


文/凤凰新闻客户端荣誉主笔 唐驳虎
前面4篇,讲完了用一两句话总结就是: 流行病学调查(简称“流调”)19世纪靠“猜”、20世纪靠“找”、21世纪靠“算”。
19世纪是马车、20世纪是汽车,21世纪是高铁、飞机、火箭。 其他领域如此,生物领域更是如此。 现在,我们要坐着飞机和火箭,从正确的起点出发去找了。

传统流调的贡献与极限
综合各媒体的报道,12月底,在武汉中心医院、新华医院(中西医结合)等医院,指示病例(Index Case)几乎同时爆发,各医院的6~7例非典型肺炎病例,都被尽职尽责的医生们注意到,并立即上报,拉开疫情序幕。
随后,各医院的医生,又在本院病例库里,追踪了本单位原发病例(Primary Case),找到了更多12月发病的病例,并描绘成曲线。

目前临床库里追踪到最早的病例,分别是12月初的华南果品市场摊贩、12月初附近小区常年瘫痪卧病在床的老年痴呆患者。 显然,这些还都不是真正意义的“原发病例”。
如果公共卫生调查力量介入,在去年11月的武汉,理论上有可能找到所谓的“1号病人”——按流行文化和热门网文的定义,大致是人类世界里第一个患病的患者。
但想找到严格意义的“0号病人”——按流行文化和热门网文的定义,大致是人类世界里第一个被动物感染、但却没有生病的患者。 然后又是他把病毒传播开来,最终产生了“1号病人”的感染-传染者 ——但这是不可能的。

从疫情发生到现在,武汉市中心医院急诊科主任艾芬,带领着近200人的团队,50多天不下火线,日夜坚守在发热门诊、留观病房(武汉广播电视台)
因为现在大家都知道了无症状感染者、病毒潜伏期的概念。 无论你找到谁,你怎么证明,在他/她之前的1~2个最长潜伏期(14~28天)内,就一定没有别的疑似病例、没有无症状感染者? “会不会还有上家”? 这没法证明。
而且,由于当时的患者已经治愈、自愈或者病亡,做核酸检验已经是过去式。
就是做最灵敏、有记录的血清抗体检验——现在武汉好几万病愈患者、自愈的轻症患者、无症状感染者,如何确定感染时间先后?
如何确定谁是去年11月而不是今年1月不知不觉感染上的“无症状患者”? 现在也完全区分不开了。

所以,传统流调的追溯极限大概就是这里了——它提供了病情溯源的起点。
但要继续局限在这个办法里“找”,那就是驾马车钻死胡同。 如前所述,蠢得冒烟的行为。
要不仅掌握病毒在人类世界流传的“今生”,还要了解病毒之前在自然界演化的“前世”,必须用21世纪的分子生物学、生物信息学。
因为,在病毒序列里,记载着病毒传播演变的全部身份、历史。 也正如钟南山老先生所说,必须要靠“溯源”。

溯源工作的三个目标
溯源工作的基本工具,以前已经讲过很多次了,就是基因测序(“测”)和生物信息学(“算”),最重要的分析手段,就是演化树定位。
这些都是全世界生物学界公认的基本标准,现代生物学的基础地基,也是实验室最常规的手段,而不是什么科学前沿。 说白了,中国懂,美国也懂,俄罗斯也懂,一般国家都懂,所有的生物研究者都懂。

现在一台测序仪每天可完成 60 人的全基因组测序,把 60 个人每人 31.6 亿bp这么复杂的生物DNA全部测出来。 新型冠状病毒只有不到 3万bp的单链RNA,不到一个人10万分之一的数据量,在现代基因测序技术面前如同裸奔一般。

以前没有基因测序,各种阴谋论还真不好反驳。
但有了基因测序技术之后,全序列清清楚楚,都袒露在全世界面前。
病毒的变异、留痕,都是公开透明的、可以追查的。 不认可的国家、专家可以自己调查研究,样本现在全世界都有,只是发出来的报告不要被全世界沦为笑柄就好。

