


SearchGPT发布刚过两天,已有人灰度测试到了。
今天,网友Kesku自制的demo全网刷屏,SearchGPT结果输出如此神速,让所有人为之震惊。

当询问Porter Robinson出了新唱片吗?
只见,SearchGPT眨眼功夫之间,即刻给出了答案「Smile」,最后还附上了链接。

再来看移动版本的回答速度,回答延迟几乎为0。
评论区下方,震惊体铺屏。

但另一方面,OpenAI当天放出的官方演示,被外媒《大西洋月刊》曝出其中的问题。
在回答「8月在北卡罗来纳Boone举办的音乐节」的问题时,SearchGPT竟弄错时间,出现了幻觉。
说好的,要取代谷歌呢?
1
全网一手实测来了
Kesku自己测试的另一个demo,呈现了SearchGPT的小部件。
她发现的一个现象是,SearchGPT倾向于强烈关注搜索结果。
「有时就需要明确告诉它,自己想要做什么,而不是想从网上得到什么」。

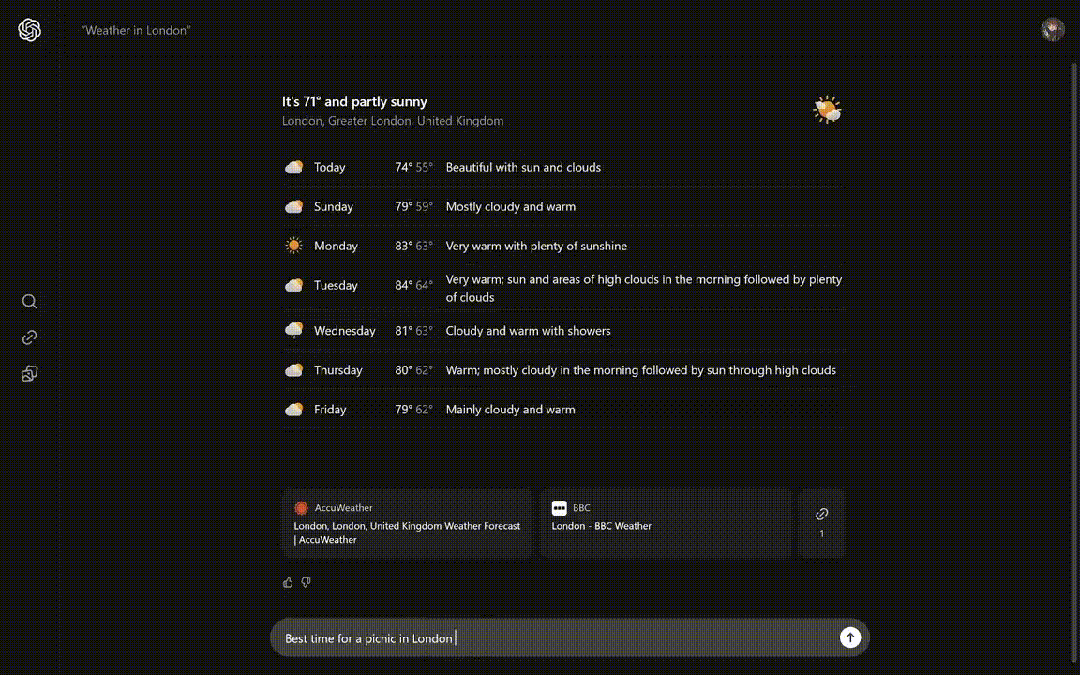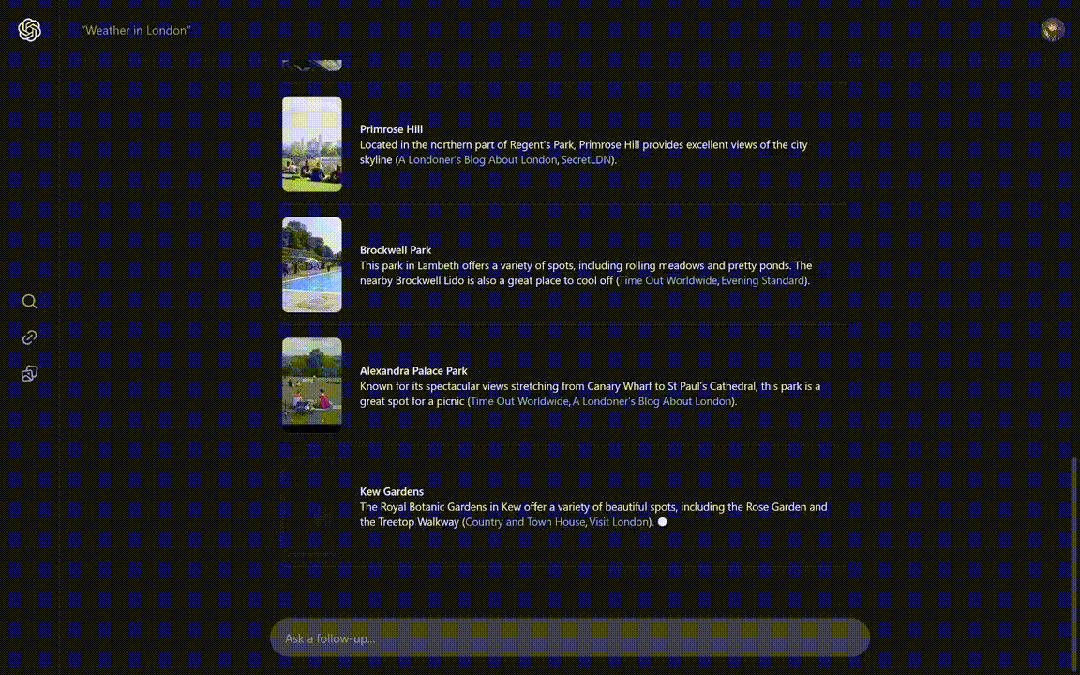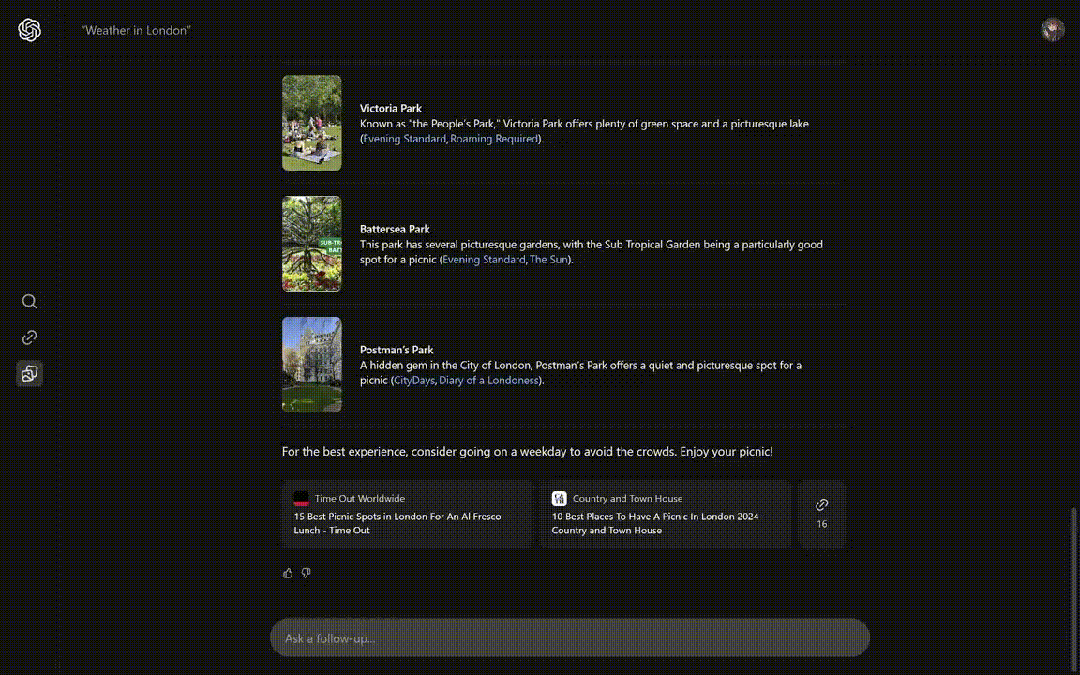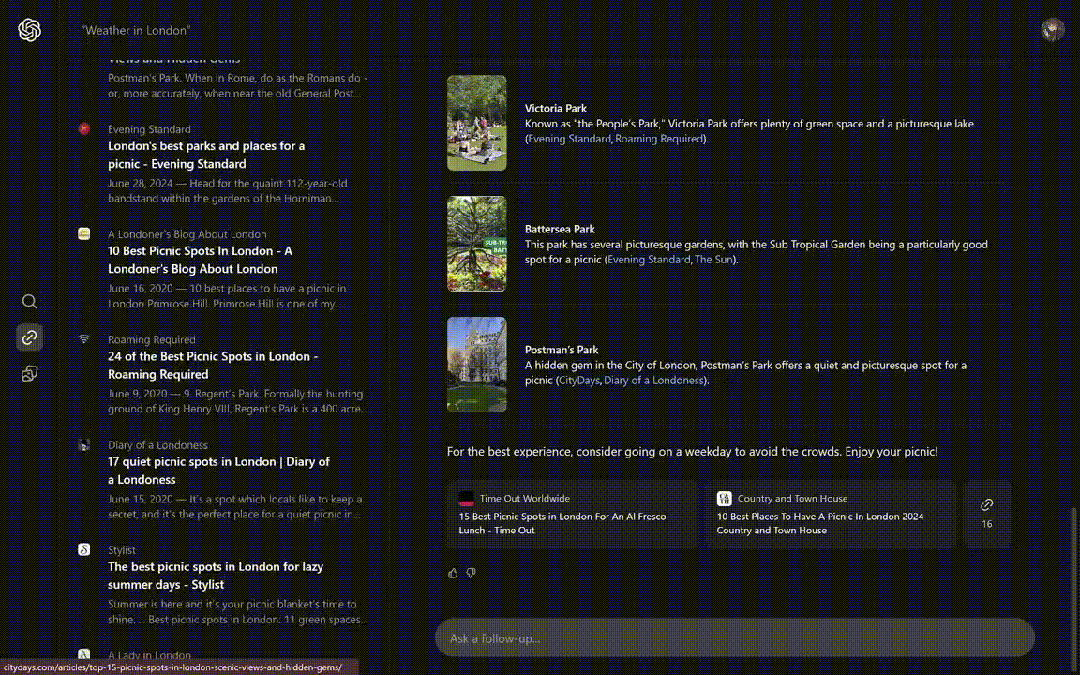
比如询问它伦敦天气,SearchGPT先给出了未来七天的天气预报。

