3月18日,前VC投资人庄明浩在朋友圈转发了三段文章片段:百川“断臂”医疗To B,零一万物明确不做万亿规模超大参数模型,以及朱啸虎称金沙江的LP们非常感谢他没有在基础模型公司上浪费一分钱。庄明浩的转发配文是:“或许旁观者可以笑看,但如果你身在其中呢?”
目前来看,“身在其中者”纷纷调整船头,以“AI六小龙”为例,明确掉转船头的是退出“超大基模”烧钱赛的零一万物、聚焦医疗方向的百川智能。剩余“四条龙”中,智谱与阶跃星辰分别背靠北京市与上海市政府资源推进项目进展,Minimax在海外市场与视频领域较为稳定。月之暗面受到DeepSeek冲击较为明显,QuestMobile 1月数据显示,当月DeepSeek 日活(DAU)超越豆包,Kimi 退居第三,且用户增速明显放缓。
DeepSeek的技术革新与成本降低拉动行业“技术平权”,一方面冲击大模型原有格局,一方面拉动算力聚焦推理端,带动大模型应用的繁荣。全球投资机构a16z3月发布的AI产品流量TOP50榜单中,Web端排名前五十名里,中国共有19款产品入榜,占比升至38%。去年8月的榜单中,中国市场仅有8款产品上榜。同期美国AI产品的数量从33款降至23款,占比降至46%。
当训练端技术代差缩小,算力压力得到一定程度的缓解,开源市场助推创业者想法落地,中国市场在产品端的优势得以凸显。而原本占据行业头部位置的竞争者们,亟需调整方向,补充弹药,备战新一轮大模型幸存者挑战赛。
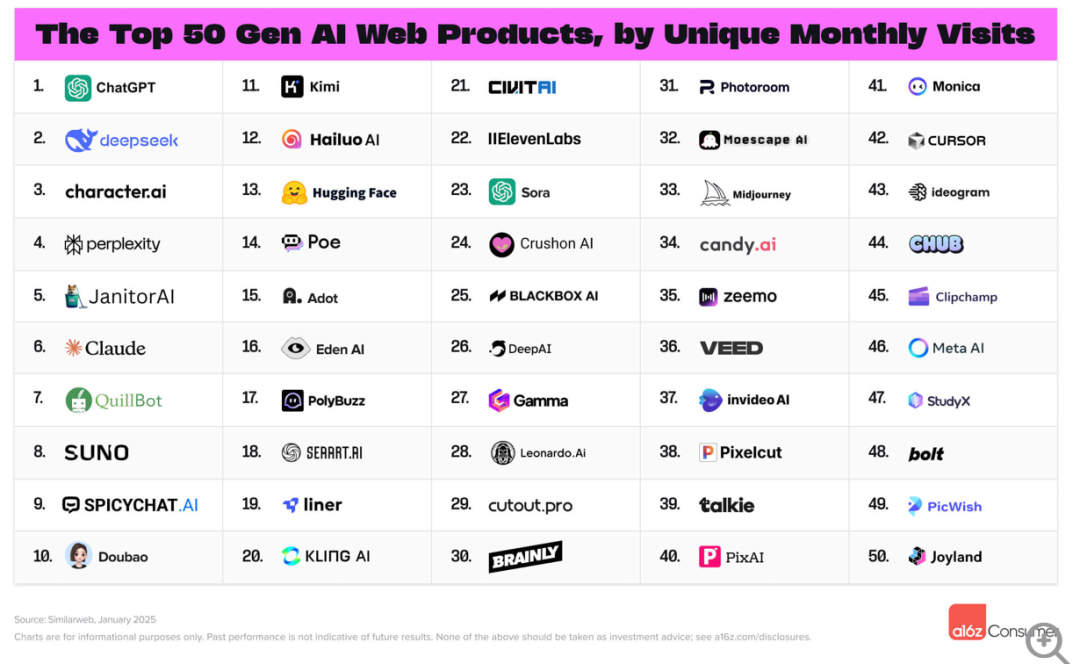
a16z榜单Web端TOP50
DeepSeek之后基模还有意义吗?