溯源工作至少有三个主要层面:
1、研究病毒如何从动物进入人体; 搞清楚它从天然宿主到人类世界的路径,通过什么中间宿主,发生了什么基因变异、重组,最后在什么场景下传入人类世界。
2、研究病毒在自然世界的演化史(“前世”); 在自然界演化过程中,病毒的特性是否发生了明显的定向的变化。
3、研究病毒在人类世界的传播史(“今生”); 从武汉到全世界的扩散过程中,发生了什么样的变化,有没有出现传播能力和毒力的变异。
从关心程度来看,可能大部分人关注的程度是1、2、3。
但从病毒溯源的过程来看,逻辑步骤则应是3、2、1。 我们今天先来谈3。

台湾节目揭露病毒来自美国?
这两天一条“台湾节目追溯新冠病毒源头,然后追到美国去了”的视频火了。
节目中,有关嘉宾判断新冠病毒源头可能在美国的主要依据,正是前不久几位研究者在ChinaXiv论文预印本网站上联合发布的一篇论文。

也正是我早就说过——“大错特错”、“哗众取宠”的一篇论文,发表于2月21日。
四位作者分别来自西双版纳热带植物园综合保护中心、韶关大学生物农业学院/华南农业大学林学与园林学院、中国脑科学研究所。

当时就被生物业界同行评价为——做研究跨界太大,结果存疑。 当然,我们不因人废言。 但所有科研成果,都需接受专家学者的交流和讨论。

当时的网友评论 在这篇论文里,对病例、样本的命名极其混乱、拗口。 什么mv1、H38、H3、H1、H56、mv2,编号乱得要命,数字大小既不代表时间顺序,也不代表空间与逻辑顺序,真不知道怎么命名的。

(顺带说一句,就我个人的行外感受,混乱混沌的生物,跟严谨有序的物理、工程,两种学科的思维模式非常不兼容。)
这篇论文,当时就被一般读者吐槽了。 命名、逻辑颠三倒四,让人读起来、理解起来极其费劲。 神马玩意啊!

当时的网友评论
经过令人头疼的阅读,终于能理解,他们的研究方式是,选取了GISAID数据库中覆盖了四大洲12个国家的93个新冠病毒样本的基因组数据(截止2月12日),通过数据解析,追溯传染源及扩散路径。
他们研究发现,93个样本包含58种类型,可以归纳为五组。 结果他们发现,武汉居然只有三组! 深圳有另外一组,美国有另外一组。
而且美国集齐了所有的五组! 有阴谋! 大阴谋!

哗众取宠不要太过啊……
这里,我先用普通读者就能读懂的视角来解析这篇论文。 其实论文当时就承认,来自武汉的样本,取样截止日期早在1月5日之前,而全球大部分地区的样本,都是1月22日之后才获取的,当时最晚的取样日期是2月3日。

但就是这样的背景,还能得出结论——华南海鲜市场的患者可能是被传入的,不是原始来源。 因为武汉/华南海鲜市场的类型单一,而武汉/华南海鲜市场之外的类型反而比较丰富。
所以这就是论据-推论-结论。 我也是服了。

如果仔细研究数据来源,就发现研究的依据——武汉的样品完全采自早期几家定点医院,而且样品采集时间局限于12月24日~1月5日之间。
稍微有点记忆的读者就知道,当时公布的发现病例,不过是区区44~59人! 实际上就是那几家医院发现的指示病例(Index Case)而已!

而中国疾控中心2月12日所做的回顾性研究已经显示,12月31日之前,湖北已出现104名发病者(还不包括感染者);
到1月10日,已经出现653名发病者,分布在20个省份的113个县区,其中湖北占88.5%(578人)。
其他75人已经位于湖北省外的19个省。 这显示大规模疫情传播已经开始,感染者还不止这几百人。

在武汉几百个已经发病的病例中只选几十个病例,那肯定类型不全啊!
至于拿1月20日已经流散到全球、开始演化的病毒,去比较1月5日之前的少数几个集中的早期病例,那就更是关公战秦琼了! 论据选取就已经大错特错了,遑论其他。

当然,21日的这篇论文,还是承认全球包括美国早期的感染者,都有武汉旅行经历,是在武汉被感染的。 所以论文得出的结论就是,可能源头在华南海鲜市场之外,但是还是在武汉。
而之后的媒体传播,就故意隐去了“武汉旅行史”,变成了美国凭空就有了所有五组病例。
所以……这形同造谣了。

更加惊世骇俗:湖北已经是第三代?
论文还认为,美国的第一例病例,在演化树上还属于中国的“祖先”,这就进一步辅助坐实了阴谋论。 美国是“爷爷”,中国怎么是“孙子”,这不就是从美国传来的吗?