在伦敦野餐的最佳时间和地点有什么,类似小部件的形式给出了几个备选项。
Kesku还在移动端测试了一些例子。

查询英伟达股票,会给出英伟达股票整体的可视化图,随后给出了一些分析。所有股票信息都被无缝集成在页面中。

输入一首歌名「Never Gonna Give You Up」,然后直接给出了YouTube歌曲视频,不用跳转到其他网页,在一个页面就可以听歌、看视频。

除了搜索功能,网友还乐此不疲地进行「人性化测试」——
「你怎么样」?
「作为一个AI语言模型,我没有感情,但我在这里并随时准备帮助你解答问题。今天我能为你提供什么帮助」?

「给我讲一个笑话」
一个英语世界的经典双关梗就此出现——
「科学家不信任原子。为什么科学家不信任原子?因为它们构成了一切!」

网友现场出题
眼馋的网友们,纷纷在评论区出题,让帖主帮忙测试。
第一位网友问道,「它支持地区和新闻吗,比如来自TestingCatlog的最新新闻」。

Kesku测试后表示,「它可以通过IP地址或精确位置为你提供本地信息(后者默认是关闭的,可以在设置中选择开启)——比如『我附近的电影院』这样的查询效果很好」。

「帮忙试一下其智能体搜索的解释能力」。

SearchGPT在给出关于高带宽存储器的解释中,蓝色标出的内容,是参考解释。


你能尝试搜索一些付费墙后面的文章吗?那些最近与OpenAI签署了合作伙伴关系的文章。

Kesku给出了一篇文章的内容, 不过貌似还是不能越过付费内容,仅是给出了文章的总结。
更细节的内容,依旧无法看到。

你能尝试搜索「Yandex月活跃用户数」吗?
我想看看,当它找不到我想要的确切答案时,它是否会承认自己找到了日活跃用户数(DAU),而不是月活跃用户数(MAU),还是会像copilot那样装糊涂,只是复制粘贴整个搜索结果而忽视实际查询。

Kesku搜素后的结果如下所示:
显然,根据提问者问题,SearchGPT给出了回答。

「与Perplexity相比如何」?
Kesku称暂时还未测试复杂的任务,不过非常喜欢目前测出的结果。

在下面提示中,她直接问道「谁是Kesku」这么小众的问题。
没想到,SearchGPT给出了正确的解答,Perplexity却回答错误了。


有网友对此评价道,「很酷的演示!也许SearchGPT能在本地搜索领域带来一些变革?它能帮助你在现实世界中完成事情。从外观来看,它有很好的数据源、简洁的小部件,而且速度超快。不知道与谷歌相比,他们能把每次查询的成本降低到多少」?