DeepSeek的爆火之所以直接冲击了原本的大模型格局,核心原因在于DeepSeek-R1模型在更低成本与开源生态的基础上,在多个关键任务上展现出与国际顶尖闭源模型相当甚至更优的性能。此外,DeepSeek采用的强化学习技术和混合专家架构(MoE)等技术也提高了模型的推理能力和效率。
另外,不同于多款模型有限度的“伪开源”,DeepSeek将模型架构、训练方法,以及数据处理方案完整公开,彻底的开源策略吸引了全球超过20万开发者参与生态建设,衍生出医疗、金融、教育等垂直领域的定制模型,直接冲击了传统大模型厂商依赖高昂授权费用与闭源模式来盈利的途径。
但目前市场上对DeepSeek是否彻底颠覆基座大模型市场与Scaling Law(扩展定律)仍有不同声音。在坚定的应用派朱啸虎看来,目前市场已经没必要去关注传统“AI六小龙”了,创业公司做底层模型已经毫无意义。他称,自己一开始便认为基础模型会成为水电煤一样的这种通用的商品服务,但没想到会这么快,并且以这么剧烈的方式。
大洋彼岸的英伟达也因DeepSeek的热度而一夜暴跌近六千亿美元,投资者主要担忧DeepSeek的技术突破可能会降低市场对英伟达昂贵硬件的需求,特别是其高端GPU。在刚刚结束的GTC大会上,英伟达创始人兼CEO黄仁勋回应该疑问时称:从两年前的ChatGPT到如今的推理机会,AI Scaling Law并没有消失,而是从一个变成了三个——预训练扩展、在代理人工智能(Agentic AI)阶段的后训练扩展,以及针对推理模型的扩展法则。其中推理(inference)实际是计算的最终难题。他认为,去年全世界对Scaling Law的预测都错了,如今的算力需求已比去年预估的规模高出100倍。
然而,大会当日英伟达收跌3.4%,华泰证券分析师认为,此次GTC上,虽然公司也提出了后训练Scaling和测试时间Scaling的叙事,但从英伟达当天股价表现上来看,此次GTC或未能打消投资人在算力需求增长方面的担忧。
第四范式创始人戴文渊对记者表示,DeepSeek给全行业提供了一个更好的基座,给全行业带来巨大帮助,更大的推动意义是推动深度推理方向的出现,帮助中国AI产业减少在预训练环节面临的限制。当更多算力聚焦在推理端,整体技术与性能上也追上来了。
但不能因为更多算力聚焦推理端便否定训练端的意义。戴文渊打了比方:训练端就像考前刷题库,推理端就像考试时的具体思考,如果平时没有好好做题,就需要在考试时多思考。只是对于国内市场来说,训练端确实会面临算力的压力,所以当行业进入推理周期后,对原有的基座大模型产生了影响。

英伟达强调Scaling Law三条曲线
“六小龙”转向
对于Scaling Law的辩论虽然尚未停止,但更多算力资源倾斜推理端渐成事实,投入大量资金押注基座摸底的厂商主动或被动地调整业务方向。
最新的动态发声中,零一万物创始人李开复回应第一财经等媒体时称:公司未来不再做单一大模型,而是采取模型开放策略,研发能够兼容适配国内主流模型的产品,转型之后,零一万物从基座大模型重投入调整为软硬件解决方案提供商,不再训练万亿参数规模的超大基模,但仍会继续做轻量化模型。
另外便是百川智能调整业务方向:优化金融业务,聚焦医疗To B赛道。对于金融业务的收缩,百川官方对记者回应称:百川正按照既定规划,对金融业务进行优化调整,以集中资源、聚焦核心业务。
据记者了解,百川自2024年便逐步缩减对预训练大模型的投入,今年将逐渐加大对医疗增强大模型的倾斜。AIGCLINK发起人、行行AI合伙人占冰强对记者表示,目前AI六小龙各家基因不同。其中百川相较其他厂商,医疗赛道反而是其优势行业,因王小川在创业搜狗搜索时,积累了大量医疗行业的客户。从整个AI领域来讲,占冰强认为,发展已不能仅仅参考厂商开发能力,还要具备各种商务能力,目前百川的医疗商务资源是一项优势。
3月20日,百川智能与北京儿童医院、小儿方健康共同发布全球首个儿科大模型“福棠·百川”儿科大模型。技术的落地目前对百川不成问题,但市场份额的争夺仍面临严峻挑战,尤其目前行业多家企业已开始侧重医疗方向。如华为组建医疗卫生军团、聚焦医疗大模型临床落地,科大讯飞控股子公司讯飞医疗推出讯飞星火医疗大模型,腾讯与迈瑞联合开发“启元”重症大模型,多家医院宣布接入DeepSeek大模型。