不仅如此,原论文认为广东(绿)、日本(蓝)、美国(粉红)的病例病毒是第一代,英国(灰黄)、澳大利亚(土黄)、美国(粉红)、韩国(青绿)、越南(土粉)是第二代。

原论文作者的解读
湖北(正红)病例在第二代才出现,第三代才扩散。 这真是惊世骇俗啊! 武汉是被广东、四川、云南、越南、韩国、英国传染输入的? 这不是扯地吗! 但真实的原因上一段已经说了,这里选取的湖北(也就是武汉)病例,都是1月5日前被收治的一小部分(比例约1/10)。

这是更正确一些的解读
而图上大量的外省、外国病例(1月底之前),则都是1月20日前,在武汉旅行、居住,被传染上的其他病毒子类型。
只要是专业研究者,一眼就看透问题了
且不说上面已经讲清楚的病例选取问题,我还就是一句话,你访问过他们做研究所用的数据库GISAID吗?
你只要上去看一眼,就知道他们错在哪了…… 这里先科普介绍一下,专业研究者做基因比较,最常利用的就是这么几组国际公开共享的基因数据库:

GenBank是美国国家生物技术信息中心(National Center for Biotechnology Information ,NCBI)建立的基因序列数据库。
GISAID的全称是Global Initiative of Sharing All Influenza Data(全球共享所有流感数据倡议),由德国联邦食品和农业部及其下属的德国联邦动物研究所运营。

CNBG(China National GeneBank DataBase)中国国家基因库,则是由深圳华大基因运营。
由于病毒特性,在这次疫情中,德国的GISAID国际流感数据库是各国学者上传最集中的数据库。 这个数据库最开始的时候专注于流感,后来则逐渐扩大为呼吸道传染病,及其他生物信息。

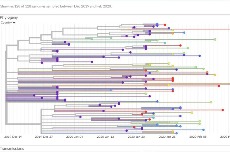
好,我们就来访问这个GISAID。 现在已经有21个国家共享了128组病毒测序数据。 从首页只需点击一下右侧导航栏,你发现了什么?

原来,GISAID已经直接把所有病毒的演化树,按时间、国家、特别是演化树的结论,直接呈现了……

GISAID的地区设色,中国大陆为深紫色,大致由近到远颜色变化,美国为深红色。
虽然中国的上传更新还是很慢,大部分序列还是1月24日之前的,外国的要快得多。 但GISAID已经把所有序列的演化关系,初步自动计算呈现出来了。

可以看出,在繁衍、变异、传播的演化树上,的确总体上是中国早期的病毒是“爷爷”,亚太的是“儿子”、欧美的是“孙子”,呈现出由近到远演化的有序序列。

说实话,对于生物信息学我只是概括了解,我确实无力演算验证。 但你要说,是最全专业数据库全自动生成的、清清楚楚的、可视化的、逻辑时间结构清晰的结果可信,还是跨界研究者手工计算、颠三倒四、令人费解的结果可信?
我当然是相信前者……

明明网络数据库直接就给出了最全、最现成、可视化的结果,谁还要你手工自己算…… 而且还算错了,算错了,算错了,算错了,算错了,算错了……

溯源3就这样在被一篇奇葩论文打乱的过程中大致完成了。 其实,还有好几篇严肃、可信的论文,然而却无人问津。

比如南方医科大学(原第一军医大学)的研究者,就把病毒由动物传入人类的时间,初步确定为11月10日左右。
结合临床回顾,这个时间点应该是可信的。 那下一步,我们就围绕这些严肃论文,展开对2和1的追踪。
10. 悲剧!新加坡要变成第二个武汉?
11. “武汉都顶不住,没人能顶得住”