1
揭秘SearchGPT搜索机制
科技媒体TestingCatolog也率先进行了内测,并揭开了SearchGPT搜索机制的一角。

与当前ChatGPT提供的通用Bing搜索功能不同,SearchGPT更擅长提供实时信息。
虽然仍旧依赖Bing的索引,但SearchGPT将会有自己的网络爬虫(类似Perplexity),用于动态获取实时数据,从而克服Bing速度较慢的问题。
甚至,TestingCatalog还挖出了SearchGPT的源代码,并在评论区信誓旦旦地表示「绝对准确,我有内部人士。」

源代码不仅露出了Bing的接口,而且可以发现,搜索结果由多模态模型提供支持。
虽然看不出其中具体的处理流程,但调用的模型应该具有自动理解图像的功能。

1
官方演示大翻车,OpenAI惨遭打脸
就在网友们兴致勃勃地试用时,《大西洋月刊》却站出来泼了一盆冷水——SearchGPT在官方demo中有明显的搜索结果错误。
用户给出的搜索问题是「8月在北卡罗来纳Boone举办的音乐节」。

这个问题其实很难体现SearchGPT相对于传统搜索引擎的优势。同样的问题如果抛给谷歌搜索,也能给出相差无几的结果。
比如SearchGPT放在首行的「阿巴拉契亚夏季节」(An Appalachian Summer Festival),也同样是谷歌搜索的第二位结果。

但尴尬的是,标题下方的AI摘要把一个关键信息弄错了——经主办方确认,音乐节举办日期为6月29日~7月27日。
如果你按照SearchGPT给出的信息去买票,将一无所获——7月29日~8月16日恰好是售票处正式关闭的时段。

OpenAI发言人Kayla Wood已经向《大西洋月刊》承认了这个错误,并表示「这仅是初始的原型,我们将不断改进。」
这个错误让人不禁想起Bard曾经造成的惨剧。
2023年2月,谷歌推出了这个聊天机器人产品以对抗ChatGPT,但首次亮相就出现了事实性错误,导致Alphabet股价当天暴跌9%,市值瞬间蒸发1000亿美元。

Bard称James Webb太空望远镜拍摄了系外行星的第一张照片,但实际上这个功绩属于欧洲南部天文台的VLT
但好在,OpenAI没有股价可跌,而且仅开放内测的做法也是相当谨慎。毕竟有谷歌的前车之鉴,可以预料到,LLM这种错误几乎是无法避免的。
即使OpenAI能够找到方法大幅减少SearchGPT的幻觉,但面对庞大的访问量也是「杯水车薪」。

假设幻觉率仅为1%(这个比率很难达到),按照谷歌的规模,也会导致每天产生数千万个错误答案。
更何况,我们目前还没有发现足够可靠且有效的方法,来消除LLM的废话和幻觉。
而且,Andrej Karpathy大佬曾经在推特上表达过这样的观点:「幻觉并不是bug,而是LLM最大的特点。」

Karpathy将LLM比喻为「梦想机器」:我们用prompt引导模型「做梦」,再加上对训练文档的模糊记忆,就得到了生成结果。
虽然大多数时候生成结果是有用的,但既然是「梦境」就有可能失控。当LLM做梦进入有事实错误的领域时,我们就会给它贴上「幻觉」的标签。
这看起来是个bug,但LLM只是做了它一直在做的事情。
这种机制和传统的搜索引擎完全不同。后者接收提示后仅仅是逐字返回数据库中最相似的文档,因此你可以说它有「创造性问题」,因为搜索引擎永远不可能创造新的回应。
根据Karpathy的说法,我们就很难指望由当前LLM驱动的AI搜索能生成100%真实准确的结果。
那么这场搜索引擎的变革会怎样展开?LLM的「梦境创意」和传统搜索引擎的真实可靠,究竟是共存下去,还是会「你死我亡」?