另外,资金压力也是医疗场景需要考虑的重点。目前部分医院缺乏高性能计算资源(如GPU)和高速网络连接,难以满足大模型的算力需求;医院内部对数据管理严格,限制了数据的共享和调用;医疗领域对错误的容忍度极低,医疗大模型需要达到极高的准确率才能在临床场景落地,多数医疗模型还停留在合作试水的阶段。因此相较金融、营销、社交娱乐等场景,医疗并不利于初创公司缓解资金压力。
不同于其他厂商进行业务层面的收缩,智谱通过加快拿单与融资速度的方式缓解资金焦虑。仅在3月内,智谱便先后宣布获得杭州国资、珠海华发集团、四川成都高新区的融资,同时伴随双方项目合作协议达成。例如珠海高新区、华发集团与智谱签署合作协议,宣布联合智谱搭建首个城市级GLM大模型空间“智谱+珠海华发空间”,为珠海产业提供从技术层、平台层到应用层的全栈AI技术支持。另外,四川成都高新区合作智谱打造四川省基座大模型“智谱诸葛大模型”,同步建设大模型训练中心、研发中心及西部赋能平台三位一体的AI基础设施。
但需注意的是,如果智谱的新轮募资需要以项目进展为节点,那么公司在资金层面的压力并未从根本上得到缓解。
剩余“三龙”跟进开源方向。阶跃星辰从去年的态度审慎到今年明确加大开源力度,3月20日再次披露图生视频模型开源;MiniMax在收缩B端业务后,持续投入视频生成、视觉多模态与海外产品;月之暗面大幅收缩产品投放预算,逐渐披露在长文本与开源技术方面的进展。

DeepSeek、Perplexity和Claude月访问量变化对比
从技术追赶到产品博弈
DeepSeek影响之下的行业格局会走向怎样的分化,不同位置的人士给出不同表达。
朱啸虎认为,未来基础模型的竞争格局内,大厂中只会留下阿里、腾讯、字节这三家。在他看来,阿里通义千问本身布局非常好,也有开源模型;腾讯在基础模型上原本是落后的,但因为全面拥抱DeepSeek,反而一下子赶上来了;字节目前投入很大,并且对自己的AI能力很有信心。至于创业公司,朱啸虎认为必须找到自己的根据地,才有机会异军突起,但从现状来看,他认为还没有看到能够颠覆阿里、腾讯、字节的万亿美元机会。
李开复结束业务调整之后,也表达了对大模型格局的看法。他认为中国大模型格局很大概率会收拢到三家——DeepSeek、阿里巴巴和字节跳动,理由是他们的模型会随着时间不断迭代进化,其中DeepSeek 目前最具势头。至于其他基模平台,李开复认为,吸纳大量资金训练的基座模型开始趋近同质化,它们成本高昂,越来越难和开源技术竞争。
如果将眼光聚焦在中美两地的AI格局,李开复认为,中美市场中的超大模型预训练正在逐渐寡头化,并且寡头化的程度在不断加大,其中开源圈展现出压倒性的优势。美国市场中,OpenAI 和 Anthropic 都相信自己还能训练出远超其他玩家的闭源模型。但从结果来看,OpenAI 在2024年的运营成本为70亿美元,而DeepSeek的运营成本可能只有OpenAI的2%。
从技术层面来讲,各家模型各有优势,李开复认为的核心痛点并非哪家模型在性能上能够较其他模型高出1%,而是模型路线本身是否具有可持续性。例如OpenAI每年花费 70 亿美元,面临巨额亏损。但现在出现了一个竞争对手,将成本低廉数倍的开源模型免费开放给市场,且这个竞争对手资源充沛,目前看来 DeepSeek 有足够的资金储备持续投入模型研发,并已经有效地将计算成本降低了五到十倍。“有了这样一个强大的竞争对手,我认为OpenAI的萨姆·奥尔特曼可能夜里辗转难眠。”李开复表示。
奥尔特曼也在调整动作。近期,在对外采访中,奥尔特曼对DeepSeek的爆火进行了反省,他认为是OpenAI对“思维链”的隐藏留给了其他人病毒式传播的机会,这也是一次很好的警醒,未来GPT5可能免费。
OpenAI最近的更新越来越多地聚焦在产品端,包括API更新、发布语音转录和语音生成AI模型等,这也符合奥尔特曼“产品套件”的策略,奥尔特曼认为如果执行出色,未来五年,OpenAI将拥有一系列数十亿用户规模的产品。但一位聚焦Agent领域的创业者对记者表示,OpenAI的产品做得“一般”,相较于技术层面的原始创新,中国创业者在产品端拥有更多的成功经验,而这也将成为DeepSeek推动技术平权之后,中美新一轮的竞赛场。
值班编辑:夏木