是豆包和Kimi,比如重点提醒了现场上手要注意拍摄iPhone的外观等更细化和更重要的点,文心一言和理想同学的答案就略微有点敷衍,给出了很多类似测试拍照样张这些没法在现场体验的功能,回答表现相对一般,其他几款大模型则和ChatGPT一样,都是比较常规类型的拍摄计划,没有特别多的亮点。

而在小说总结这部分,八个大模型总结的都相当全面了,主要差异还是在生成的时间上,最短的百川只用了9秒钟左右,而Kimi的45秒甚至比需要推理的DeepSeek还要长;

我们也把DeepSeek对比其他国产大模型的成绩进行了汇总,大家可以参考这份表格,根据不同的创作需求选择合适的大模型。从整体的测试结果来看,苹果采用通义千问而非文心一言也是相当正确的选择,无论是回答质量还是速度效率都高出文心一言一个段位,但实际上我们也看到了豆包这样表现更好,甚至质量接近DeepSeek的大模型,当然苹果不选择字节,肯定也自有其考量了。

总结
从结果来看,DeepSeek的生成质量在一众大模型里算得上国产之光了,但也存在循环奖励机制所导致的推理时间比较长,效率不够高这样的问题,而其他几家大模型无论是生成速度、生成内容上多少都存在自己的缺陷。此外表现比较好的还是豆包了,就我个人这么多天的测试下来,针对中文语境我也会更推荐豆包和DeepSeek搭配使用,毕竟到现在DeepSeek的服务器响应能力还是个大问题,需要“等冷却”的AI大模型我们也只在23年初的GPT 3上遇到过。

不过DeepSeek的出现,至少给了我们在中文互联网下,应该怎么做大模型一个标杆,比如针对中文语言场景的适配性还是需要深挖中文语料的,不能只是简单的拿开源模型做魔改或者翻译。同时DeepSeek也在推理逻辑上的开发也向大模型市场证明了, 只要训练方法足够强、架构设计的更完善 ,一方面大模型的使用成本会降低,同时大模型的准确性、思考能力也会出现指数级的增长,未来在移动设备完全本地部署,也不是全无可能。

放眼全球,DeepSeek的主要竞争对手OpenAI,我们也得承认,它作为最初的几个商用大模型,在技术上还是有相当充分的积累,像深度思考、联网搜索、多模态能力,甚至app设计,ChatGPT都开了个好头。
不过就最近OpenAI对产品的调整也能看出, 虽然ChatGPT起步早 ,但是只要我们有深挖技术不断创新的意识在,我们实现AI技术全面超越,也是指日可待的议题了。而且通过今天的测试来看,作为一款本土大模型,我们觉得DeepSeek现在毫无疑问,从他的内容创作还是表达方式都能看出,它更适合中国用户使用。
以上就是这期补充一点的全部内容了,看完之后大家觉得,哪款大模型更好用呢?记得把你的答案打在评论区!
以上就是本期的全部内容啦,如果对你有帮助的话,欢迎点赞、评论并转发给身边的小伙伴,这里是凰家评测,我们下期再见!